【NotionAPI】【GAS】Notionのテーブルをスプレッドシートに反映
はじめに
こんにちは!大ちゃんの駆け出し技術ブログです。
社内業務にてNotionのテーブルをスプレッドシートに連携させる実装をすることを頼ました。しかし、調べてみてもそのような記事は見当たらず、NotionAPIもGASも使ったことがなかったのでだいぶ苦労しました。ですので、こちらの記事にて実装した内容を共有しておきたいと思います。
使用技術
- GAS(Google Apps Script)
- Notion API
最終実装
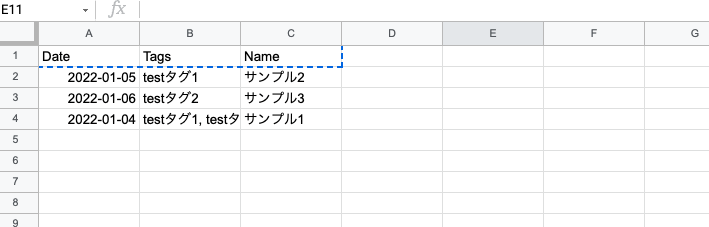
こちらの記事では最終的に下記のような実装ができるようになります。
※ spreadsheetからNotionへのテーブルの反映機能は実装していません。

↓(転記!!!)
NotionAPIの準備
まずGASを使用してNotionからテーブルの情報を取得する方法を実装します。そのための準備としてNotionから情報を取得できるように設定します。
テーブル作成
まずはNotionで適当なテーブルページを作成します。必ず自分が管理者であるワークスペースで作成してください。
私は下記のようなページを作成しました。
今回の実装ではタイトルである「Name」カラム、マルチタグの「Tags」カラム、日付の「Date」カラムをスプレッドシートに移します。
Integration secretの作成
Integrationとは?
Integrationと聞いてピンと来ないかもしれませんが、ここでの意味はNotionAPIのAppと考えていいと思います。Slack Appみたいなものです。
下記公式手順に沿ってAPIを連携させるためのキーなどを作成していきます。
Start building with the Notion API
- https://www.notion.so/my-integrationsにアクセス
- 基本情報を入力
- 「送信」をクリック
- 遷移したらトークンをコピーして控えておく

テーブルに連携
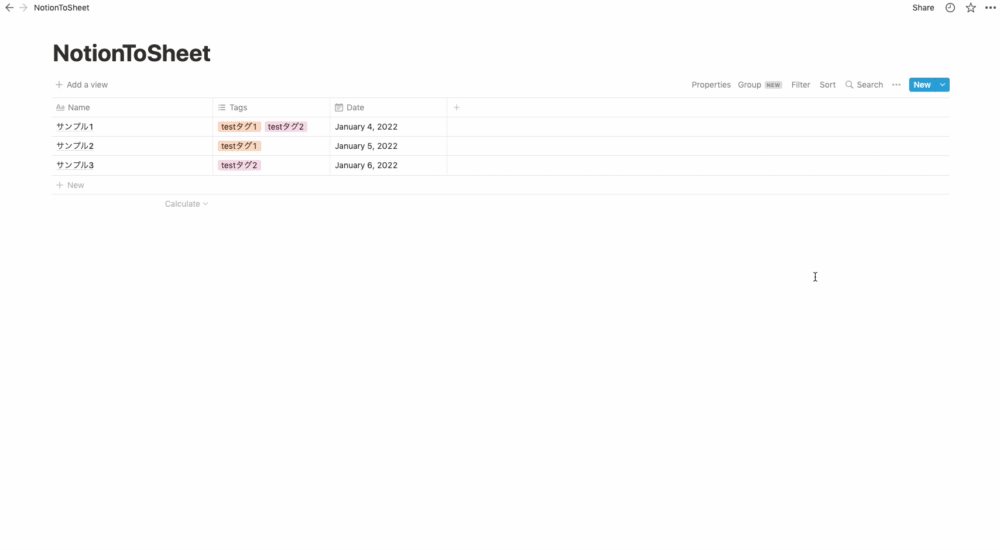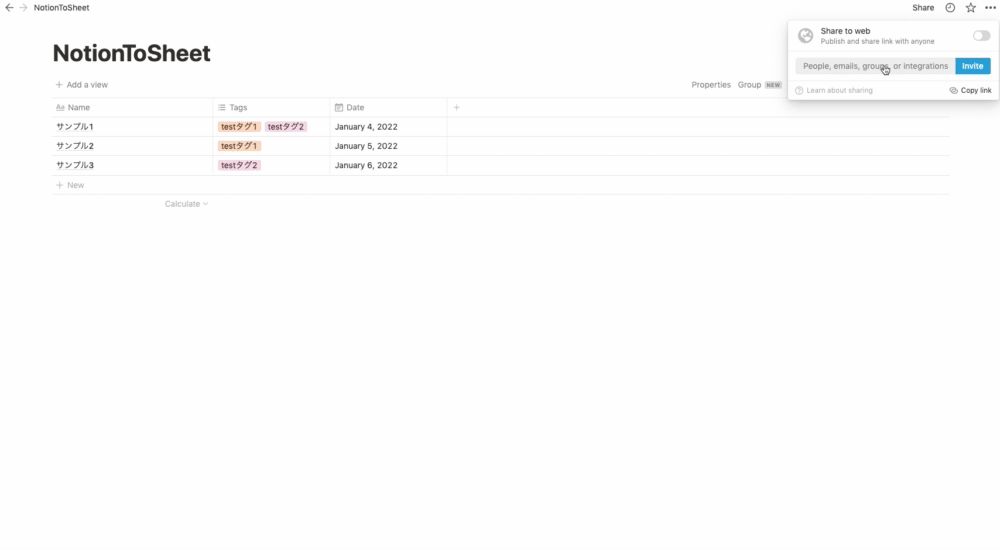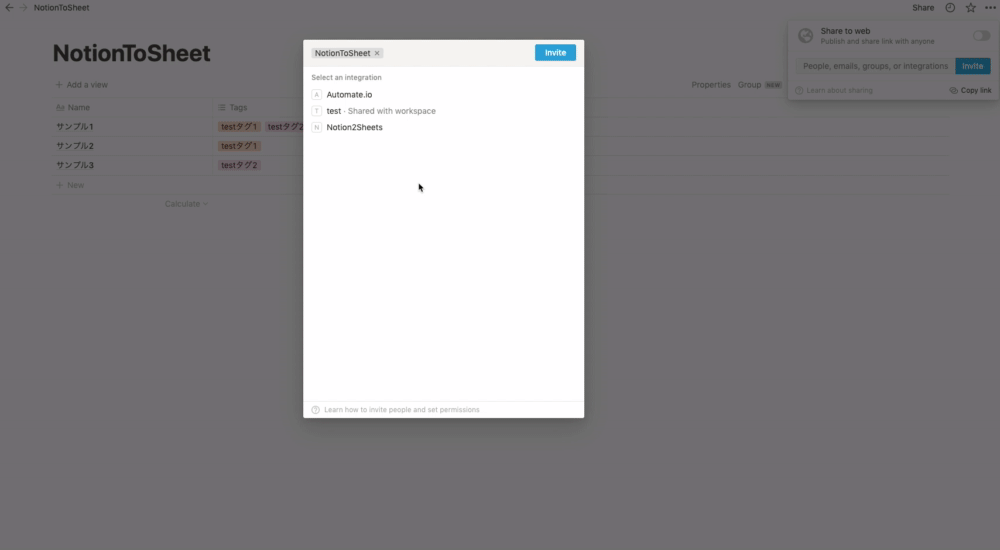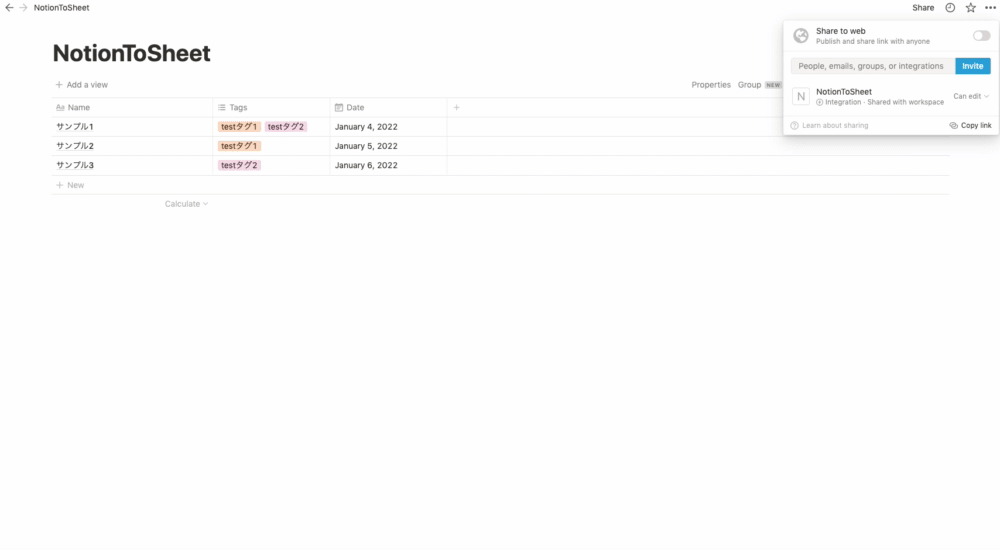
作成したIntegrationとテーブルを紐付けます。
- 先ほど作成したテーブルの右上の「Share」ボタンをクリック
- フォームをクリック
- モーダルが表示されるので先ほど作成したIntegrationを選択
- 「Invite」をクリック
これによって作成したIntegrationからテーブルに情報を取得する準備ができました!
GASでNotionのデータにアクセス
プロジェクトの作成
適当なスプレッドシートを作成し、「拡張機能」→「Apps Script」をクリックします。
定数の定義
今回の実装をする上で値が一定であるものを定数として最初に定義しておきます。
// API用トークン
const integrationSecret = "secret_xxxxxxxxxxxxxxxxxxx";
// 書き込むスプレッドシートのID
const spreadsheetId = "xxxxxxxxxxxxxxxxxxxxxxx";
// Notionのバージョン
const notionVer = "2021-08-16";
// スプレッドシートのシート名とそれに対応するNotionのテーブルのID
const object = {
// スプレッドシートの名前
sheetName: " シート1",
// NotionのテーブルのID
dbId: "xxxxxxxxxx",
}
// 空値
const blankValue = "";
先ほどIntegration作成時にコピーしたトークンをペースト
- スプレッドシートのID
用意したスプレッドシートのIDを入力します。IDの調べ方は作成したシートのURLの下記該当箇所に書かれています。
https://docs.google.com/spreadsheets/d/xxxxxxxxxxxxxxxxxxxxxxxxxxxx/edit#gid=0
- Notionのバージョン
こちらは使用しているNotionのバージョンを記載します。理由はヘッダーにバージョンを指定しないと下記エラーが起こってしまいAPIリクエストが失敗するからです。
Notion-Version header should be defined, instead was `undefined`.
- スプレッドシートのシート名とそれに対応するNotionのテーブルのID
転記先のスプレッドシートの名前をsheetNameプロパティに記載します。また、NotionのテーブルIDはNotionのテーブルのページURLのxxxxxxxxxxの部分に書かれています。
https://www.notion.so/xxxxxxxxxx?v=・・・・・・
- 空値
共通の空値としてblankValueを定義しておきます。
Notionの情報を取得
いよいよNotionの情報を取得します。
まず今回の実装は
- Notionからデータを取得
- スプレッドシートに転記
のため、メソッドを二段階に分けるかと思います。よって前もって二段階に分ける想定で下記のようにgetNotionDatabase(Notionからデータを取得)とsetValuesToSheets(スプレッドシートに転記)を実行するnotionToSheetsメソッドを定義します。これが最終的に実行するスクリプトです。
function notionToSheets() {
const res = getNotionDatabase(object);
setValuesToSheets(res, object);
}
getNotionDatabaseメソッドの中身を記述します。テーブルの中身を取得するための方法は公式に書かれていました。
Start building with the Notion API
公式を参考にメソッドを定義すると以下のようになります。
function getNotionDatabase(obj) {
const headers = {
Authorization: `Bearer ${integrationSecret}`,
"Content-Type": "application/json",
"Notion-Version": `${notionVer}`,
};
const options = {
headers: headers,
method: "post",
muteHttpExceptions: true,
};
let res = UrlFetchApp.fetch(`https://api.notion.com/v1/databases/${obj.dbId}/query`, options);
return JSON.parse(res);
}
UrlFetchApp.fetchメソッドはGASのAPIアクセス時に使えるメソッドです。
Class UrlFetchApp | Apps Script | Google Developers
これでデータは取得はできたはずです。確認したい人はGASのデバッグ機能を使って確認してみましょう。
GASでスプレッドシートに転記
取得したデータをスプレッドシートに転記するsetValuesToSheetsメソッドを記述していきます。長いので先に書いてから上から説明していきます。
function setValuesToSheets(res, obj) {
propertyArray = Object.keys(res.results[0].properties);
const valueArrays = [...Array(res.results.length)].map((v, i) => {
return propertyArray.map((prop) => {
return translateNotionData(res.results[i].properties[prop]);
});
});
// プロパティ配列を先頭に挿入
valueArrays.unshift(propertyArray);
// 参考リンク[https://qiita.com/cazimayaa/items/224daebe536799e5a8a2#getrangerow-column-numrows-numcolumns]
const spreadSheet = SpreadsheetApp.openById(spreadsheetId).getSheetByName(obj.sheetName);
const sheetRange = {
row: 1,
column: 1,
numRows: valueArrays.length,
numColumns: propertyArray.length,
};
const range = spreadSheet.getRange(
sheetRange.row,
sheetRange.column,
sheetRange.numRows,
sheetRange.numColumns
);
range.setValues(valueArrays);
}
まず一行目ですが、これは列の全てのカラムを取得しています。今回自分が作成したテーブルでいうと「Date」、「Tags」、「Name」を取得しています。
propertyArray = Object.keys(res.results[0].properties);
次の行は非常にわかりにくいです。mapメソッドが二重になっています。
const valueArrays = [...Array(res.results.length)].map((v, i) => {
return propertyArray.map((prop) => {
return translateNotionData(res.results[i].properties[prop]);
});
});
まず、 [...Array(res.results.length)].map((v, i)の部分ですが、res.resultsにはNotionのテーブルのレコードごとのデータが格納されています。その数だけ繰り返し処理を行い、全てのレコードを加工しています。次にpropertyArray.map((prop)の部分ですが、後述した通りpropertyArrayはカラムとなります。そのカラムの数だけカラムを加工する繰り返し処理を行います。translateNotionData(res.results[i].properties[prop])の部分ですが、res.results[i].properties[prop]には各レコードの各カラムの値が入ります。今回の実装でいうと「Date」、「Tags」、「Name」の値が渡されています。
translateNotionDataを下記に定義します。
function translateNotionData(data) {
if (data.type === "title") {
return getTitleData(data);
} else if (data.type === "multi_select") {
return getMultiSelectData(data);
} else if (data.type === "date") {
return getDateData(data);
} else {
return blankValue;
}
}
NotionAPIのカラムの値にはdataオブジェクトが渡されその中のtypeプロパティがそのカラムの属性を表しています。データの種類に合わせて加工しているということです。繰り返しますが今回は種類が「Date」、「Tags」、「Name」の3種類にしか対応していません。
function getTitleData(data) {
return data.title.length ? data.title[0].plain_text.trim() : blankValue;
}
function getDateData(data) {
if (data.date) {
return data.date.end
? `${data.date.start}|${data.date.end}`
: `${data.date.start}`;
} else {
return blankValue;
}
}
function getMultiSelectData(data) {
if (data.multi_select.length) {
return data.multi_select
.map((select) => {
return select.name;
})
.join(", ");
} else {
return blankValue;
}
}
setValuesToSheetsメソッドに戻ります。
以下の記載ではvalueArrays(テーブルの全てのレコード)にカラムの配列を先頭に挿入しています。
// プロパティ配列を先頭に挿入 valueArrays.unshift(propertyArray);
次にシートのどの部分に転記するかを定義します。これは記述してある参考リンクを参照いただけるとわかりやすいかと思います。
// 参考リンク[https://qiita.com/cazimayaa/items/224daebe536799e5a8a2#getrangerow-column-numrows-numcolumns]
const spreadSheet = SpreadsheetApp.openById(spreadsheetId).getSheetByName(obj.sheetName);
const sheetRange = {
row: 1,
column: 1,
numRows: valueArrays.length,
numColumns: propertyArray.length,
};
sheetRangeでは一番左上の端からレコードの数(valueArrays.length) × カラムの数(propertyArray.length)の範囲で転記させます。
いよいよ最後に転記するメソッドです。
const range = spreadSheet.getRange( sheetRange.row, sheetRange.column, sheetRange.numRows, sheetRange.numColumns ); range.setValues(valueArrays);
定数rangeに転記する範囲を定義します。そしてrangeを使ってsetValuesメソッドを使用すると転機ができます。
最終コード
最終的にできたコードは下記になります。
// API用トークン
const integrationSecret = "secret_xxxxxxxxxxxxxxxxxxx";
// 書き込むスプレッドシートのID
const spreadsheetId = "xxxxxxxxxxxxxxxxxxxxxxx";
// Notionのバージョン
const notionVer = "2021-08-16";
// スプレッドシートのシート名とそれに対応するNotionのテーブルのID
const object = {
// スプレッドシートの名前
sheetName: " シート1",
// NotionのテーブルのID
dbId: "xxxxxxxxxx",
}
// 空値
const blankValue = "";
function notionToSheets() {
const res = getNotionDatabase(object);
setValuesToSheets(res, object);
}
function getNotionDatabase(obj) {
let data = obj.data;
const headers = {
Authorization: `Bearer ${integrationSecret}`,
"Content-Type": "application/json",
"Notion-Version": `${notionVer}`,
};
const options = {
headers: headers,
method: "post",
muteHttpExceptions: true,
};
let res = UrlFetchApp.fetch(`https://api.notion.com/v1/databases/${obj.dbId}/query`, options);
return JSON.parse(res);
}
function setValuesToSheets(res, obj) {
propertyArray = Object.keys(res.results[0].properties);
const valueArrays = [...Array(res.results.length)].map((v, i) => {
return propertyArray.map((prop) => {
return translateNotionData(res.results[i].properties[prop]);
});
});
// プロパティ配列を先頭に挿入
valueArrays.unshift(propertyArray);
// 参考リンク[https://qiita.com/cazimayaa/items/224daebe536799e5a8a2#getrangerow-column-numrows-numcolumns]
const spreadSheet = SpreadsheetApp.openById(spreadsheetId).getSheetByName(obj.sheetName);
const sheetRange = {
row: 1,
column: 1,
numRows: valueArrays.length,
numColumns: propertyArray.length,
};
const range = spreadSheet.getRange(
sheetRange.row,
sheetRange.column,
sheetRange.numRows,
sheetRange.numColumns
);
range.setValues(valueArrays);
}
function translateNotionData(data) {
if (data.type === "title") {
return getTitleData(data);
} else if (data.type === "multi_select") {
return getMultiSelectData(data);
} else if (data.type === "date") {
return getDateData(data);
} else {
return blankValue;
}
}
function getTitleData(data) {
return data.title.length ? data.title[0].plain_text.trim() : blankValue;
}
function getDateData(data) {
if (data.date) {
return data.date.end
? `${data.date.start}|${data.date.end}`
: `${data.date.start}`;
} else {
return blankValue;
}
}
function getMultiSelectData(data) {
if (data.multi_select.length) {
return data.multi_select
.map((select) => {
return select.name;
})
.join(", ");
} else {
return blankValue;
}
}
終わりに
NotionAPI、GAS共に初めて使用しましたがドキュメントは非常にわかりやすかったのですぐにAPI情報を取得することができました。
難点としてはやはりカラムのデータを加工する際にデータの種類に合わせて処理が必要なことですね。。これはどうやって対応すればいいのかわかりませんでした。よりいい方法がありましたら教えてください🙇♂️
以上、大ちゃんの駆け出し技術ブログでした!
【無職に転生 ~ 就職するまで毎日ブログ出す_33】【書籍】【心理的安全性の作り方】
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。

RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
今回は書籍「心理的安全性のつくりかた」という本をご紹介します。こちらの本は昨年の9月に発売された比較的新しめの本ですが、職場における心理的安全性の必要性やそのつくりかたについて詳しく実践的に紹介しています。この本を手にした時自分は「心理的安全性を理解し、今の自分がどうやって生み出すことができるかを理解する」という目的で購入しました。こんな駆け出しエンジニアの自分でも職場環境を大きく変える要因となれる方法を紹介しているので、自分でもできそうな部分抜粋して本を紹介していきたいと思います。

心理的安全性とは
まずは心理的安全性について理解していきます。本の中では「はじめに」の項目の最初のページで早速説明されています。
「心理的安全性」とは、組織やチーム全体の成果に向けた、率直な意見、素朴な質問、そして違和感の指摘が、いつでも、誰もが気兼ねなく言えること
例えば、現在会社で所属しているチームには何かしらの問題があって、その問題について入社2年目程度のあなたが解決策を持っているとします。その解決策を躊躇いなくチームに率直に伝えることができるのであればそのチームには心理的安全性が働いていると言えます。
昨今、この「心理的安全性」という言葉がチームで働く上で非常に注目されています。2012年にGoogleが立ち上げた、「効果的なチームは、どのようなチームか」を調査するプロジェクトで、「チームがどのように協力しているか」が重要であることがわかりました。そして、その協力を生み出す要因の中で1番重要なのが心理的安全性ということがわかったそうです。そのため、心理的安全性について解かれた本がここ数年でたくさん出版されています。
チームの心理的安全性
この心理的安全性がチームで担保されている場合、そのチームはどのような状態になっているか。それを考える時、その対照である心理的「非」安全性のチームについて考えることで心理的安全性があるチームを理解していくことができます。
心理的非安全性とは心理的安全性の逆、つまり、言いたいこと、やりたいことがあったとしてもそれを率直にすることができない状態です。
「無知だと思われるかもしれない」
「無能だと思われるかもしれない」
「否定的に思われるかもしれない」
何か行動を起こそうとする時に上記のような考えがよぎり行動をためらうチームは心理的非安全性が働いているチームと言えます。
この本の中ではこの心理的安全性の有無、さらに仕事の難易度の高低で職場を4種類に分類しています。ざっくりと以下のように要約しました。
ヌルイ職場
仲がいいが仕事の基準が低いので挑戦がない。よって仕事が充実していない。
サムイ職場
仲が悪く仕事基準も低いので何かをしようとするだけで咎められる環境。(自分の全色はこんな感じでした)
キツイ職場
仕事の基準が高いが仲が悪いため心理的ストレスが高い。評価が減点方式なので悪い部分ばかり指摘される。褒め合いがない。
学習する職場
仕事は難しいが仲の良さからいろいろな挑戦やアイデアを言い合える。仕事の進め方を学習することができる職場。意見が衝突してもそれは争いではなく建設的である。

このような心理的安全性が高いチームは誰しもが意見を言い合いそれを建設的な議論で吸収していくので非常に改善のスピードが速い職場であることがわかります。現代は今の常識が明日の常識とは限らない比喩される「変化の激しい時代」であり、職場で通じている仕事がいつ通じなくなってもおかしくないです。その変化が起きたタイミングでいかに早く改善できるかが重要なのですが、それができるのが心理的安全性が高く仕事の難易度も高い職場なのです。
心理的安全性を作る4つの因子
この心理的安全性を作り出している因子が4つあると言われています。まとめて「話助挑新」と言われています。
話しやすさ・・・意見の言いやすさ、質問のしやすさがある
助け合い・・・困難に直面したときに助けを求められる環境がある
挑戦・・・何か新しいことへの挑戦を応援する環境がある
新規歓迎・・・組織がトップダウンではなくボトムアップで、どんなタイプの人でも歓迎される
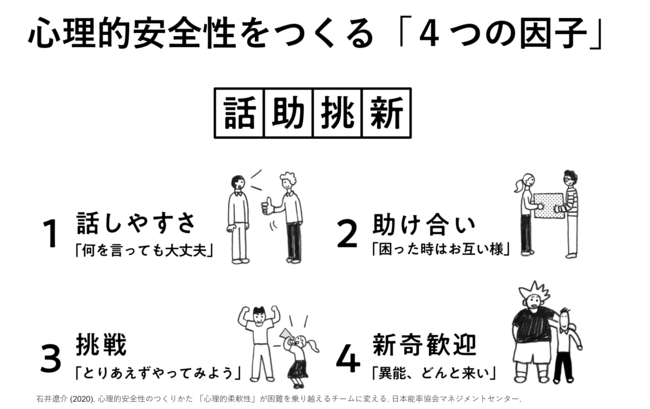
話しやすく、助け合いで溢れており、挑戦を推奨し、新しく参入してくる人に歓迎的な状態があれば、その職場には心理的安全性が担保されているというのです。
心理的柔軟性3つの要素
心理的安全性のつくりかたというタイトルなので、心理的安全性を説明しただけではこの本は終わりません。この本はどのようにして心理的安全性をつくることができるのかまでフォーカスしています(むしろつくりかたの文量の方が圧倒的に多いです)。
心理的安全性をチームにつくる上で重要なのは心理的柔軟性と紹介されています。
状況に合わせて、場面ごとに、より役に立つリーダーシップを切り替え使い分ける柔軟性
ここでいうリーダーシップとは「他者に影響を与える能力」と説明されており、チームのリーダーポジションでなくても使える能力と言われています。リーダーシップには状況に応じて必要なリーダーシップがあると言われ、それを使い分ける柔軟性があることがより心理的安全性をもたらす要因になると言われています。その心理的柔軟性の要素は以下の3つです。
- 変えられないものを受け入れる
- 大切なことに向かい、変えられるものに取り組む
- マインドフルに見分ける
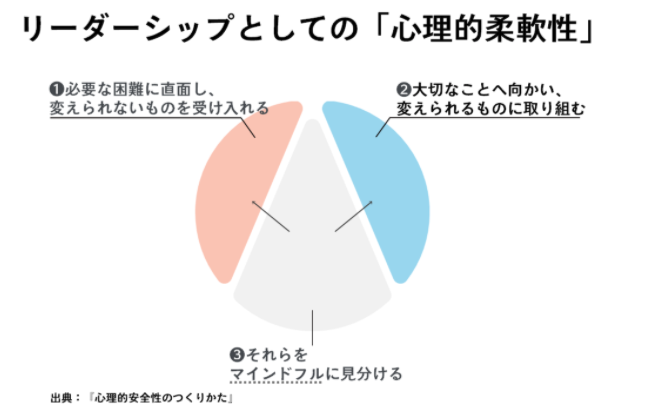
必要な困難に直面し、変えられないものを受け入れる
困難に直面したとしても、変えられないものは仕方ないとして受け入れるマインドセットが心理的柔軟性の第一の要素です。
必要な素養として「現実 = 思考」を外すというものが挙げられます。これは自分たちの思考が現実の世界に起きているものとして捉えられている状態です。偏見、バイアスとも言えるかと思います。例えば、以下のような考えは思考を現実のものとして捉えてしまっています。
- あの人には散々怒られたからもう頼まない
- あの人は自分が正しいとしている人だから説得しても無駄だ
経験や体験から得たものが現実であるという捉え方が定着しているため、その捉え方を正しいとしているために行動が制限されています。見れば明らかですが、話しやすさや助け合いなどの機会を思考が潰してしまっています。
この思考と現実とを結びつける「=」をなくしていくことが必要になります。その方法として、何が正しいで何が間違っているかを自分の中で判断しないようにすることが重要です。何かを判断することで自分の思考の中に偏見が生まれてしまい、それが現実として捉えられてしまうため、判断が思考を現実に捉えてしまっているきっかけになっているのです。
また、困難な感情に抗うことを止めて受け入れることも必要な素養です。例えば、嫌なことがあってそのストレスをどうにかしようとする行動は基本的に無意味とされています。負の感情に対して抗えば抗うほど無意味な抵抗です。抵抗するのではなくその感情を味わい抵抗せずに受け入れることの方がよっぽどそのストレスに対応できます。このような心のブレなさなども心理的柔軟性には必要です。
大切なことに向かい、変えられるものに取り組む
まず、あなたが思う「大切なこと」を明確にしてください。仕事をする上で自分自身が何を大切にしたいかを明確にするのです。これは言わば仕事で向かう方向を決めるコンパスです。次に大切なことへ向けた具体的な行動を起こします。その行動は変えられるものに取り組んでいるので努力をすれば変えることができます。このような変えられるものに対して取り組む姿勢も心理的柔軟性の因子の一つです。
マインドフルに見分ける
この変えられる、変えられないを見分けるマインドセットも心理的柔軟性です。このマインドセットが心理的柔軟性の心構えを生み出します。
まず、「いま、この瞬間」に集中していることが必要です。人間は言語を持っているいきもであるため、物事を過去と未来と今に分割することができます。多くの人は過去に対する後悔、未来への不安を考えていると思います。しかし、それでは今変えられるものと変えられないものを見分けることができません。今のことを考えずに未来のこと、過去のことを考えている時間が多いので、今起こっていることを認識できていないのです。これについてはマインドフルネスを取り入れるなどが本の中では対策として紹介されています。
また、自分を自分観察者として捉えることも必要と言われています。これは「思考 = 現実」とも似ているのですが、自分の性格、価値観、行動パターンなどを自分が定義している状態から脱することが観察者となることです。自分を定義してしまうと行動パターンに柔軟性がなくなってしまいます。例えば、「事業を必ず成功に導く」という定義をしていれば、(たとえ事業がうまくいっていなくても)事業の成功まで尽力してしまいます。自分を外から見る、自分を客観的に見ることで、定義から外れ様々な選択肢から行動を選ぶことができるようになります。この柔軟性も心理的柔軟性の一つです。
心理的柔軟性を見た感想としてはほとんどのことは「反応しない練習」で書かれていると思いました。気になる方は自分の記事ですが下記を参照ください。
【無職に転生 ~ 就職するまで毎日ブログ出す⑨】【書籍】反応しない練習 - 大ちゃんの駆け出し技術ブログ
行動分析で作る心理的安全性
心理的柔軟性が理解できたところで、この心理的柔軟性を用いて心理的安全性を作る方法を紹介したいと思います。ここでまず行動のフレームワークというものをご紹介します
行動には全て「きっかけ」 => 「行動」 => 「みかえり」が伴います。例えば、室内の温度が熱い (きっかけ)とします。それに対して室内のエアコンの操作ボタンに行き温度を下げます(行動)。当然ですが、室内の温度が涼しくなります (みかえり)。このようにきっかけがありそこから行動を起こし、そしてみかえりをもらうのが行動の始終と言えます。
ここで重要なのはみかえりです。みかえりがHappyかUnhappyかによって、次から起こした行動を取る確率が変化します。みかえりがHappyであればその行動は継続されていきます。しかし、見返りがUnhappyにつながれば次にその行動をしなくなっていきます。
※ この時のHappyを好子、Unhappyを嫌子という
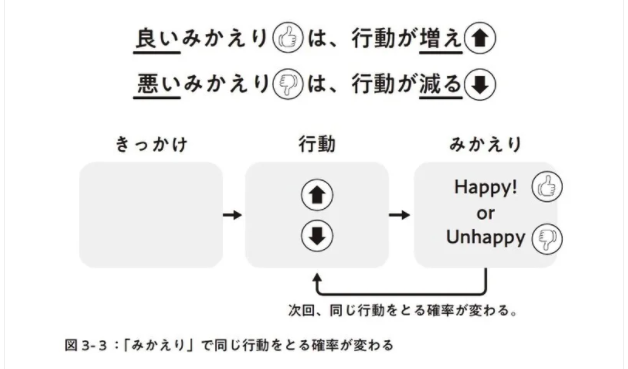
話助挑新を心理的柔軟性で生み出す
この行動のフレームワークを話助挑新に活かすことで心理的安全性をつくることができるようになります。行動は相手がすることなので、「きっかけ」を与え、「みかえり」に好子を与えることで行動を促進することができるのです。そしてそのきっかけを与える、みかえりを与えるためには、心理的柔軟性という性格が必要なのです。
話しやすさ
基本的にみかえりを与える行動が話しやすさを生みます。例えば、相手が話している時に
- うなずき、相槌を打つ
- 興味を持って聞く
これにより話しやすさが生まれます。
助け合い
助けを出してもいいというきっかけを作り、助けが出たらフルコミットで対応しみかえりを与えます。助けを出すきっかけは、いつ、どういう手段で助けを出していいという具体的な助けの出し方を定義することでより相手が助けを出しやすくなります。そして助けを求められたら真摯に応えることでみかえりを与えます。これで相手は助けを出すという行動が促進されます。
挑戦
職場に挑戦するきっかけを与えます。
- いつでも挑戦をしてもいいという雰囲気を作る
- 挑戦を否定せず応援する
これによって挑戦する行動が促進されます。
新規歓迎
年功序列ではなく新規参入者も挑戦できるきっかけを作ります。新しく入ってきた人にも個性を生かせる場を提供することで、平等に活躍するチャンスを与えることができます。
【無職に転生 ~ 就職するまで毎日ブログ出す_32】【書籍】最強の集中力
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
今回はまたまた立て続けですが書籍について書きました。本のタイトルは「最強の集中力」です。正直あんまり売れなかった本なのですが、個人的にはすぐに実践できるような内容だったのでお勧めしています。
本について
元々はニール・イヤーさんという海外の方が書かれた本で、英タイトルは「indistractable」となっています。これは実際には英語ではないワードで著者が作った造語です。ditstractable(注意散漫な)という形容詞の反語として解釈されています。注意散漫の反対ですので「集中できている状態」を意味しているので、まさに最強の集中力と訳されているわけです。

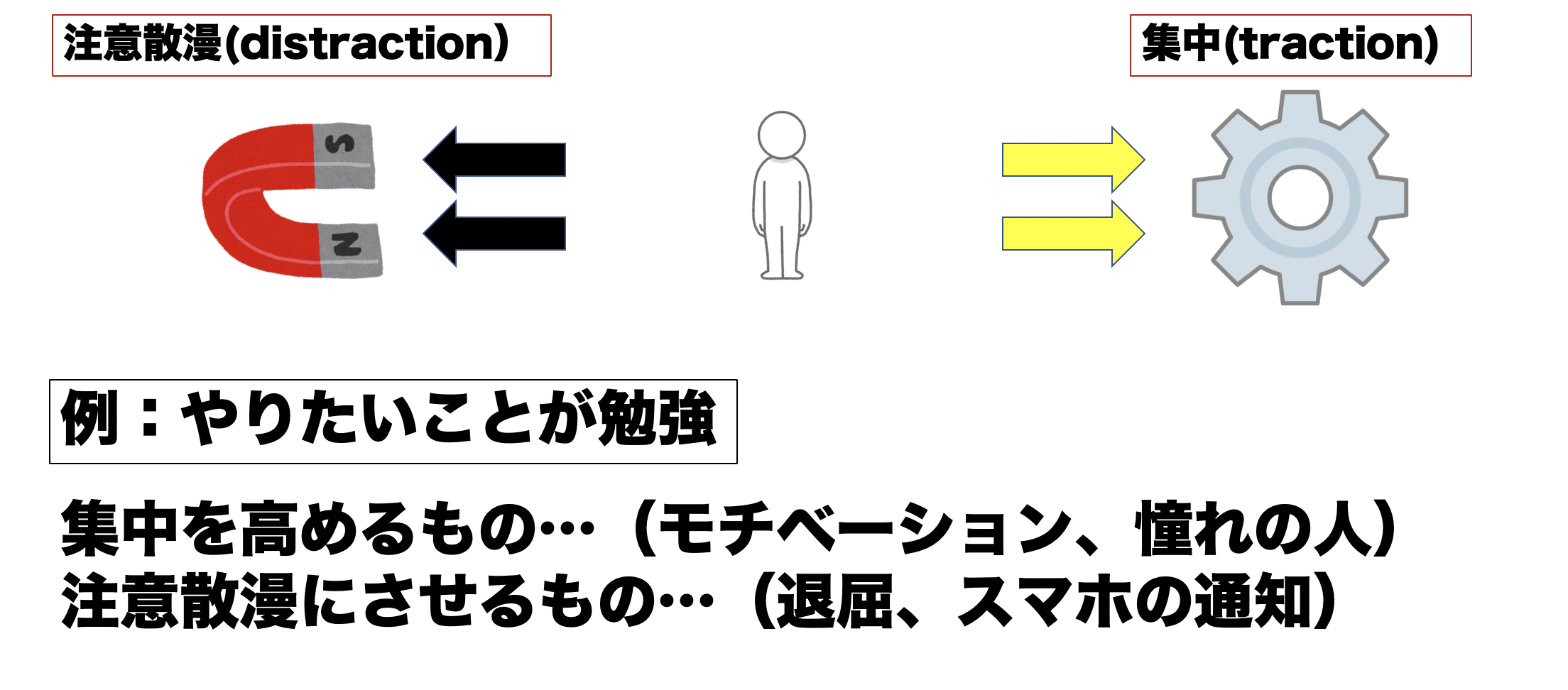
集中力の構図
「集中力」と聞くとかなり抽象的ですよね。集中している状態って人は実際にどういう状態にあるんだろうという疑問があると思います。著者は人間が何かに取り組む時、集中力はtraction(集中を高めるもの)とdistraction(注意散漫にさせるもの)によって決まると言っています。tractionが集中状態に引っ張り、distractionが注意散漫に引っ張ることで集中力の足し引きが行われ、その結果が集中力として現れます。
tractionの例としてはモチベーションが主な例です。モチベーションが高い状態は極めてそれに取り組む意欲が湧いている状態であり、集中力が非常に高くなりやすいです。モチベーションの例としては「憧れの人」が挙げられるでしょう。尊敬する人、憧れの人に近づくことがモチベーションを生み、それが集中力となりパフォーマンスが向上します。
反対に注意散漫にさせるdistractionの代表例はスマホの通知です。どんなに集中している状態でもスマホが鳴ってしまうと集中力が切れてスマホを確認してしまうことがあると思います。また、モチベーションが高くない状態、つまり、退屈に感じている時も注意散漫になっている状態と言えるでしょう。退屈と感じているために全くモチベーションが高くならず集中状態に入ることができない体験も誰しもが持っているはずです。
内部誘引と外部誘引
tractionとdistractionには感情などの内部から引きつける内部誘引と環境などの外部から引きつけ外部誘引があります。例えば、tractionで上述したモチベーションは感情であるため内部誘引でありますが、それの源泉は憧れの人という外部誘引から来ています。distractionの場合退屈という感情は内部誘引であり、スマホの通知音は外部誘引です。
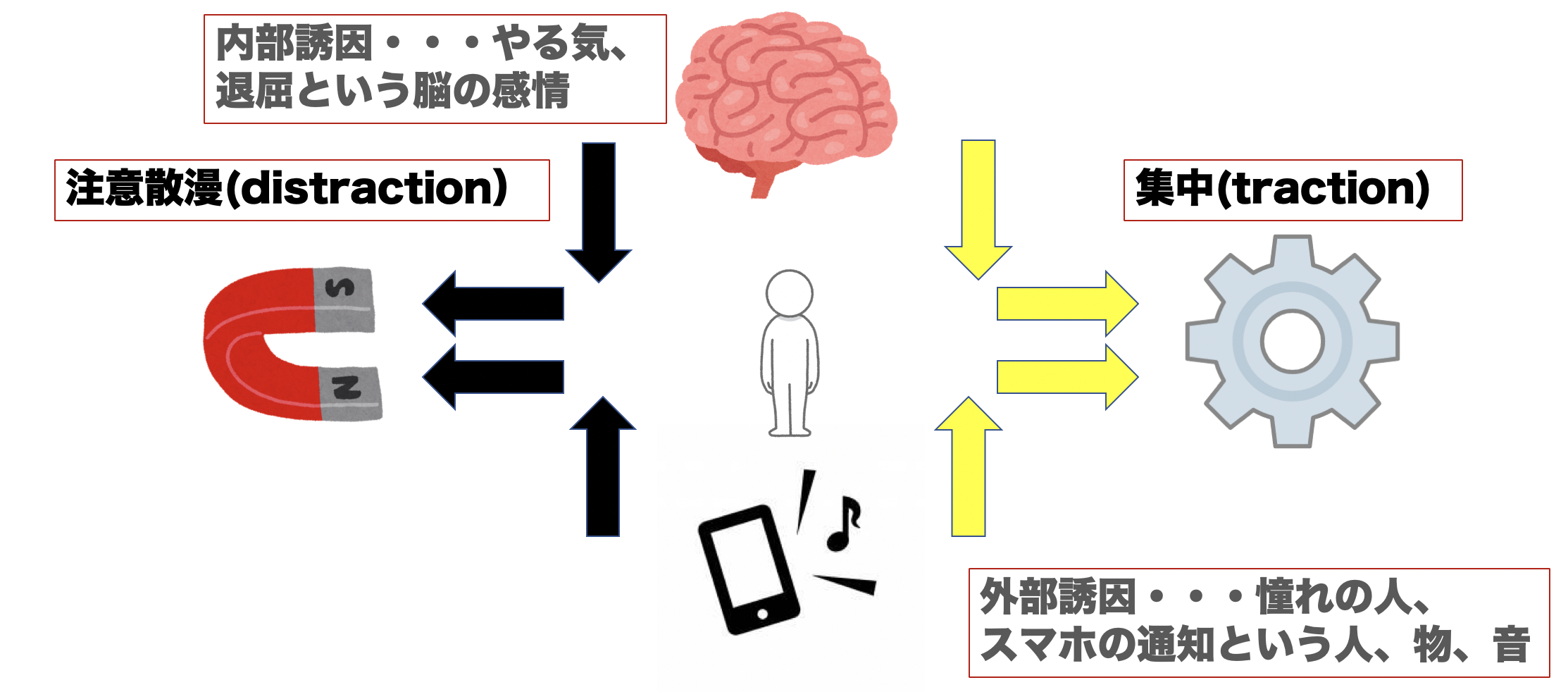
このように集中力は内部の力と外部の力によって生み出されています。この図を見ると、集中力の高さはいかにtractionを増やし、distractionを取り除くことができるかが重要であることがわかると思います。ここからは内部誘引と外部誘引をハックする(コントロールする)ことで、集中力を高める方法を紹介していきたいと思います。
内部誘引をハックする
まず内部誘引のハックですが、自分の感情をコントロールすると置き換えていいと思います。人の感情によって注意散漫になっている状態って退屈以外にもたくさんあります。不安、心配、疲労感は全て集中力を妨げる感情です。これらの感情があるから人は集中できずに注意散漫な行動に走ってしまいます。
例えば、昨年度の新型コロナウイルスが非常に不安であった当初、多くの人はコロナウイルスの感染者数に注意がいっていました。毎日午後14時ごろに前日の新規感染者数が発表されていたので、その時間になったらコロナウイルスに怯えていた多くの人がスマホを確認していました。また、日常でも疲労感を感じやすい人が疲れて横になりスマホを見るという行動も注意が散漫になっている状態です。

多くの行動は不安から生じる
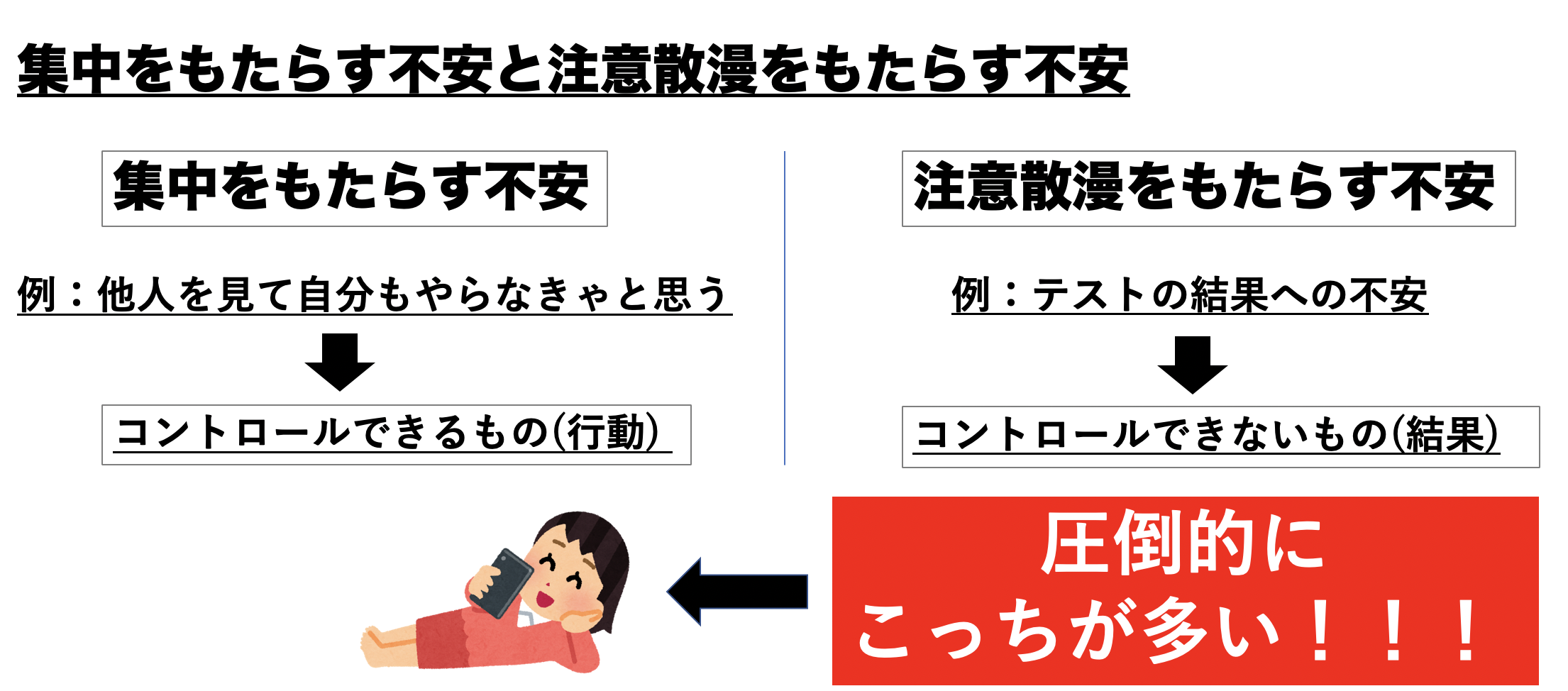
不安による行動の種類は非常に多いです。しかし、それら全てが注意散漫を導いているわけではありません。不安には集中力をもたらす不安と注意散漫をもたらす不安があります。
例えば、他の人と比べて自分が劣っていると感じた時、それが自分も頑張らなければというモチベーションに変わり集中状態になるということもあります。この不安の場合、不安をコントロールする方法としては自己研鑽であるため、自分でコントロールできる不安であることから集中力が生まれています。
しかし、逆に上述したようなコロナウイルスや結果への不安はコントロールできません。そのような不安は自分の行動では結果をコントロールできないため、解消方法がわからず注意散漫な行動には知ってしまいます。そして、問題なのはこのコントロールできないものに対する不安の方が不安の割合としては圧倒的に多いということです。そのため、不安によって多くの注意散漫が日常にもたらされています。
不安をコントロールする
以上のことから不安のコントロールをすることで注意散漫な状態から抜け出すことができることが多くなります。その具体的な実践方法としてはマインドフルネスなど神秘的なものになります。不安はスマホをいじっても酒を飲んでも解消されるものではありません。逃げずに受け入れることが重要ということはこの本でも他の本でも言っています。不安を取り除くには「反応しない練習」が1番効果が高いと思っているので、気になる方は下記記事をお読みください。
【無職に転生 ~ 就職するまで毎日ブログ出す⑨】【書籍】反応しない練習 - 大ちゃんの駆け出し技術ブログ
外部誘引をハックする
内部誘引だけでも感情のコントロールという難易度が高いものですが、外部誘引はその比ではないです。なぜなら内部誘引とは違い、外部誘引はほとんどが注意散漫をもたらすからです。特に注意散漫を引き起こすものは、デジタルやインターネット関連の存在です。これらによって今自分たちは多くの情報や選択肢の中に囚われるています。
例えば、アマゾンで何か商品を購入するとします。アマゾンで何か商品を検索した時に、多くの商品が並びます(選択肢過多)。さらに、各商品のレビューやコメントの多様さも目にします(情報過多)。これらが原因で結局本来買いたかった商品を買えず、しまいには購入そのものを諦めてしまうことがあります。

スマホをハックする
もっとも選択肢や情報を供給するものはスマホです。スマホ一つを手にとればたくさんの行動の選択肢があり、そこからたくさんの情報を得てしまいます。スマホは便利ですが、注意散漫を生み出すデバイスでもあります。
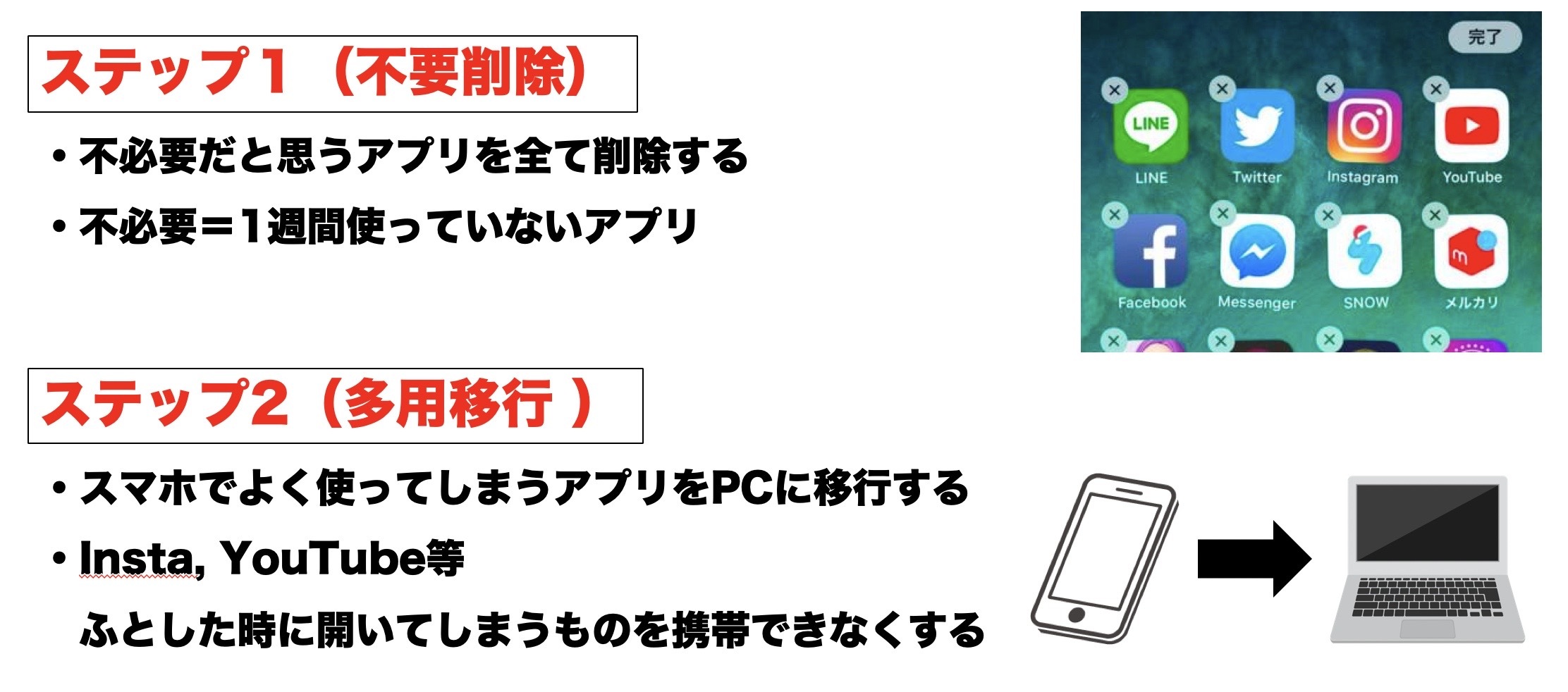
スマホのハック方法としては以下のとおりです。
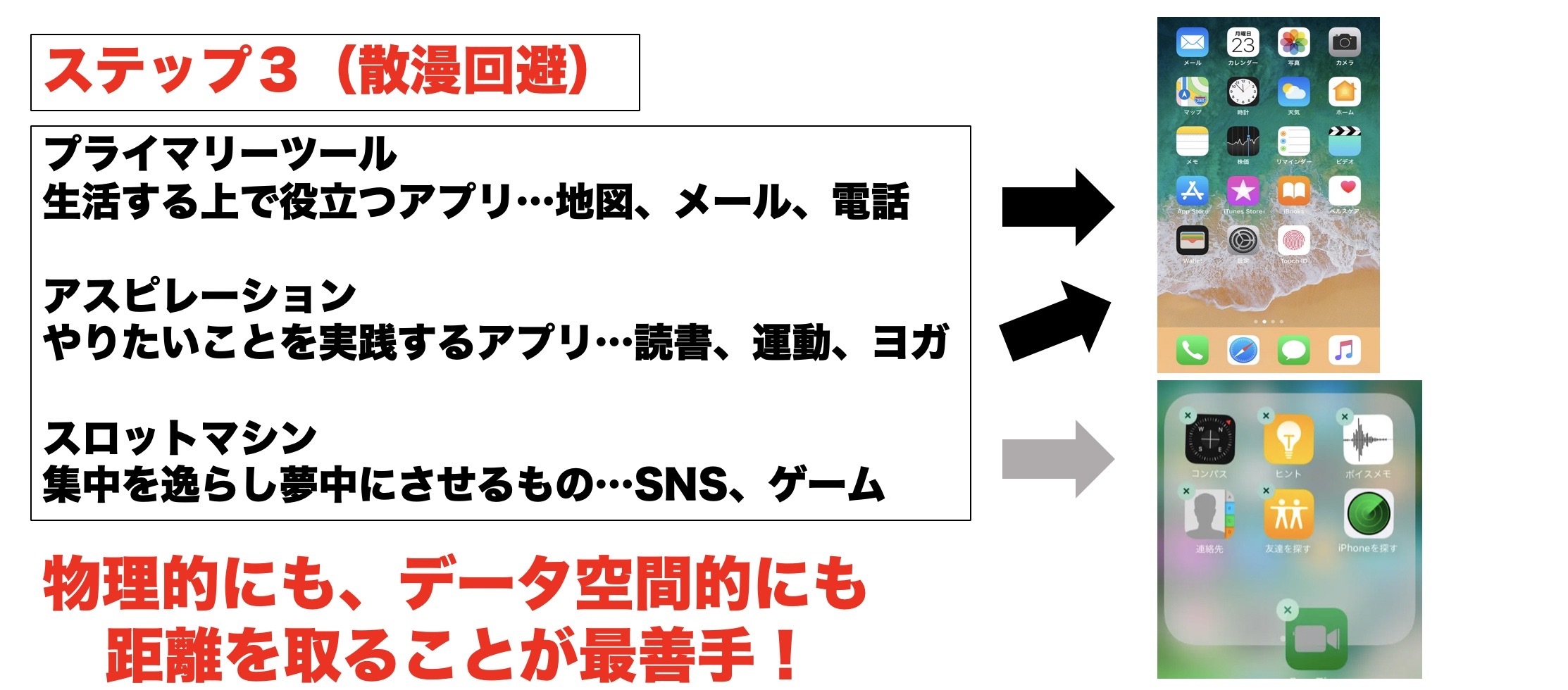
ステップ1
不必要なアプリを全て削除します。ここでいう不必要とは一週間使っていないアプリです。
ステップ2
残ったアプリでよく使ってしまうものをPCに移行します。LINEなどが挙げられます。
ステップ3
アプリ種類を分割し、スロットマシン(SNS)などはデータ空間から見えなくする
距離を置く
スマホをハックしても使い続けてしまう可能性があります。それに、スマホ以外にも多くの注意散漫をもたらすものが周りにあふれていると思います。そのようなものは距離を置くのが1番手っ取り早いです。つまり、その注意散漫をもたらすものから物理的に距離を置くのです。自分はスマホをロフトの1番奥に置いてくることで一日中スマホの画面から離れています。
【無職に転生 ~ 就職するまで毎日ブログ出す_31】【番外編】毎日投稿を続けるメリット・デメリット・続け方
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
毎日投稿をまた1ヶ月続けてみて、以前働いている時に毎日投稿もしていた頃と比べてブログを書いておくこと、毎日投稿のメリット・デメリットやノウハウなどがなんとなくですが言葉にできるようになってきたので、ここで一度シェアをしておきたいと思います。役に立つかはわかりませんが、読んでいただけると嬉しいです。
ブログを書くメリット
最初はブログを書くメリットについて簡単にお話しできればと思います。
自分の辞書を作れる
ブログを積み重ねると後々辞書として役立てることができます。これは特にポートフォリオ作成期間中に感じたのですが、RUNTEQのカリキュラムで学んだことをアウトプットした自分の記事を何度も読み返していました。自分で理解できるようにまとめたものなので後で見返した時にすぐに理解できます。

プログラミングは一度実装したことは基本的に全て忘れます。そして再度実装しようとした時には、また何かしらの記事を読むはずです。その時に自分用にまとめておいたものを検索するのと、また複数の記事を読み漁り実装していくのでは理解度もスピードも全く違うはずです。
知識の修正・拡張
覚えた知識を修正する作業、拡張する作業としてもブログはうってつけです。
修正するとは覚えたことが正しいのかどうかを確認する作業です。例えば、私はRubyのfindメソッドをアウトプットしたことがあります。。その時にアウトプットする前はfindメソッドはidを引数にする覚えていました。
User.find(params[:id])
しかし、findメソッドは実はプライマリーキー検索であることがブログで他の記事を読み漁ることでわかりました。ですのでテーブルのプライマリーキーによってfindの引数は変わってきます。このように一度覚えたことを鵜呑みにせず他の記事を参照することで自分の覚えたことが果たして正しかったのかどうかを確認することができます。
知識の拡張にもブログはうってつけです。他の記事を読み漁る時に自分がアウトプットしようとしている関連事項を目にすることができます。例えば、eachメソッドをアウトプットする時に配列関連のインスタンスメソッドを目にして、他のメソッドもあることを知ることができます。
mapselectcollectfilterfilter_mapeach_with_index
このように他の記事を読む機会が増えるので知識を増やす機会にもなります。
コードの説明力が上がる
これはブログを書く際の意識で大きく変わってくるのですが、自分の辞書を作る意識でブログを書けばコードの説明力はすごくつくと思います。後で読み返すことができるように画像やgif、参考記事などをまとめる作業は、まさにプルリクエストで行っていることです。ですので、先輩エンジニアに質問する際にコードを説明する機会にブログで培ったコードの説明力は役に立つと思います。

毎日投稿を続けるメリット
毎日投稿なんてただがむしゃらに頑張っているだけではと思われる方もいらっしゃると思うのでポートフォリオ をしてみて感じたメリットもお伝えします。
自分が理解していないカテゴリーを把握できる
ネタを毎日探すので自分が理解していない分野を把握できるようになります。基本的にアウトプットする内容は理解していないこと、理解したけどあまり定着していないことになるかと思います。ネタを探す際に理解しているものはネタとして選ばないので自然と理解していないカテゴリーだけがネタとして上がってきます。毎日ネタを探すだけ現状自分が理解していない分野が浮き彫りになりやすいので現状理解できることはメリットだと思います。
"要約力"が身につき書く時間を短縮できる
毎日書くことで要約力が身につきます。ブログを書くのは非常に時間がかかることで始めたばかりの人は基本二時間以上かかっていると思います。しかし、ブログを書くことに慣れてくると説明に不要なことと必要なことの分別がわかってくることや、1ネタに対してどれほど時間がかかるかも書く前にわかるようになるので、必要最小限の情報でブログを書く意識が出てきます。

自分もブログを始めたばかりに頃はあれもこれも調べなくてはと長い説明文を書き基本3時間ほどかかっていました。しかし、自分の辞書であることから自分が理解できればそれだけで効果があることを理解し、見ているすべての人に気を使ってすべて説明する必要はないと感じたので、必要な説明は自分が理解していないところだけにしてブログを書くようにしました。結果、今だとだいたい1時間30分程度で書き終わることが多いです。
毎日投稿を続けるデメリット
逆にポートフォリオ をすることでデメリットも感じたので共有します。
ネタが尽きてアウトプットが乱雑になる
ネタが徐々に尽きてきてブログを完成させることが目的となり、アウトプットの質が低下してしまうことがあります。毎日続けていくとアウトプットの総量がインプットよりも多くなってしまうケースが多々ありました。そうなると、ただ適当な内容をピックアップしてアウトプットすべきかどうかの視点をなくしたアウトプットをしてしまいます。自分もメソッドの説明などはかなりネタ切れでアウトプットしている感があり、目的がブログの継続になっているのでアウトプットの質の低下を感じています。エンジニアになれば業務時間内でインプットの総量が多くなると思うのですが、それでもネタ切れのタイミングは時々起こりそうです。なので、今アウトプットしようとしていることが本当にためになることなのかを確認する意識が必要だと思いました。それで、アウトプットする必要がないと判断した場合、毎日投稿の継続をやめて他のことに時間を使った方がいいと思います。
努力が本質的かわからない
上のアウトプットの質と内容がかぶるのですが、そもそも毎日投稿という努力が本質的かどうかがわからなくなると思いました。プログラミングを勉強する方法はブログを書くことだけでなく、書籍を読むことや個人開発など様々です。現状の自分がどの勉強方法が必要なのかを完全に無視してアウトプットブログを続けるので、他の勉強方法の選択肢を捨ててしまっています。ブログに拘らずに、どの勉強方法が必要なのかをしっかりと把握することが重要だと思いました。
続ける方法
最後に続ける方法です。
普段からネタややったことをストックする
ブログで使えるものをあらかじめストックしておくことはかなり有効だと思います。読んだ記事の内容やプログラミングを実装している時のコマンドやコードをあるスペースにメモしておくことであとあとアウトプットするネタをためておくという言い方が正しいです。

何も準備していない状態で一からネタを探すのはかなり面倒な作業だと思います。それより自分がネタを普段からストックしておけばかなりネタを探すことは簡略化できるはずです。さらにコードなどは実際にアウトプットする記事にそのまま貼り付けることもできるので、コードを再度探す、書く手間が減るので大変便利です。普段から何か実装している時に新しい内容やコードはメモしておくといいでしょう。
Notionを活用する
こちらの記事で説明しているので割愛します。
明日のブログは今日終わらせる
こちらも実は以下の記事で説明しています。
働きながらでも技術ブログを続ける方法 - 大ちゃんの駆け出し技術ブログ
終わりに
ついに1ヶ月経過してしまいました。しかし、仕事を続けながら毎日投稿をしていたこともあったや、継続的にブログを書いてきたので、かなり楽に達成できたと感じています。しかし、ネタ切れは否めないため早く就職して終わらせたいなと思っています。と言っても実は後少しで終わりそうです!ので後少しの期間頑張ります!
【無職に転生 ~ 就職するまで毎日ブログ出す_30】【Rails】simplecov
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
テスト解析ツール simplecovについて紹介します。導入も非常に簡単で使い勝手も保守が好きな自分としてはかなりいいと思っています。たいていテストは蔑ろにされがちですが、こちらを使っていかに自分たちのコードがテストされていないかを見てみるのもいいと思います。
※ RSpecを使っていることを前提とします。
概要
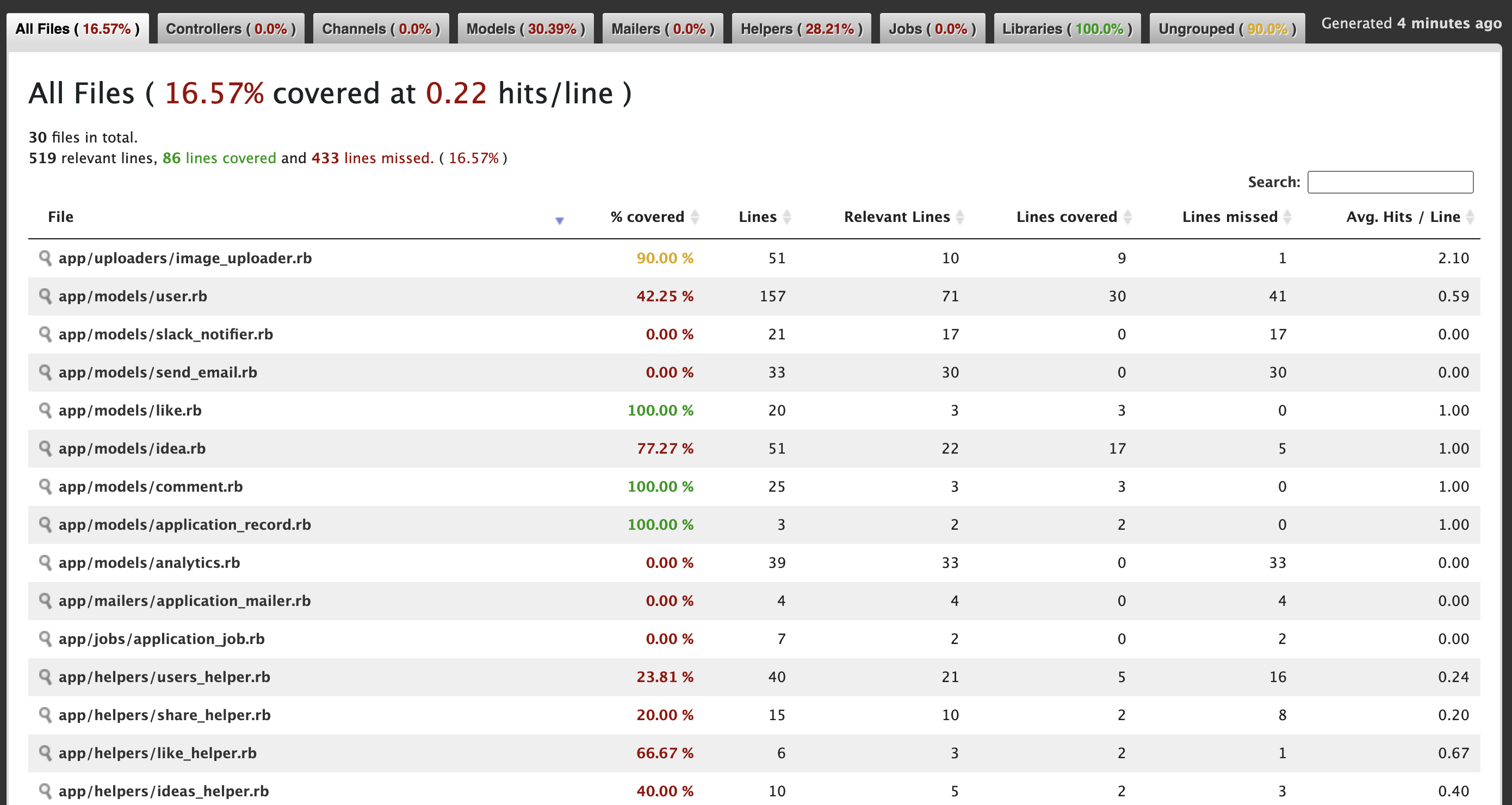
自分たちが書いたテストの結果どれだけ網羅できているか?意図した箇所が網羅されているか?など分析できるツールです。以下のような画面で走っているコードからテストのcoverage(どれぐらいテストが網羅されているか)を確認してくれます。
導入方法
導入方法を紹介します。まずはいつも通りGemfileに記述します。開発環境とテスト環境でしか使わないため、プロダクション環境でgemを使うように指定しましょう。
group :development, :test do gem 'simplecov', require: false end
インストールします。
$ bundle install
次にrspec_helper.rbに以下の記述を追加します。
require 'simplecov' SimpleCov.start 'rails'
※ 記述する場所はRSpec.configureの外側にします。
# spec/rspec_helper.rb RSpec.configure do |config| # rspec-expectations config goes here. You can use an alternate # assertion/expectation library such as wrong or the stdlib/minitest # assertions if you prefer. ・ ・ ・ end require 'simplecov' SimpleCov.start 'rails'
導入としては以上になります。最後にgitignoreに以下の記載をしましょう。
# .gitignore /coverage/
使用方法
まずはrspecのテストを実行
$ bundle exec rspec
実行するとターミナルの1番下に下記のような表示が出るのがわかります。Coveage reportとあるようにどれぐらい網羅されているのかのレポートが作られたようです。
Coverage report generated for RSpec to /xxxxxx/xxxxx/xxxx/xxxx/xxxxx/xxxxxxx/ideee/coverage. 86 / 519 LOC (16.57%) covered.

simplecovを導入後に実行するとcoverageディレクトリが作成されていることがわかります。先ほどgitignoreでディレクトリを追加したのはこのためです。ディレクトリの中にindex.htmlがあることを確認できると思います。
このindex.htmlをブラウザ上で開くとテスト解析結果が確認できます。
現在タブではALLと指定しているのですべてのファイルでのCoverageを確認していますが、ControllerやModelごとにテストの割合を確認することもできます。
注意: 100%を目指さない
simplecovで網羅率100%を目指すのはほぼ無理です。あくまでテストの割合があまりにも少ないファイルがないかを視覚的にわかるようにするツールです。主機能がどこであるかや会社の方針によってsimplecovの活用方法は大きく異なると思うので、網羅率100%を目指す必要はまったくありません。
参考記事
【無職に転生 ~ 就職するまで毎日ブログ出す_29】【Rails】Integerクラスのメソッド
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
今日は久しぶりにメソッド紹介です。前まではArrayクラスやEnumerableモジュールのメソッドを紹介していて配列に関するメソッドはだいぶ覚えたのですが、数値に関するメソッドは意外と覚えていないということで、ここでしっかりと覚えていきたいと思います。ちなみに競技プログラミングなどで数値を扱うタイミングは頻繁にあるので、覚えておくと応用が聞いて便利だと思います。
Integerクラスのメソッドの種類
公式では以下のように記載されていました。当然ですが演算系メソッドが多く定義されています。

Integer#times
レシーバーの数値の数だけ繰り返し処理を行うことができるメソッドです。
5.times { puts "出力!" } 出力! 出力! 出力! 出力! 出力! => 5
競技プログラミングだと死ぬほど使います。例えば、mapメソッドと組み合わせてN回分の配列の組み合わせを取得する時などです
N = gets.to_i N.times.map {gets.split.map(&:to_i)} 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 => [[1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3]]
これは知らなかったのですが、レシーバーの数値が0以下の数値(0, -1, -2,...)の時は何も出力されず、レシーバーの数値をそのまま返却します。
1.times {puts "a"} a # 出力 => 1 # 返り値 -1.times {puts "a"} => -1 # 返り値
Integer#<=>
左辺と右辺の値を比較しそれぞれの結果に従った値を返却します。
左辺が右辺より大きい場合 ⇒ 1を返す
5<=>4 => 1
右辺が左辺より大きい場合 ⇒ -1を返す
4<=>5 => -1
左辺等辺が同値の場合 ⇒ 0を返す
5<=>5 => 0
比較できない場合 ⇒ nilを返す
5<=>"5" => nil
Arrayクラスのメソッドでもほぼ同様の挙動で定義されているようです。
[1,2,3] <=> [1,2,3] => 0
Integer#abs
引数の絶対値を返すメソッドです。
2.abs => 2 -2.abs => 2
挙動としてはこれだけです。
関連メソッドでNumericクラスからの継承でabs2というメソッドがあります。これは絶対値を二乗した数を返しています。
2.abs2 => 4 -2.abs2 => 4
以下のようにabsのまま書くことも可能です。
2.abs ** 2 => 4
Integer#digits(base)
baseを基準にしてレシーバーの数値を桁で区切って逆順にして配列にするメソッドです。baseは進数を指定します。つまり2や10、16が入ります。デフォルトでは10となっています。
少し説明では挙動がわかりにくいので実際に見てみましょう。
18.digits => [8, 1] 18.digits(2) => [0, 1, 0, 0, 1] 18.digits(16) => [2, 1]
まず引数を指定しない場合ですが、その場合はbaseが10となり10進数を基準にして配列になります。18は10進数で表されているのでそのまま18で考えます。18は桁で区切ると1と8ですね。これを逆順にして配列にすると[8, 1]になります。
次に引数が2と指定されている場合、18は二進数で10010です。これを桁区切りにしてそれを逆順にすると[0, 1, 0, 0, 1]となります。
16進数についても同様の考え方です。ただし、A、Bなどの表記はされずにそのアルファベットが表す数値となるようです。例えば、31を16進数にすると1Fですが、Fは数値として扱われるので15となります。
31.digits(16) => [15, 1]
Integer#lcm
レシーバーの数値と引数の数値の最小公倍数を求めます。最小公倍数はお互いの数値の倍数で共通の値になる最小の数です。
5.lcm(7) => 35
Integer#gcd
レシーバーの数値と引数の数値の最大公約数を求めます。最大公約数はお互いの数値を割り切ることができる最大の数です。
5.gcd(7) => 1
Integer#gcdlcm
gcdとlcmの挙動を一度に行ってくれるメソッドです。0のインデックスにはgcdの値が、1のインデックスにはlcmの値が格納されます。
5.gcdlcm(7) => [1, 35]
Integer#upto
レシーバーの数値から引数の数まで繰り返し処理を行うメソッドです。これはtimesとほぼ同じように扱うことができますが、インデックス番号を指定することができる点が強みです。例えば、timesの場合は0からレシーバーの数値-1のインデックス番号を繰り返し処理で使うことができます。
5.times {|i| puts i } 0 1 2 3 4 => 5
しかし、インデックス番号を1からスタートさせたい場合もあると思います。その時にuptoメソッッドを以下のようにして使うことができます。
1.upto(5) {|i| puts i } 1 2 3 4 5 => 1
引数の条件としては必ずレシーバーより大きい値である必要があります。もし、レシーバーの値が大きい場合、繰り返し処理は行われずにレシーバーが返却されます。
1.upto(-5) {|i| puts i } => 1
Integer#downto
downtoはuptoの逆の挙動です。レシーバーの数値から値の小さい引数まで繰り返し処理を行うメソッドです。
1.downto(-5) {|i| puts i } 1 0 -1 -2 -3 -4 -5 => 1
終わりに
毎日投稿も29日目!めちゃくちゃ続いたなと思います!ここだけの話ですが、もう実は内定を一社いただいておりまして就職するまでを期限としたこのブログ投稿ももう直ぐ終わりです。ですが、これからもブログは続けていきたいと思っているので是非ともご愛読よろしくお願いします。
ちなみにこの毎日投稿チャレンジが終わり次第本ブログへの投稿は終わりにしようと思います。このはてなブログでの投稿を終わらせ個人ブログサイトを作ってそこに投稿していこうと考えているのでよろしくお願いします。
【無職に転生 ~ 就職するまで毎日ブログ出す_26】【書籍】東大読書
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
本日はまたプログラミングではなく書籍のアウトプットになります。対等るの通り【東大読書】という、東大生などの地頭がいい人たちが行っている読書法について紹介されている本です。読んだ大感想としてはかなりアウトプット大全と内容が重なるところがあるなと思いました。また、実践方法もアウトプット大全のように今からでも実践できる方法が凝縮されているので、今日から読書するときなどにやってみるといいと思います!

著者の紹介
著者のお名前は「西岡壱誠」さんという方で当時現役の東大生が書かれた本です。「えー、東大生なんで元々頭いいからその人たちの方法なんて凡人の私たちができるの??」なんて思われるかもしれませんがご安心ください。こう言ってしまっては失礼なのですが、著者自身も実は高校三年生までは偏差値35というかなり成績の悪い学生だったそうです。ですので、著者自身も元凡人であるからこそ凡人でも使える読書術ですので安心してください。

本の構成
本の構成ですが、読書前、読書中、読書後と段階的に使えるテクニックを紹介しています。全て説明するのは大変難しいので、ギュギュっと凝縮して各段階で一つずつテクニックを紹介したいと思います。取り上げる各テクニックは下記になります。

読書前
著者である西岡さんは以下のように断言します。
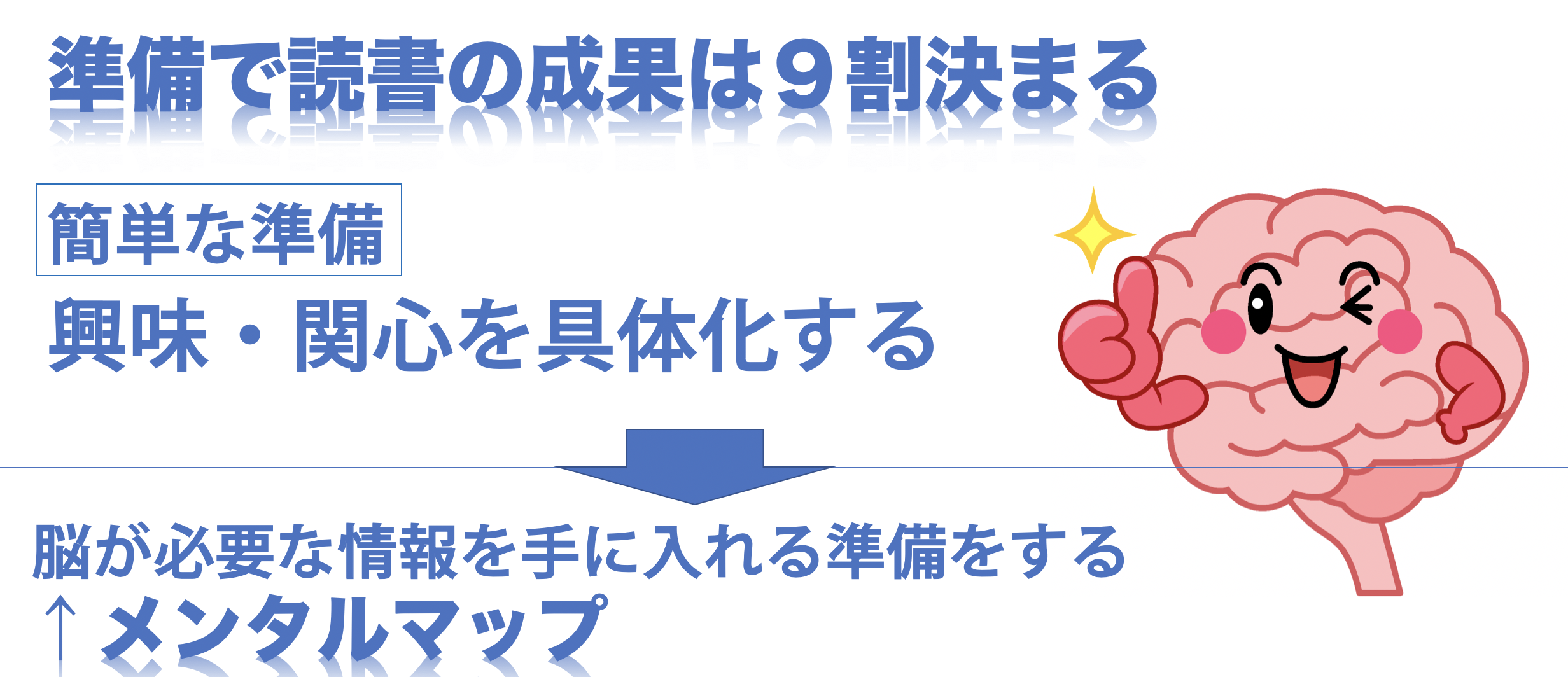
「読書前の準備でその成果は9割決まる」
なんと読書前になにをするかによってその読書から得られる成果はほとんど決まるというのです。ここでいう準備ですがさほど手間がかかる準備ではありません。その本での興味・関心ごとを具体化しておくことが準備になります。これをすることで脳が必要な情報を手に入れるための準備ができます。この脳が興味・関心ごとに対して準備されている状態のことを著者は「メンタルマップ」と呼んでいます。
メンタルマップ
この脳が興味・関心ごとについて準備している状態によって、それに関連する情報を取得することが容易になります。文字が大量にある本の中から、興味がある情報を取得することが容易にできるので読書の成果は非常に上がるといいます。
具体例を出して説明します。皆さんはYouTubeは視聴していますか?YouTubeのトップページでは自分がよく見るチャンネルや今ホットな動画などが表示されていると思います。このトップページはたくさんの動画のサムネイルで埋め尽くされており非常に情報量が多いのですが、ここでみなさんが目に入るのは最も関心ごとのあるサムネイルや文字などではないでしょうか。これは脳の中で興味が何であるかが明確に決まっているため、それに関連している事柄を自動で目で追ってしまっているわけです。なので興味関心ごとにを理解しておく事は、それに関連した情報をキャッチするような仕組みを脳に与えることができるのです。
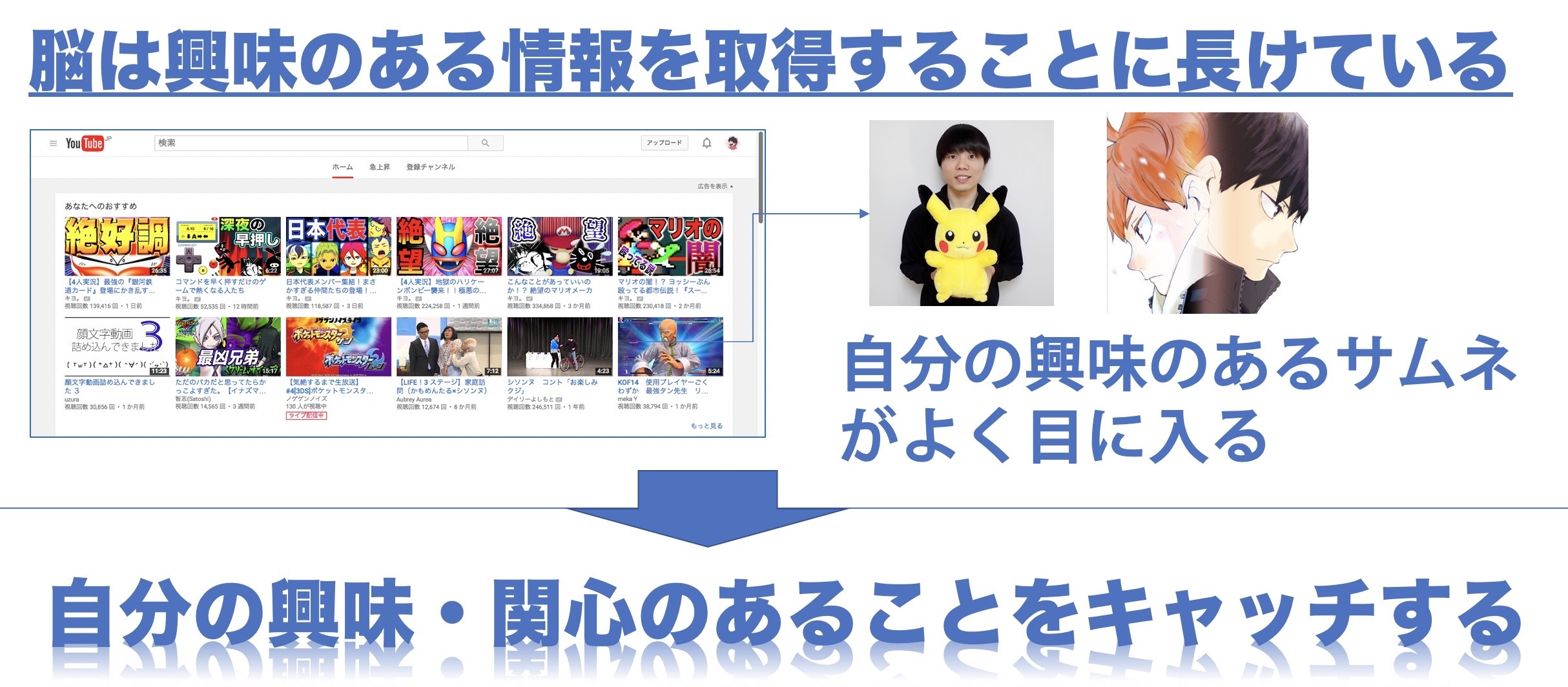
メンタルマップを作成
読書でこのメンタルマップを作成する具体的な方法として、3つのことを明確にしてメモにして本に挟んでおくことが挙げられています。
なぜその本を読むのか?(目的)
なぜその本を読もうと思ったのかを明確にしておきます。本を読む人の中には「人気だったから」「売れていたから」という理由で読書をしてしまう人もいますが、それでは興味関心が薄くメンタルマップが作成できません。しっかりとこの本の読む目的が何であるかを明確にしておくことは脳に準備をさせる上でとても重要です。なんとなくはだめです。
その本から得たい知識は?
目的を決めたら次はその目的を達成するために必要な知識を細分化します。そして、その知識が得られそうな箇所を目次から探しメモしておきます。読む箇所としてはそれだけで十分です。よく本は全部読もうとする人がいますがそれでは覚えきれません。得たい知識が書いてありそうな箇所に目星をつけて、その項目だけを読めるようにメモしておきます。
その本を読んだ後どう変化していたいか?
その本を読んだ後どうなっていたいのかを明確にします。目的が叶ったらどうなっているのかを書くので目的が具体的であればすぐにかけると思います。ここで読書後の変化を書く理由としてはどこで読書を終了するのかを準備できるためです。本で得た知識を使って自分が読書後に思い描いていた自分になれているのであればそれはもうその本からは十分に知識を得たという指標になります。

読書中
読書中に行うテクニックとして、2つの本を読むことが挙げられています。ここで2つの本は必ず類似している内容にします。例えば、今回読んでいる本であれば以下の本と組み合わせるといいと思います。
ここで内容が同じである本を読むことにメリットとしては2つあると西岡さんはおっしゃっています。
- 客観的思考力が身につく
- 質の高い復習ができる
客観的思考力が身につく
客観的思考力とは一つの意見に囚われないことです。一つの本だけで読書をしてしまうと、その著者1人の意見 = 真であるということを鵜呑みにしてしまいます。著者の意見を取り入れることしかできないため、インプットの質も高くないです(受動的インプット)。しかし、二つの類似した本を読むことで本同士の意見を比較することができます(能動的インプット)。これにより、1人の著者が行っていることを鵜呑みにせず別の著者では別のことを言っているのか、またはそれに付随する意見を述べているのかを確認することができます。この二つの意見を比べる本の読み方を検証読みと著者は行っています。

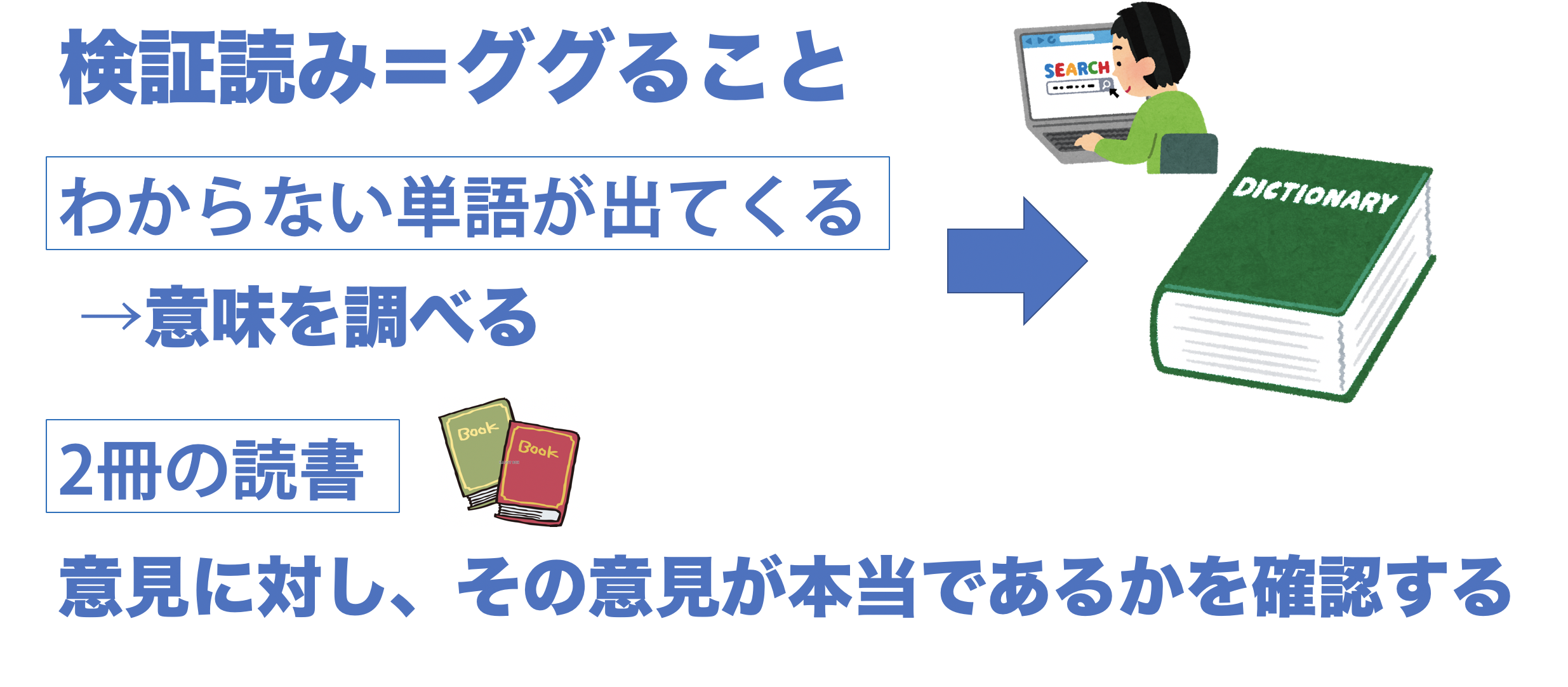
検証読み
検証読みと聞き慣れないことですが、実は普段日常で私たちはこれをやっています。それは「ググる」です。検証読みとはつまりググることです。
例えば、英単語の勉強をしているとします。わからない発音が出てくるとその単語の発音がどんなものなのか確認しますよね。そうすることで正しい知識かどうかを確認します。これは検証読みでも同じことをしています。片方の本が正しいかどうかを確かめるために別の本でググって確認しています。なので全く私たちがしたことがないことかと言われると実はそうではないのです。
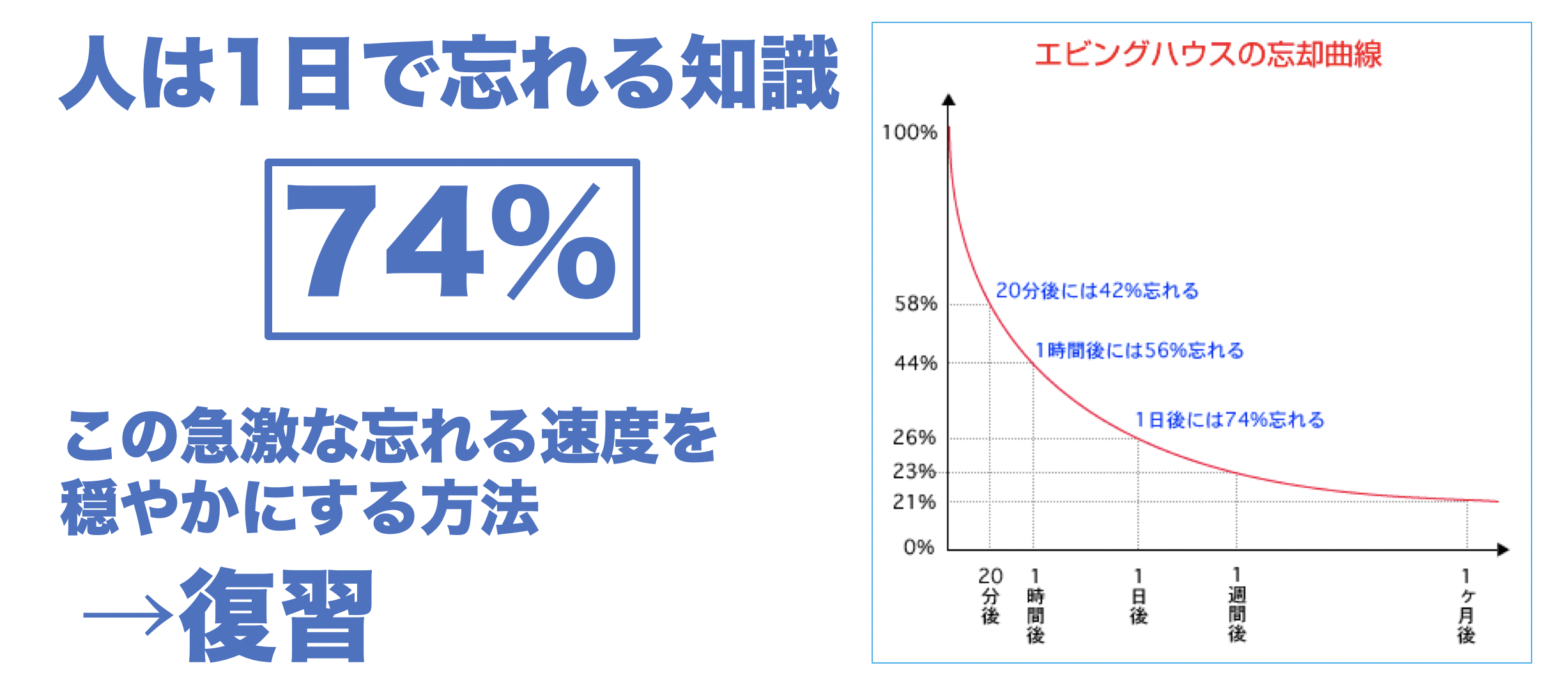
質の高い復習ができる
二つの本を同時に読むメリットの2点目は「質の高い復習ができる」ことです。人は1日で74%のことを忘れると言います。エビングハウスの忘却曲線というグラフがあり、多くのこととを忘れてしまうようにできているのです。そしてこの曲線を緩やかにする方法が復習です。
そして二冊の本を読む事は非常に質の高い復習です。同じ本を繰り返し読むよりも、違った文脈で復習した方が記憶に定着するのです。具体例としては、バイト先でよく来る常連のお客さんがいるとします。このお客さんへの印象は「ただの常連客」です。しかし、街中でこの人を見かけると途端にこの人への印象が強くなると思います。このように同じ内容でも違ったコンテキストであればより人は記憶できるようになっています。言い換えるとこれは、最も質の高い復習は「同じようなことが前にもあったという感覚」です。
読書後
読書をして当初目的としていた知識も得たので満足したで終わりにしてはいけません。必要な箇所だけを読んだとしても、得た情報量は非常に膨大であるはずです。この膨大な情報を要約してより自分が覚えたことが何だったのかを明確にする必要があります。
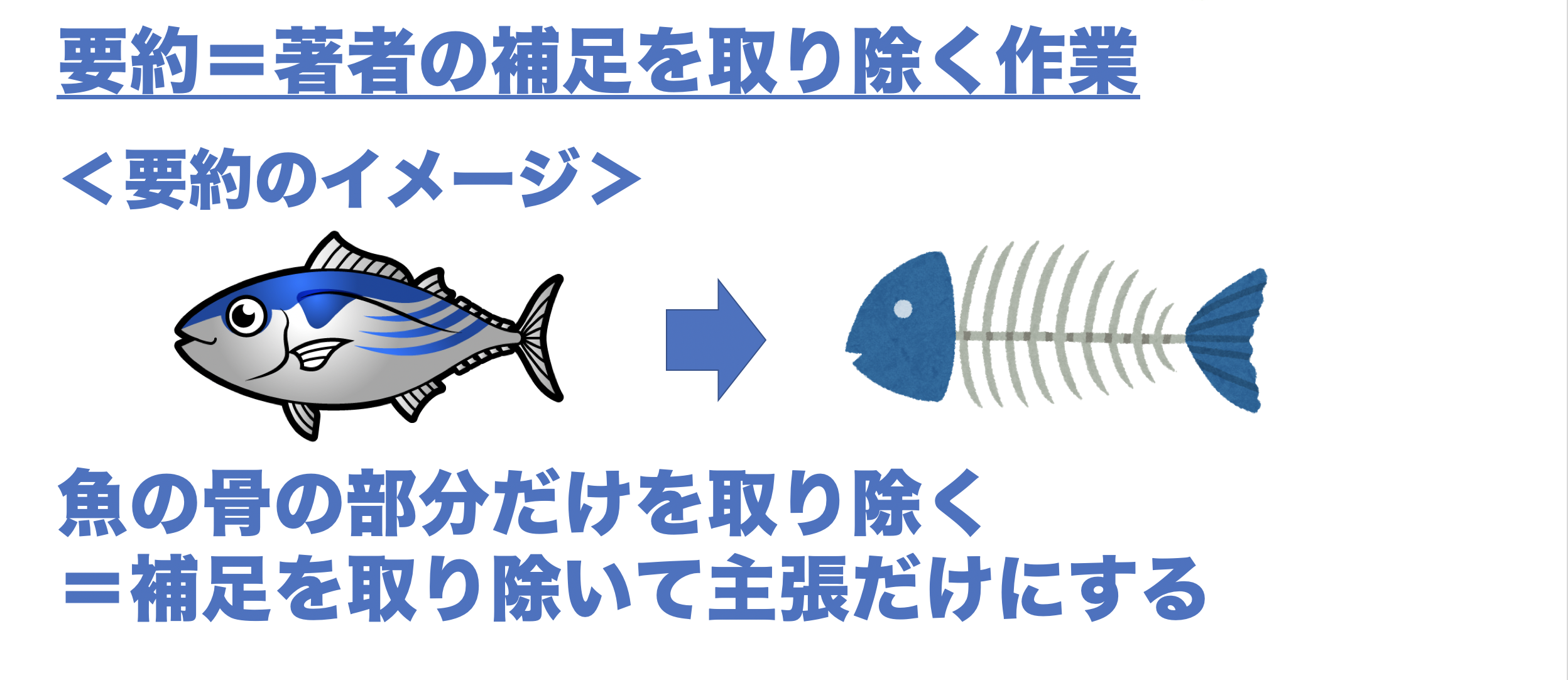
要約とは著者の補足を取り除く作業です。イメージとしては魚のみを取り除く作業が合っていると思います。魚の骨の部分が主張部分ですのでそれに関連する補足部分などの魚の身を取り除くというのがわかりやすい例えなのかなと思います。
要約の意義
要約って時間かかるし意味あるのかなと思うかもしれませんが、非常に効果的な作業です。むしろ今まで時間をかけて本を読んだことが要約をしないことで意味がなくなってしまいます。
これまで長い時間をかけて読んだのでもう十分知識は定着していると思うかもしれませんが、実はそうではありません。確かに読書を通して膨大な情報には触れました。しかし、この知識はただの知識であり、それをどう応用するかまでは本に書いてありません。それはあなた自身が決めることです。その膨大な情報から使える知識を取り除き自分の生活にどう応用するのかをまとめることで初めて得た知識は意味がある使える知識となります。

要約の流れ
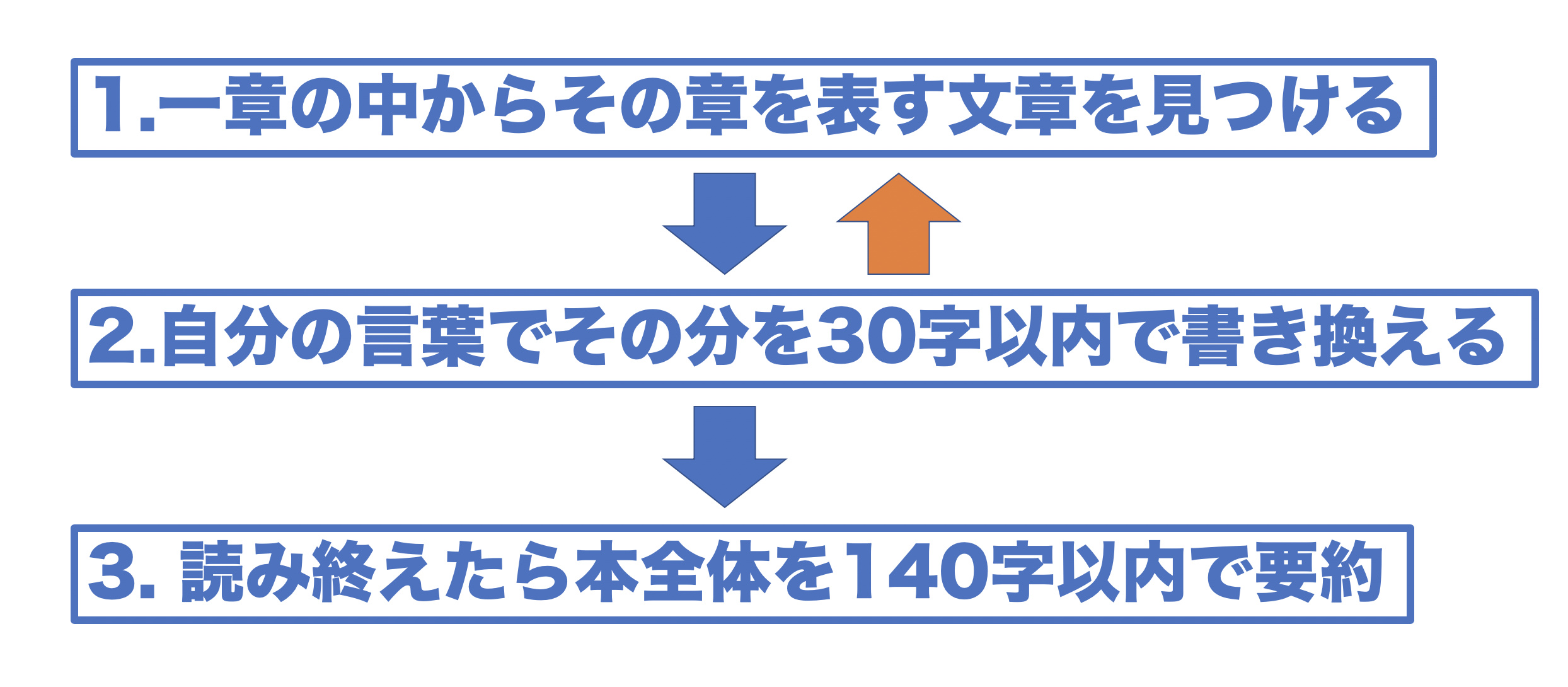
要約の流れとしては以下のようになります。
まず一章の中からその章を具体的に表している文を見つけます。そしたら、その文を30字以内で書き換えてください。やってみればわかるのですが30字はすごく短いです。何万字にも渡って書かれている章をたったの30字にするのですから。ですが、心を鬼にして削れるだけ削りましょう。これを各章ごとに繰り返し最後にそのまとめたものを140字で要約してみてください。これで本の要約は終わりです。要約を見据えて本を読むのであれば、読書中にその章を表していそうな部分をマークしておきましょう。
終わりに
東大読書と言ってもマインドマップの作成、2冊読むこと、要約などは誰しもができるテクニックです。この本の中で紹介されているテクニックはほとんどが同様に誰でもできるものです。本を読むことだけに集中するのではなく、その本をどのように活用するか、何が目的であるか、どう復習するかをしっかりと決めた上で読めば、きっとこれまでの読書とは比べ物にならないくらい記憶に残る読書ができるのではないでしょうか。
【無職に転生 ~ 就職するまで毎日ブログ出す_28】【Rails】assign_attributes
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
assign_attributesという今まで自分が使ったことがないメソッドを使う機会がありましたのでシェアしたいと思います。なお、今回は1つのメソッドのみの記事ですのでだいぶ短くなるかと思いますがご了承ください。
assign_attributes
下記のサイトでは以下のように説明されています。
assign_attributes特定のattributeを変更するためのメソッドです。 attributes=と同じくDBには保存しません。
attributeとはつまり属性です。インスタンス変数ということで間違いありません。引数にはハッシュの値を引数としてレシーバーの属性を変更します。
article.assign_attributes({ title: "Hoge", body: "this is content" })
しかし上記の状態ではDBに保存されていません。なので上記の処理の後にDB保存をする処理をしなければいけません。
article.save!
assign_attributesの使い所
上記の処理を見ると、updateメソッドで1行で書くことができるのがわかると思います。
article.update!({ title: "Hoge", body: "this is content" })
そのため、どこでassign_attributesを使うのだろうと思うかと思います。
使い所としてはupdateアクションで更新処理を一度に行いたくない場合が挙げられると思っています。例えば、前回実装したタグ機能の記事で作成機能を実装しました。
【無職に転生 ~ 就職するまで毎日ブログ出す_25】【Rails】【タグ機能】Materialize のChipsで値をコントローラーに送る方法 - 大ちゃんの駆け出し技術ブログ
class PostController < ApplicationController def create @post = Post.new(post_params) if @post.save_with(tag_names) redirect_to @post, notice: t('.success') else flash.now[:alert] = t('.fail') render :new end end private def post_params params.require(:post).permit(:name, :body) end def tag_names params[:post][:tag_names].split(' ').uniq end end
この記事では実装しませんでしたが、タグ機能なので更新処理も実装する必要がありました。その際に問題だったのが、タグを保存する前に記事を更新しないように制御する必要がありました。例えば、createアクションと同じようにupdateアクションも作ってみます。
def update @post.update(post_params) if @post.save_with(tag_names) redirect_to @post, notice: t('.success') else flash.now[:alert] = t('.fail') render :edit end end
2行目を見るとわかるのですが、updateアクションが実行されるため先に投稿が保存されてしまいます。その後タグを更新する処理が走るようになっていますね。なのでタグの更新に失敗ても、投稿の内容は更新されてしまう処理が走る可能性があります。
ここでupdateアクションをタグ保存時に行う方法もありますが、それだとsave_with(tag_names)メソッドの中身を変える必要があり、作成時と更新時で処理を分ける必要があります。よって少し冗長なコードができてしまいます。
ここで登場するのがassign_attributesメソッドです。既に作成されているインスタンス変数にDBの保存を介さずに値を変更することができるため、下記のようにすればタグ作成機能と同様にタグと同時に投稿が保存される処理が走るようになります。
def update @post.assign_attributes(post_params) if @post.save_with(tag_names) redirect_to @post, notice: t('.success') else flash.now[:alert] = t('.fail') render :edit end end
これによってコードが冗長になることを防ぎます。今のところ自分が思いついた活用シーンがこれぐらいしかなかったのですが、覚えておいて損はないのかなと思いました。
update_all
ついでに記事の中でupdate_allというメソッドを見つけたのでこちらもシェアします。と言ってもかなり簡単です。ですが便利だと思いました。
レシーバーがインスタンス変数の配列で、それらの値を一気にまとめて更新したいときに使われるメソッドです。
Article.where(status: 'deleted').update_all(title: '[deleted]')
SQLで更新処理を行う際は、値の更新範囲は一つではなく複数個もありえます。例えば、以下のようなSQLだと全ての従業員の名前が自分と同名になってしまいます笑
UPDATE employees SET name = 'DAIKI'
そのため、WHERE句を使って更新範囲を狭めますが、それでも複数個の更新はあり得ますね。下記は無理やりですが、、。
UPDATE employees SET name = 'DAIKI' WHERE age > 18
しかし、複数のレコードを意図的に更新したい事はよくあることだと思います。
updateメソッドではレシーバーは必ず一つのオブジェクトでないといけません。その役割を果たすメソッドとして、複数の更新を行うことができるupdate_allメソッドがあるわけです。
終わりに
毎日投稿も28日目!めちゃくちゃ続いたなと思います!ここだけの話ですが、もう実は内定を一社いただいておりまして就職するまでを期限としたこのブログ投稿ももう直ぐ終わりです。ですが、これからもブログは続けていきたいと思っているので是非ともご愛読よろしくお願いします。
ちなみにこの毎日投稿チャレンジが終わり次第本ブログへの投稿は終わりにしようと思います。このはてなブログでの投稿を終わらせ個人ブログサイトを作ってそこに投稿していこうと考えているのでよろしくお願いします。
参考記事
【無職に転生 ~ 就職するまで毎日ブログ出す_25】【Rails】【タグ機能】Materialize のChipsで値をコントローラーに送る方法
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
チーム開発でタグ機能を実装する機会があったので、Gemなしでタグ機能を実装していきたいと思います。プロジェクトはプライベートリポジトリであるため、全てのコードをお見せすることはできませんが、基本的には流れなどがわかれば問題ないのかなと思っています。タグ機能を作成する際に少し手間取ったのが、Materialize CSSを使用した値の送信方法です。今回はそれがメインなのでタグ機能はほぼサブと考えてください。
タグ機能のER図
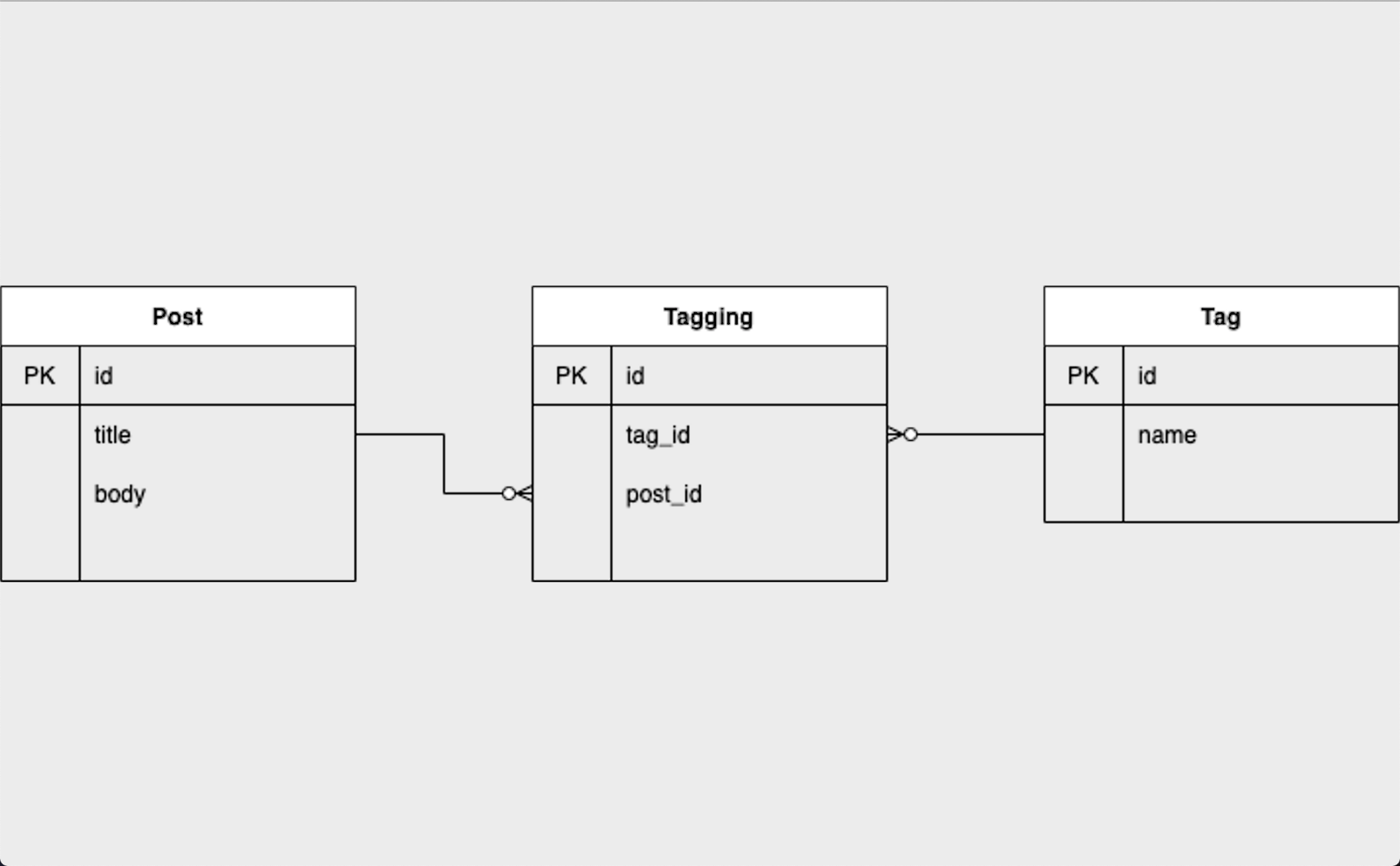
今回作成するタグ機能ではQiitaなどで使われるタグの機能です。なのでタグをつけるオブジェクトはPost(投稿)とします。
Postは複数のタグを持っていますね。Qiitaでも一つの投稿に複数のタグをつけることができます。そしてタグも複数の投稿に属しています。Qiitaでも複数の投稿が"Ruby"というタグをつけることができます。よってタグ機能の実装はいいね機能やフォロー機能と同じように多対多のアソシエーションの関係になります。
Postモデルにはtitleカラムとbodyカラムが元々あります。そこに新規モデルでTagモデル、中間テーブルであるTaggingモデルを作成します。
モデルの作成
タグ機能のためのモデルを作成します。まずはTagモデルです。
$ rails g model tag name:string Running via Spring preloader in process 79374 invoke active_record create db/migrate/20211024010225_create_tags.rb create app/models/tag.rb
nameカラムは空値を入れることができないように制御します。さらにタグの名前は重複しないようにadd_indexでnameカラムに一意性制約をかけます。
# db/migrate/xxxxxxxxxxxx_create_tags.rb class CreateTags < ActiveRecord::Migration[6.1] def change create_table :tags do |t| t.string :name, null: false t.timestamps end add_index :tags, :name, unique: true end end
続いて中間テーブルの役割であるTaggingモデルも作成しましょう。
$ rails g model tagging post:references tag:references
同じ投稿に対して同一のタグが付かないように、tag_idとpost_idの組み合わせは一意であるように制約をかけます。
# db/migrate/xxxxxxxxxxxx_create_taggings.rb class CreateTaggings < ActiveRecord::Migration[6.1] def change create_table :taggings do |t| t.references :post, null: false, foreign_key: true t.references :tag, null: false, foreign_key: true t.timestamps end add_index :taggings, %i(tag_id post_id), unique: true end end
よく見直して問題がなけれマイグレーションします。
$ rails db:migrate
続いて各モデルファイルにアソシエーションとバリデーションを記載します。
# app/models/post.rb class Post < ApplicationRecord has_many :taggings, dependent: :destroy has_many :post_tags, through: :taggings, source: :tag end
# app/models/tag.rb class Tag < ApplicationRecord has_many :taggings, dependent: :destroy has_many :tagged_posts, through: :taggings, source: :post validates :name, presence: true, uniqueness: true end
# app/models/tagging.rb class Tagging < ApplicationRecord belongs_to :post belongs_to :tag validates :tag_id, uniqueness: { scope: :post_id } end
フォームを編集
タグ作成機能はTagControllerを経由してタグが作成されるのではなく、Post作成時にタグも同時に作成されるので、Post作成機能のフォームに作成するタグを記載します。
※ 現在既にPost作成機能のためのフォームがあるとします。
<div class="field"> <%= form.label :tag_names, class: 'form-label' %> <%= form.text_field :tag_names, class: 'form-control', placeholder: '空白スペースで区切って入力してください' %> </div>
tag_namesはpostのカラムではありません。form.labelを機能させるためにi18nファイルに対してtag_namesに対応する日本語を指定しましょう。
# config/locales/activerecord/ja.yml post: title: タイトル body: 本文 tag_names: タグ
入力形式としては空白区切りでタグが入力されるようにします。以下のように入力した場合、「タグサンプル1」と「タグサンプル2」のタグが作成されます。

コントローラーを編集
こちらも既に実装済みであるPost作成機能を上書きする形で実装します。下記のようなシンプルな形式です。
class PostController < ApplicationController def create @post = Post.new(post_params) if @post.save redirect_to @post, notice: t('.success') else flash.now[:alert] = t('.fail') render :new end end private def post_params params.require(:post).permit(:name, :body) end end
上記の処理にタグを作成する処理を加えます。まず、タグの値がパラメーターとして渡ってきています。
params[:post][:tag_names] => "タグサンプル1 タグサンプル2"
上記の値では空白で値が連結されているため、空白区切りで値を分割した配列に変更します。splitメソッドを使えば実装できます。
params[:post][:tag_names].split(' ') => ["タグサンプル1", "タグサンプル2"]
さらにタグの値の重複を防ぐ必要があるのでuniqメソッドも使います。
params[:post][:tag_names].split(' ') => ["タグサンプル", "タグサンプル"] params[:post][:tag_names].split(' ').uniq => ["タグサンプル"]
これを一つのprivateメソッドにまとめておきます。
def tag_names params[:post][:tag_names].split(' ').uniq end
上記の値を使用してタグを作成する処理を書きますが、コントローラーにロジックを長く書くのは好ましくないため、postモデルにロジックを移すようにします。save_withメソッドと記載しておいてロジックはモデルで記載します。
class PostController < ApplicationController def create @post = Post.new(post_params) if @post.save_with(tag_names) redirect_to @post, notice: t('.success') else flash.now[:alert] = t('.fail') render :new end end private def post_params params.require(:post).permit(:name, :body) end def tag_names params[:post][:tag_names].split(' ').uniq end end
モデルでsave_withメソッドのロジックを書きます。先に処理は書いておきます。
def save_with(tag_names) ActiveRecord::Base.transaction do self.post_tags = tag_names.map { |name| Tag.find_or_initialize_by(name: name.strip) } save! end true rescue StandardError false end
ActiveRecord::Base.transactionは複数のSQL処理を一つのトランザクションにまとめる時に使用します。これを使う理由としてはタグとPostが同時に作成される処理のため、複数のSQLが走ると予想されるからです。
Tag.find_or_initialize_by(name: name.strip)の処理ですが、find_or_initialize_byは作成するタグの値が既に存在していればそのタグを返し、存在していなければインスタンスかするメソッドです。それによってタグの名前が重複することを防ぎます。
最後にsave!メソッドで保存します。ここでもしバリデーションエラーとなれば、トランザクションがロールバックし作成されたタグなども作成されなかったことになります。そして例外処理でfalseを返すようにしています。
これで無事にタグ作成機能ができました!
入力UIの向上
今回タグ作成機能を作るにあたりフォームを空白区切りとしましたが、フォームを入力する時が非常に簡素です。本来タグ入力は下記のようなUIの方がわかりやすいですよね。

Materialize CSS Chips
以下のような可愛らしいタグをデザインしてくれるMaterialize CSSの機能です。
これでタグを入力できたらかなりUIが向上すると思ったので今回導入してみました。
フォーム編集
それでは導入してみます。
Materialize公式を参照すると下記のようにすれば実装できるそうです。chipsクラスの中にinputフォームがあればいいそうです。
<div class="chips"> <input class="custom-class"> </div>
$('.chips').chips();
これに倣って前回作成したタグのフォームを修正します。text_fieldはinputタグに変換されるのでそのままにして、それを囲うdivタグにchipsクラスを付けます。
<div class="chips"> <%= form.label :tag_names, class: 'form-label' %> <%= form.text_field :tag_names, class: 'form-control', placeholder: '空白スペースで区切って入力してください' %> </div>
$('.chips').chips();
ただこれだと入力ができませんでした。正確には入力はできるのですが、エンターを押してもchipsとして表示されません。入力してエンターを押せばchipsとして表示されるはずなのですが、、、

これは下記issueに上がっていました。
When initializing a div with the
chipsclass, if there is a label in that div, the init function raises a TypeError.
Chips init function throws TypeError when there is a label · Issue #6124 · Dogfalo/materialize
どうやらchipsの中にlabelがあるとエラーとなるそうです。なので不格好ではありますが下記のようにlabelをdivタグの外に出してしまいます。
<%= form.label :tag_names, class: 'form-label' %> <div class="chips"> <%= form.text_field :tag_names, class: 'form-control', placeholder: '空白スペースで区切って入力してください' %> </div>
これでエンターで入力できるようになりました。しかも、同じ値は入力できないようにしてくれています。

chipsの値をコントローラーに送る
これでフォームに送信できるようになったのかというとそうではありません。実際に試してみるとわかるのですが、値が送られていないのです。
理由としてはchipsの仕様にあります。実は作成されたchipsはフォームのバリューになっているのではなく、divタグの中にchipクラスとして追加されているのです。下記のgifを見ると分かるのですが、chipクラスを持つdivタグがどんどん作成されています。しかし、これらの値はinputフォームのバリューとなっていないため、入力した値を送ることができていないのです。
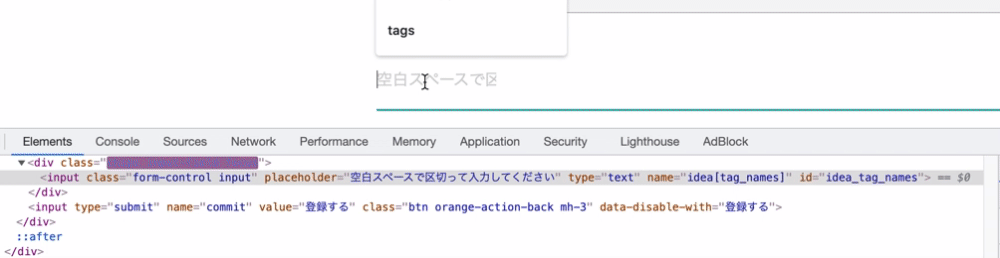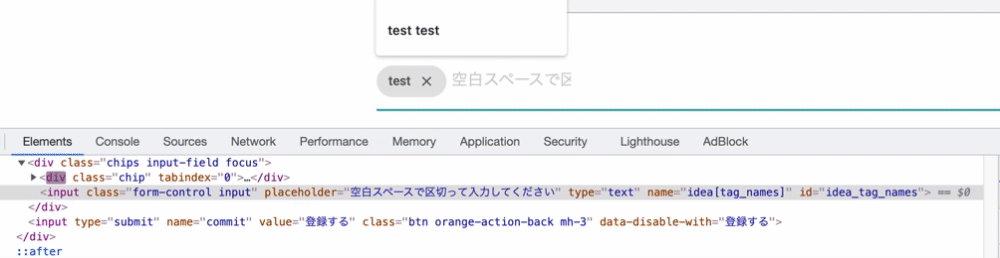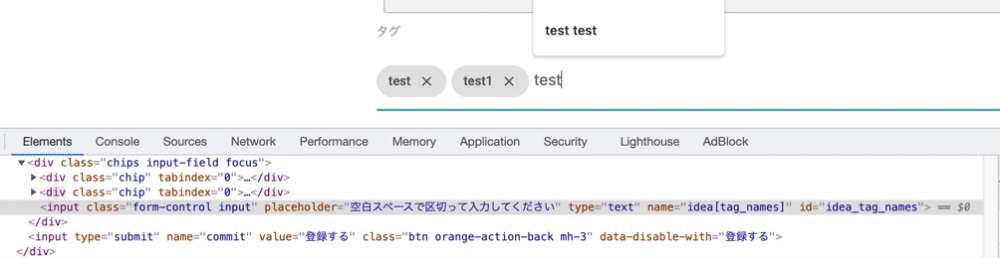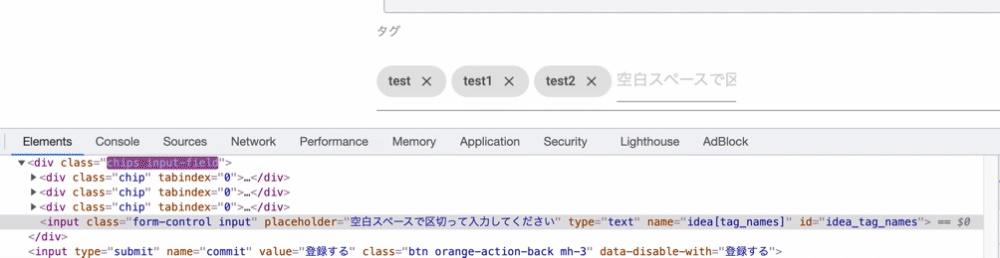
よってこの作成されたchipsを値として取得しコントローラー側にパラメータを送る必要があります。そのためにはJavaScriptでchipクラスの値を取得してそれを送信する際にフォームのバリューに設定することで解決できます。
まずフォームを整理します。結論から言うとタグの部分は下記のように実装します。
<div class="field"> <%= form.label :tag_names %> <div class="chips"><input></div> <%= form.hidden_field :tag_names, id: 'tag-hidden-field' %> </div>
タグを入力する部分にtext_fieldではなく直接inputを使用する理由は、後ほどJavaScriptでフォームに値を入れる時にその挙動がユーザー側に見えてしまうのを防ぐためです。今回実装する挙動として「作成ボタンをクリック」 ⇒ 「JSでフォームにバリューを入れる」なのですが、もしtext_fieldの中に入れてしまうと送信ボタンをクリックした時に一瞬chipクラスの値が見えてしまうのでとても不自然なUIになります。よって、text_fieldに入れるのではなく、hidden_fieldにバリューを格納することで上記のような不自然な挙動を制御します。
次にJavaScriptのコードを実装します。今回自分はjQueryを使っていたのでjQueryのコードになりますがJSでも問題なく実装できると思います。
$(".chips").chips({
placeholder: "Enterで入力",
secondaryPlaceholder: "+Tag",
data: getChipsData($("#tag-hidden-field").val()),
});
// chipsの初期データを取得するメソッド
function getChipsData(values) {
return !values
? []
: values.split(",").map(function (value) {
return { tag: value };
});
}
// 作成時にchipsの値をフォームに格納
$("#idea-btn").on("click", function () {
const tags = M.Chips.getInstance($(".chips")).chipsData.map(function (
value
) {
return value["tag"];
});
$("#tag-hidden-field").val(tags);
});
まず初期化コードを確認します。
$(".chips").chips({
placeholder: "Enterで入力",
secondaryPlaceholder: "+Tag",
data: getChipsData($("#tag-hidden-field").val()),
});
secondaryPlaceholderとはchipを一度作成した後にフォームに表示されるプレイスホールダーです。下のgifを見るとわかるように、最初はplaceholderが表示されていますが、一つchipを作成するとsecondaryPlaceholderがプレイスホールダーとして表示されます。

dataプロパティは初期状態で作成されているchipクラスのdivタグを設定できます。ここではgetChipsDataメソッドを独自で定義しています。これは今回の実装ではあまり意味がないのですが、更新機能を作成する際に既にタグが作成されている時に初期状態でそれらのタグを表示することができるので便利です。
// chipsの初期データを取得するメソッド
function getChipsData(values) {
return !values
? []
: values.split(",").map(function (value) {
return { tag: value };
});
}
ボタンが作成された時の挙動は先ほど説明した通りです。M.Chips.getInstance($(".chips")).chipsDataでchipsのなかのchipの配列を取得することができます。それに対してmapメソッドでvalue["tag"]から値を取り出してその配列をフォームのhidden_fieldに送っています。
// 作成時にchipsの値をフォームに格納
$("#idea-btn").on("click", function () {
const tags = M.Chips.getInstance($(".chips")).chipsData.map(function (
value
) {
return value["tag"];
});
$("#tag-hidden-field").val(tags);
});
終わりに
これによりMaterialize CSSを使用してタグの作成ができるようになります。正直hidden_fieldにvalueを渡す方法はベストプラクティスとは思っていません。かなりゴリ押しだと思っています。
<div class="field"> <%= form.label :tag_names %> <div class="chips"><input></div> <%= form.hidden_field :tag_names, id: 'tag-hidden-field' %> </div>
よりいい方法がないか模索していきたいなと思いますのでアップデートがあればまた記事にします。
【無職に転生 ~ 就職するまで毎日ブログ出す_27】【番外編】よく使う拡張機能 & ツール
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
本日はプログラミングであると便利なChromeの拡張機能やツールについてご紹介します。これを知っているのと知っていないのでは開発の効率が全然違うと思っているので、使ったことがない人はぜひ一度試しにインストールしてみてください。
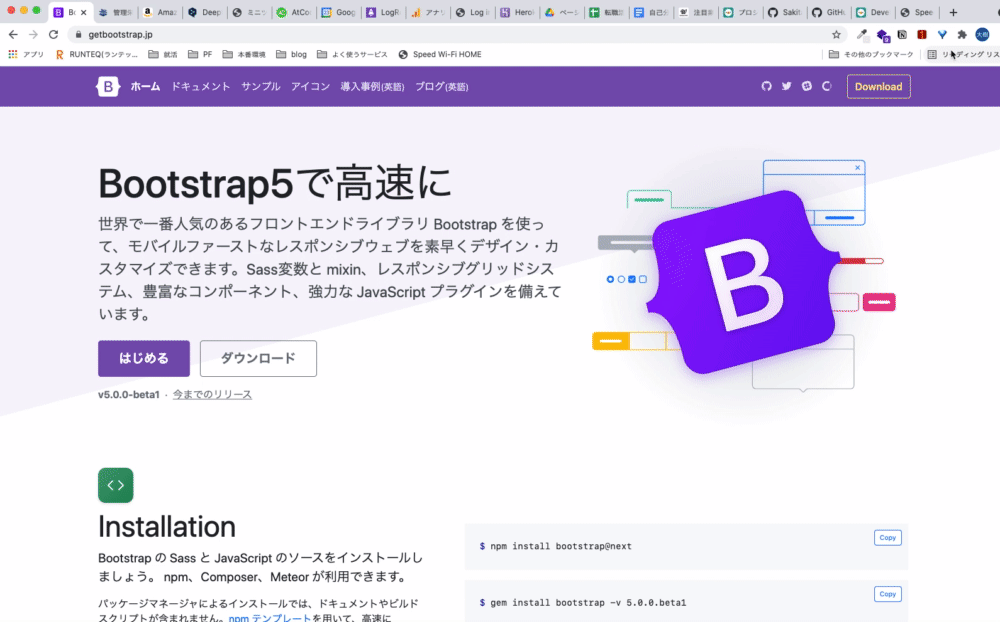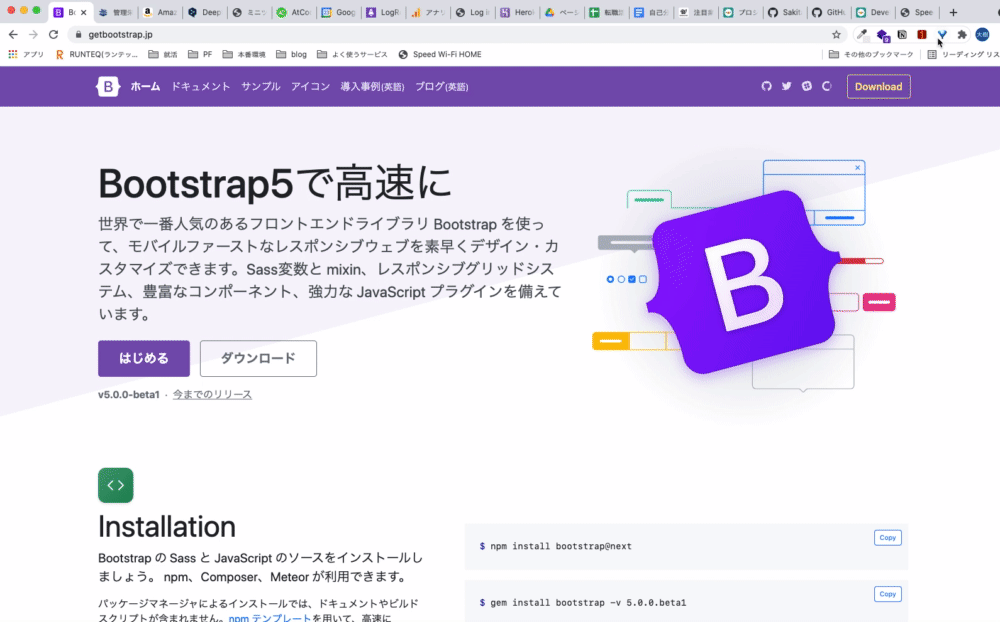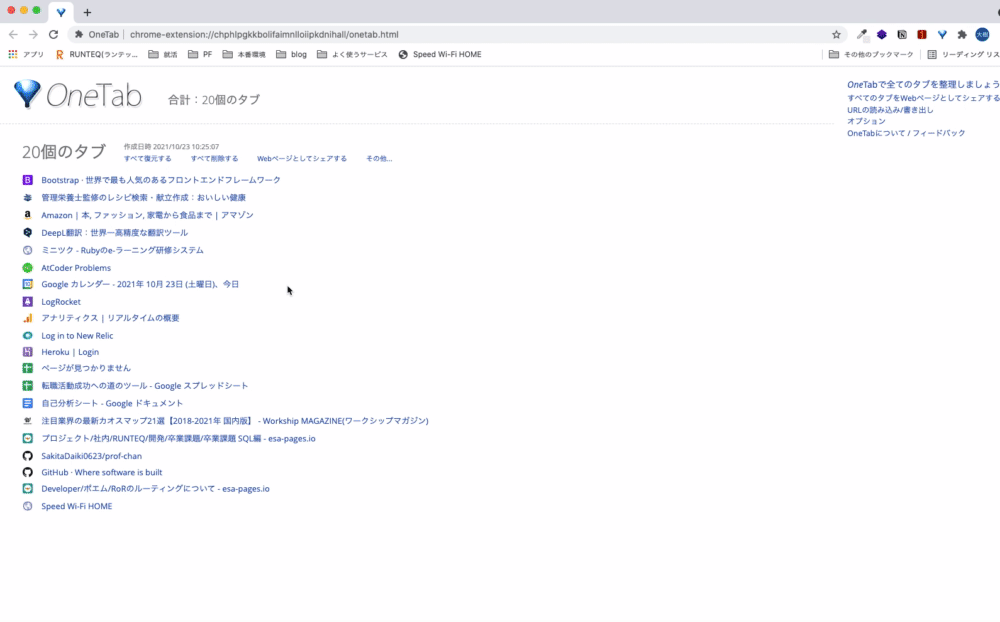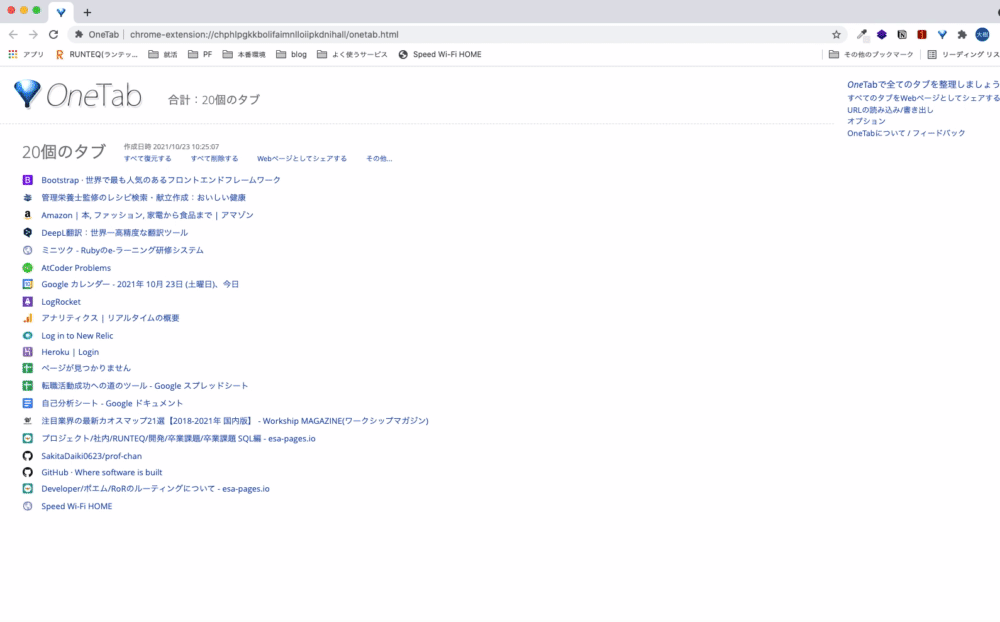
OneTab
エンジニアで仕事をしているとググることが非常に多く、たくさんのタブを開いてしまうかと思います。

この状態ではどのタブに何があるのかがわからないため、いちいちタブを開いてページを確認しなければならず非常に手間です。
OneTabは現在開いているタブを一つのタブにまとめてリスト表示してくれる拡張機能です。タブをいちいち全て閉じる必要がなくなり、また、現在開いているタブが見やすくなるのでとても便利です。
Wappalyzer
現在開いているサイトの使用技術などがわかる拡張機能です。
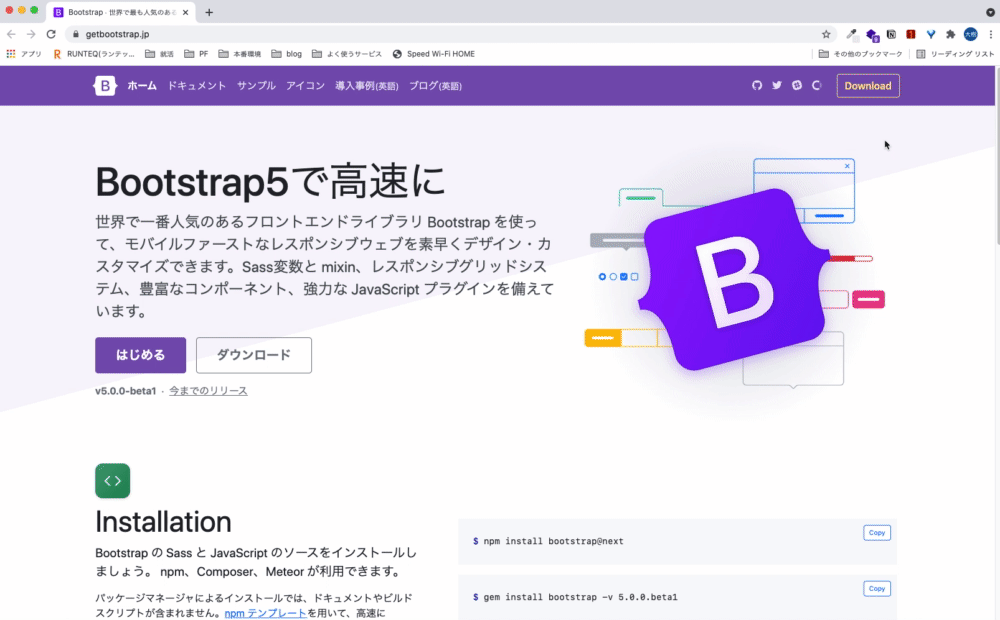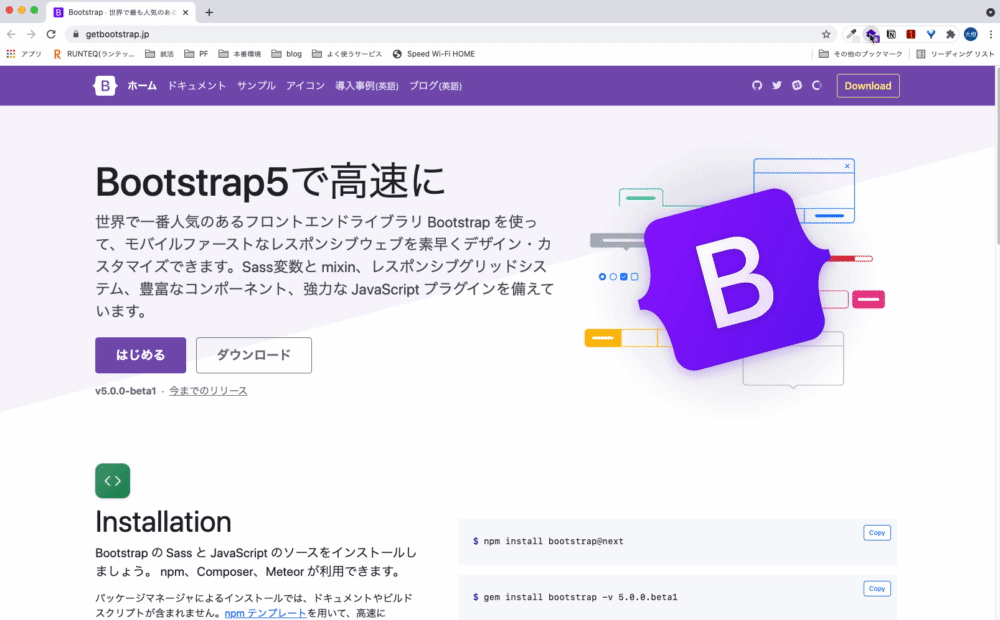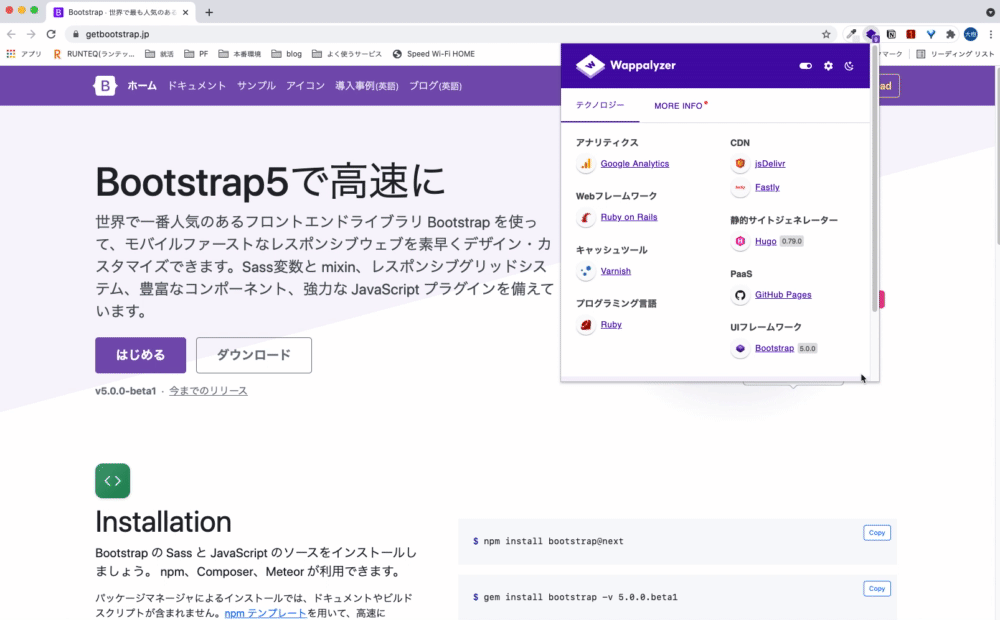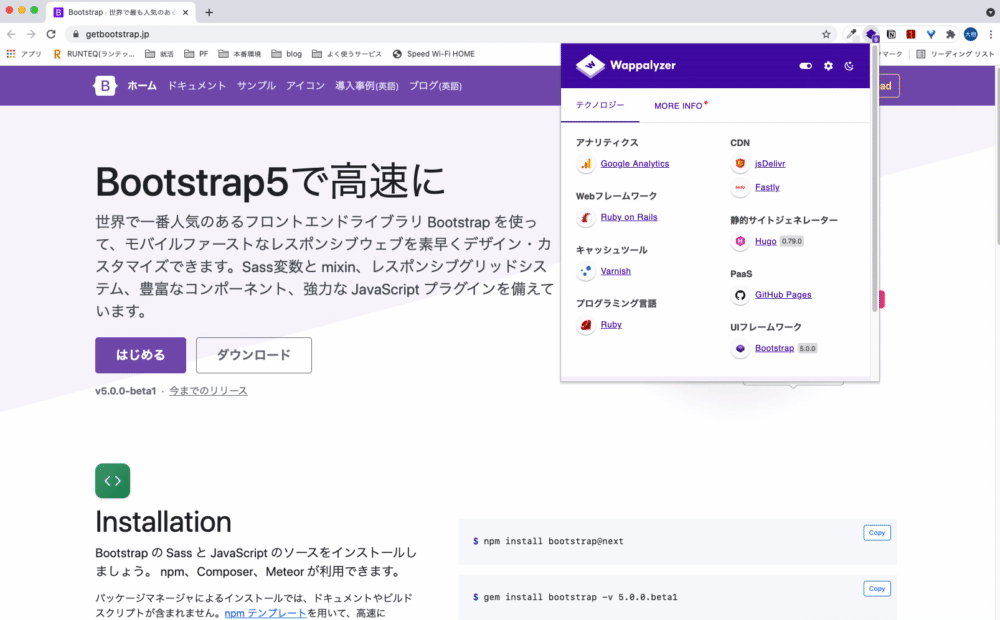
未経験エンジニアでは使う機会は限られてくると思うのですが、将来エンジニアになった際には技術をハックする際に使えそうな拡張機能です。また、就活時に志望企業の自社サービスにこの拡張機能を使用することで、志望企業サービスの技術スタックを明確にすることができます。
Responsive Viewer
開発でレスポンシブデザインを実装する際に全ての画面サイズを一度に確認できる拡張機能です。
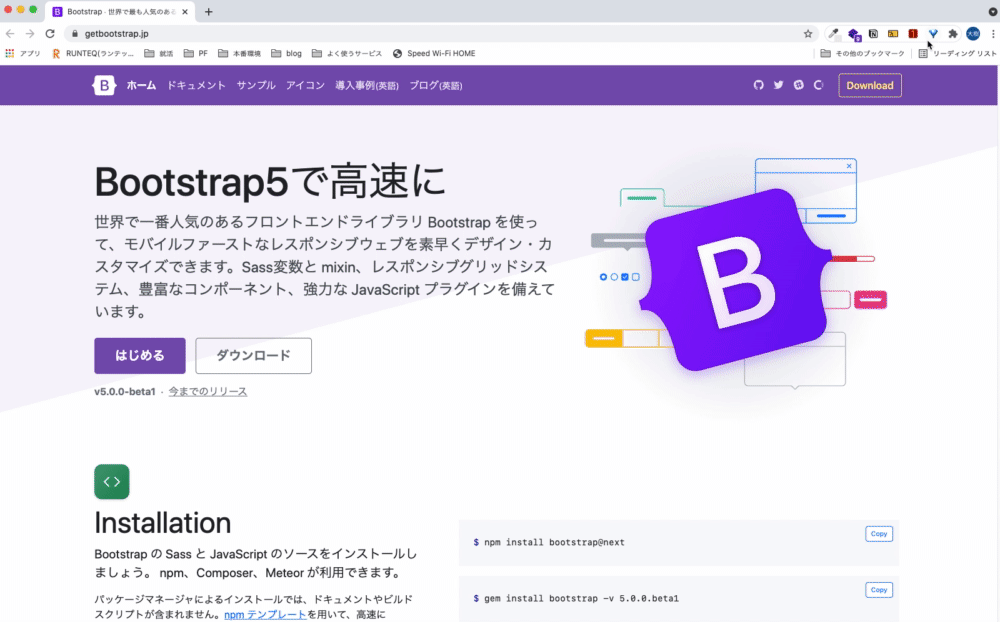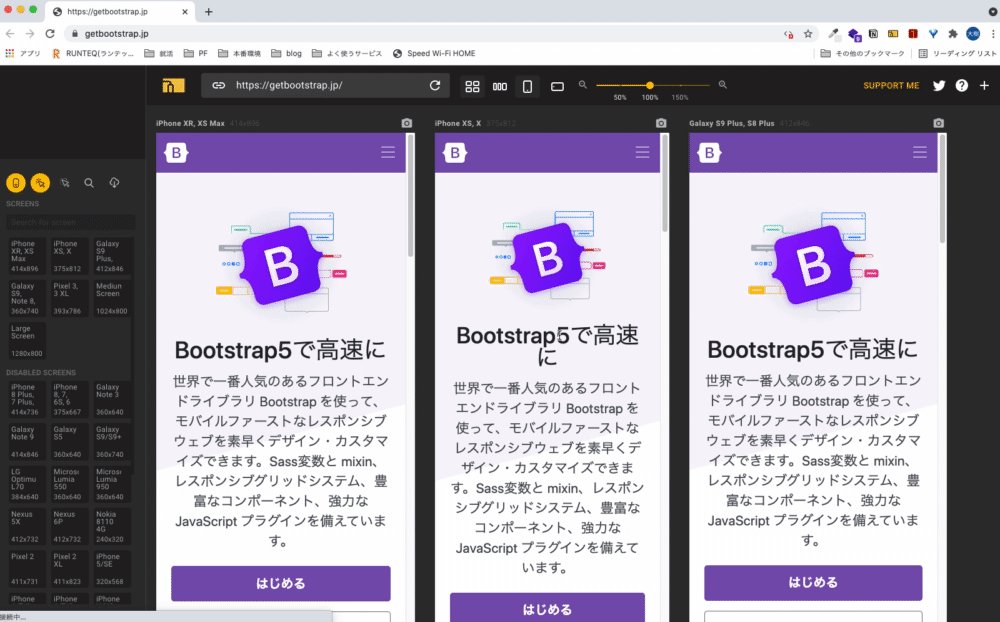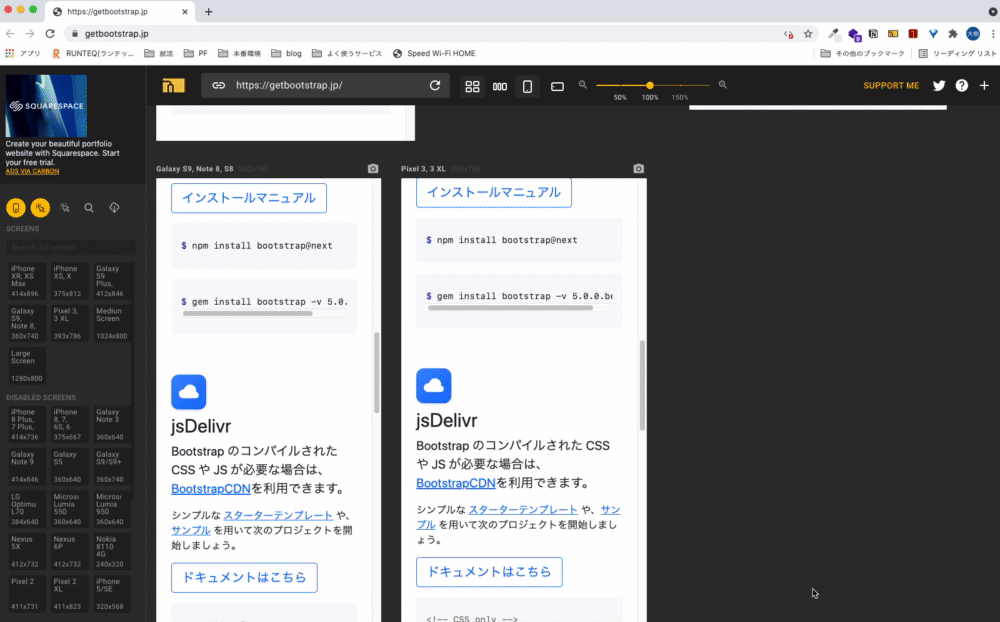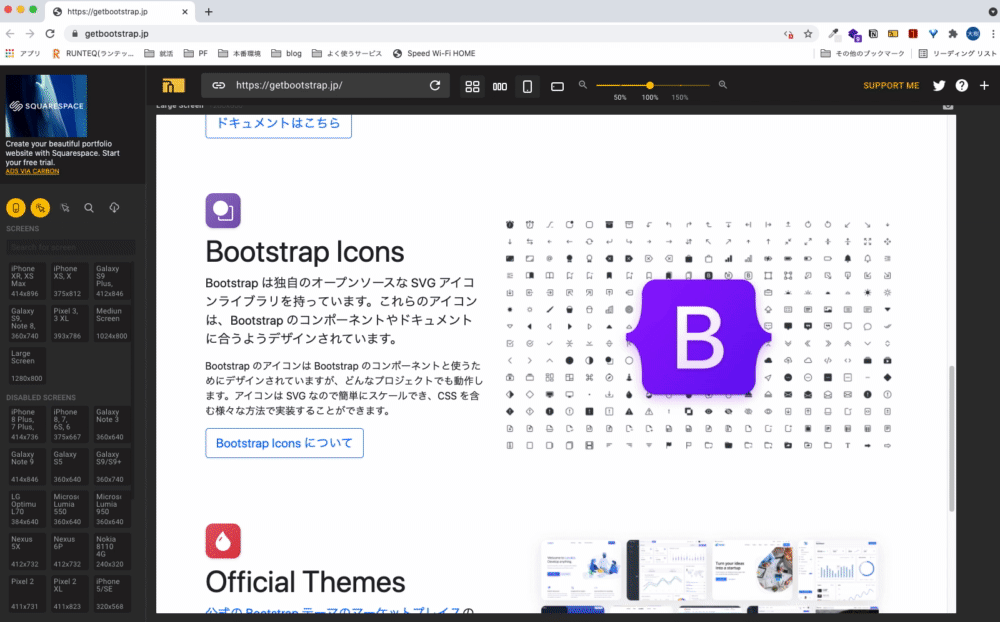
いちいちディベロッパーツールを開いて画面ごとに変えて作業するのってかなり手間だったはずです。
ですが、この拡張機能で複数の画面サイズを一括で確認することができるので、作業が格段に早くなると思います。
Notion Web Clipper
言わずと知れたNotionアプリの拡張機能です。これを使うことで、ブラウザで開いているページをNotionに移すことができます。
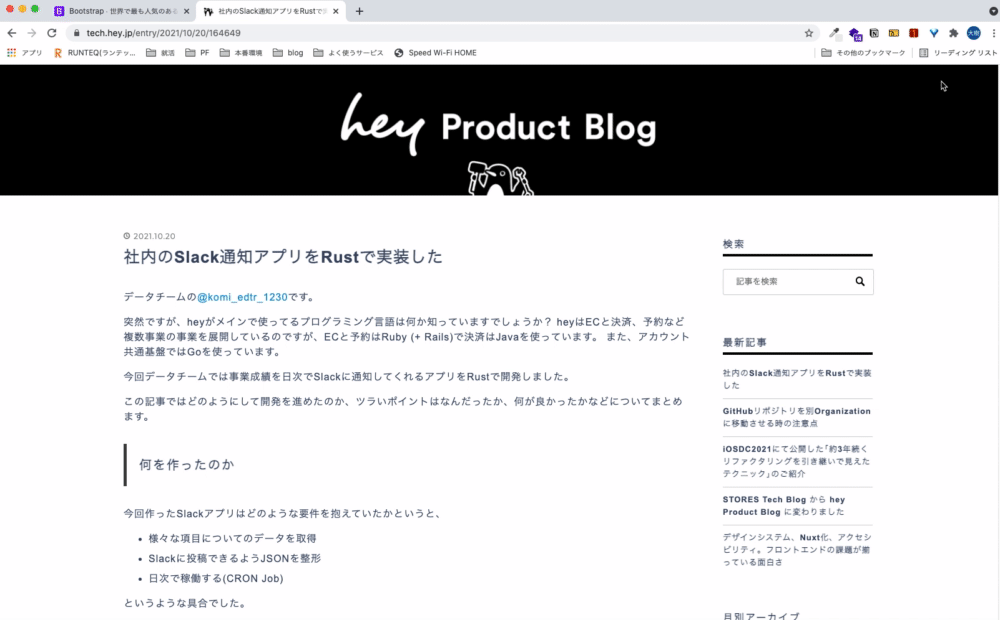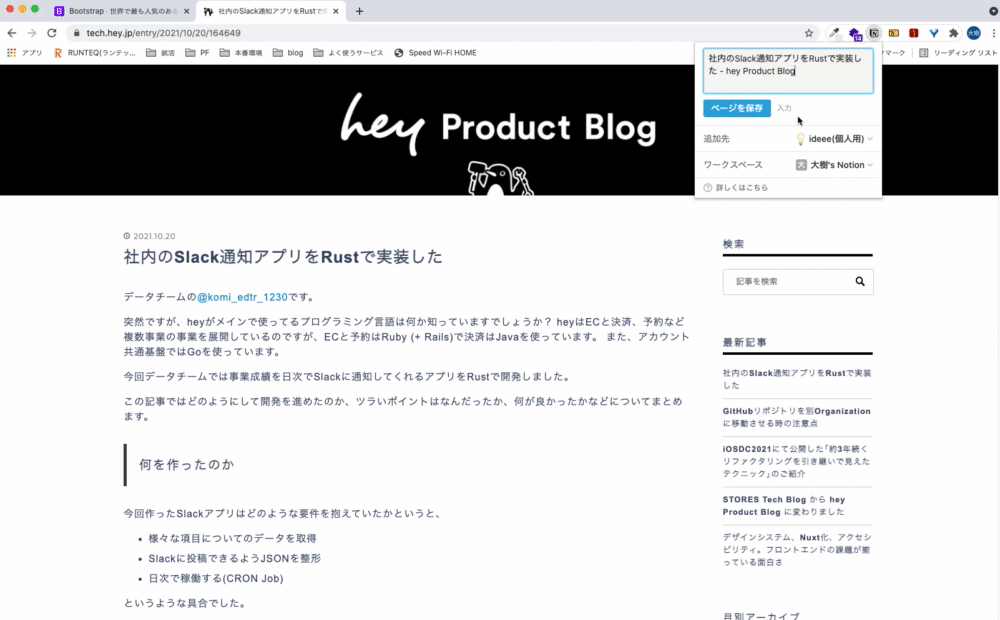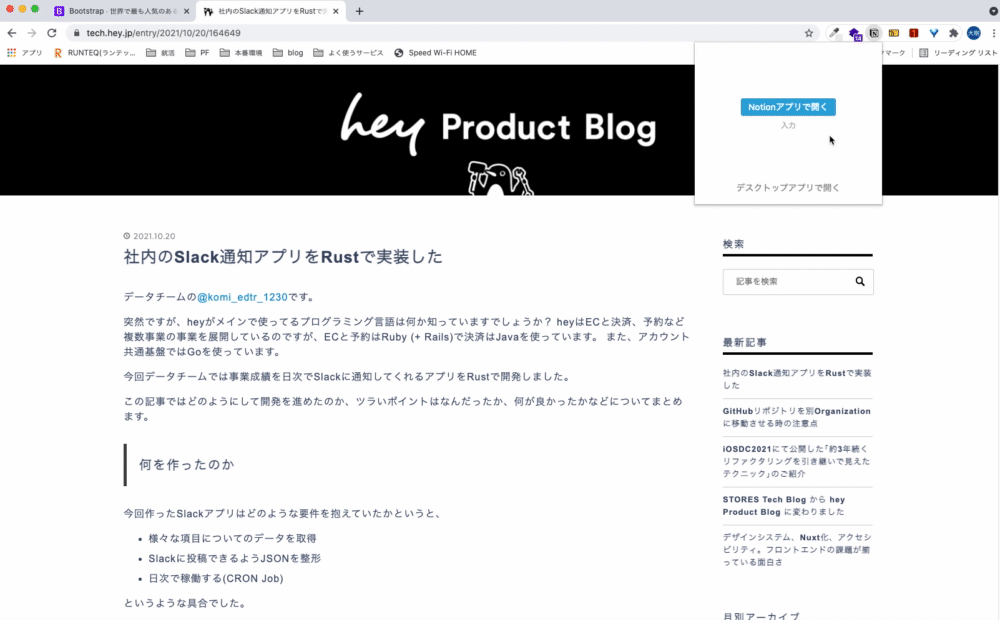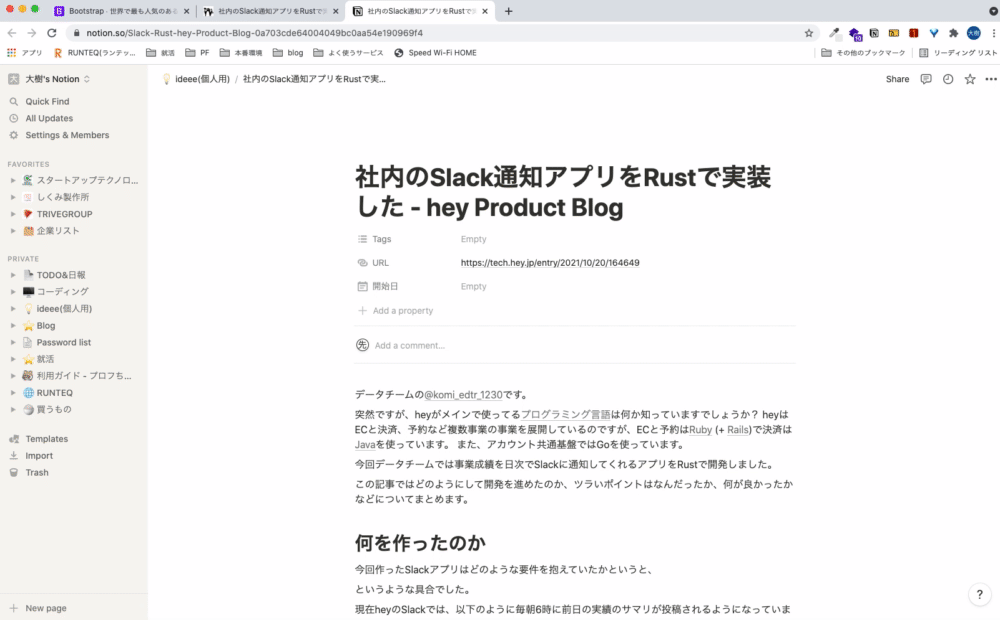
Notionはマークダウン記法に対応しているので、はてなブログやQiitaなどのマークダウンで表示されているページに対して使うと効果的です。
しかし、こちらの拡張ツールはまだ出たばかりでいくつか改善点があります。例えば、保存先をNotionのワークスペース単位でしか選べないため、ワークスペースの中のどのページに保存するかを選択することが現状できません。今後の改善に期待します。
ato-ichien
実装方法についてググるとたくさんの情報が出てくると思いますが、古い記事が乱立していて最新記事が探しづらいことがあると思います。例えば、「jquery rails tag」で検索すると、2015年の記事が出てきたりします。
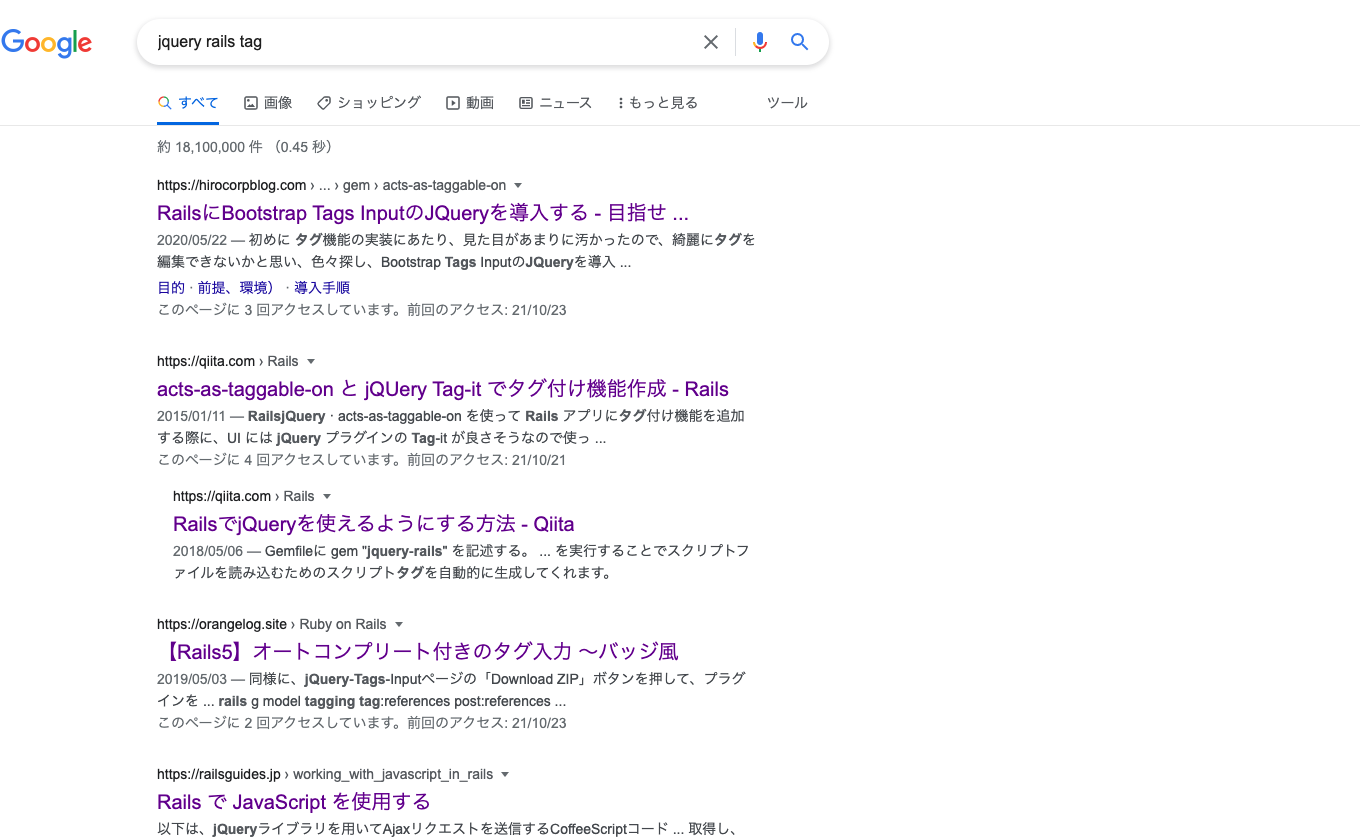
二次リソースなどを検索する場合なるべく新しい記事の方がいいので、古い記事はかなり邪魔に感じます。
ato-ichienは検索結果を1年以内に作成されたものに限定することができます。
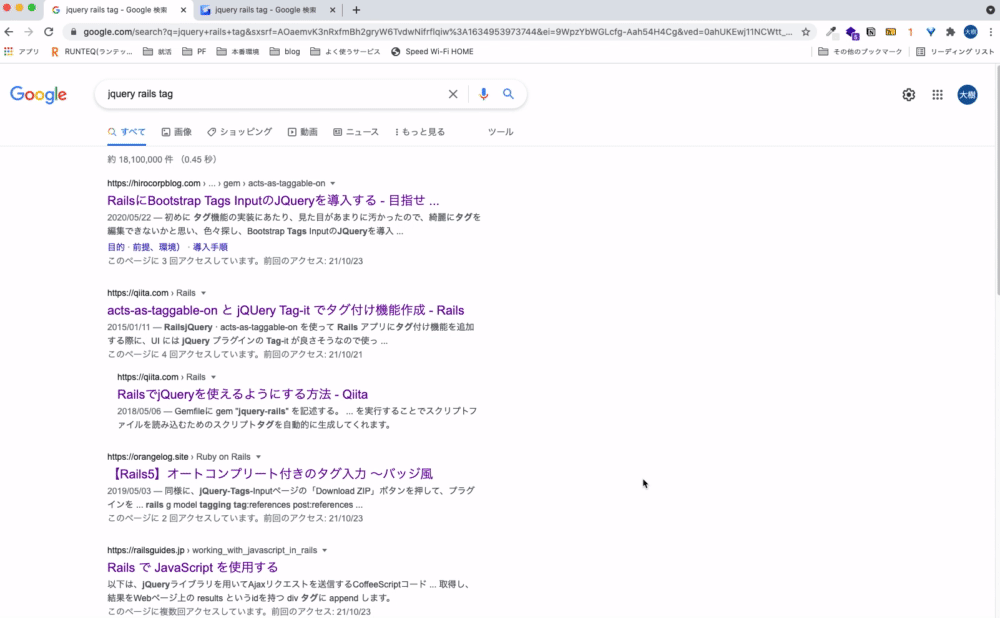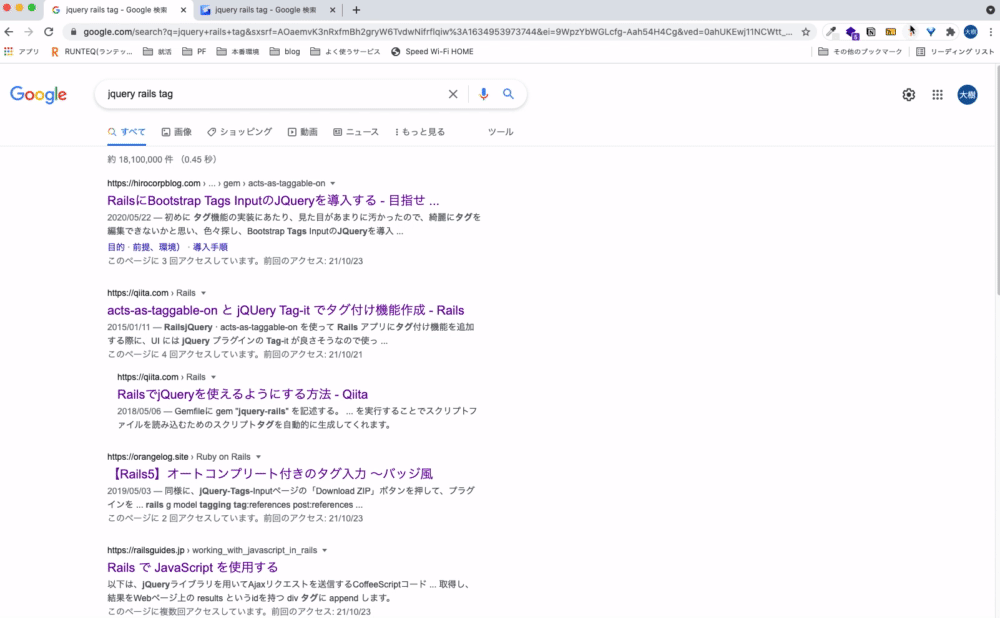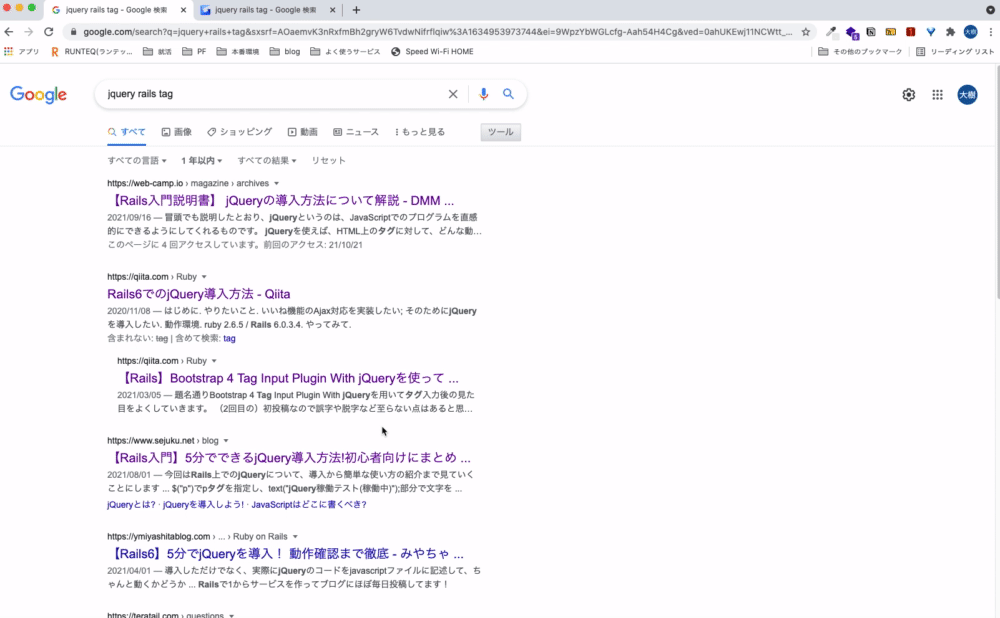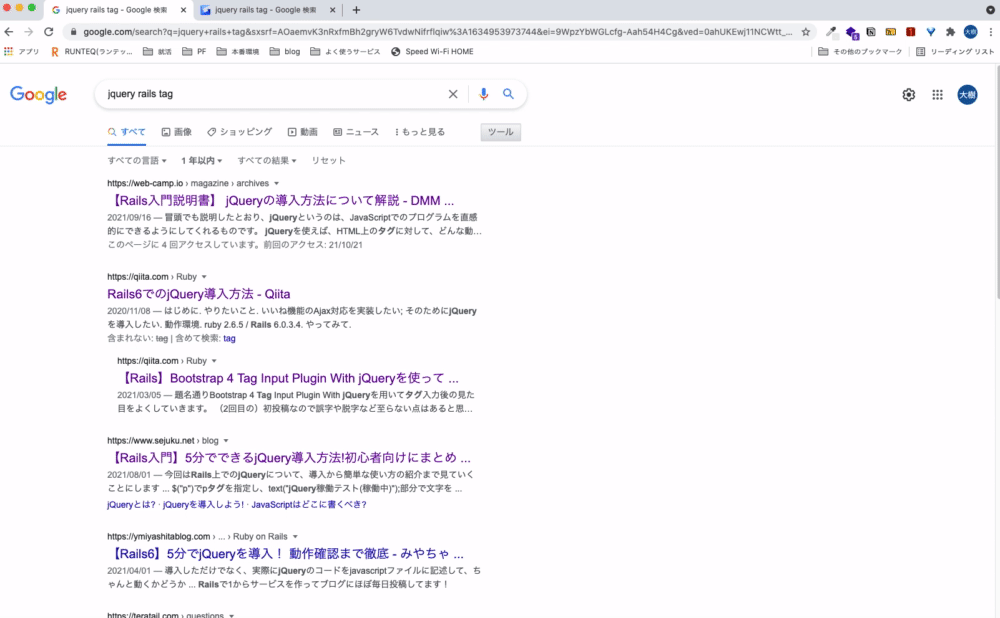
最新の情報にのみアクセスしたい場合に便利です。
Colorzilla
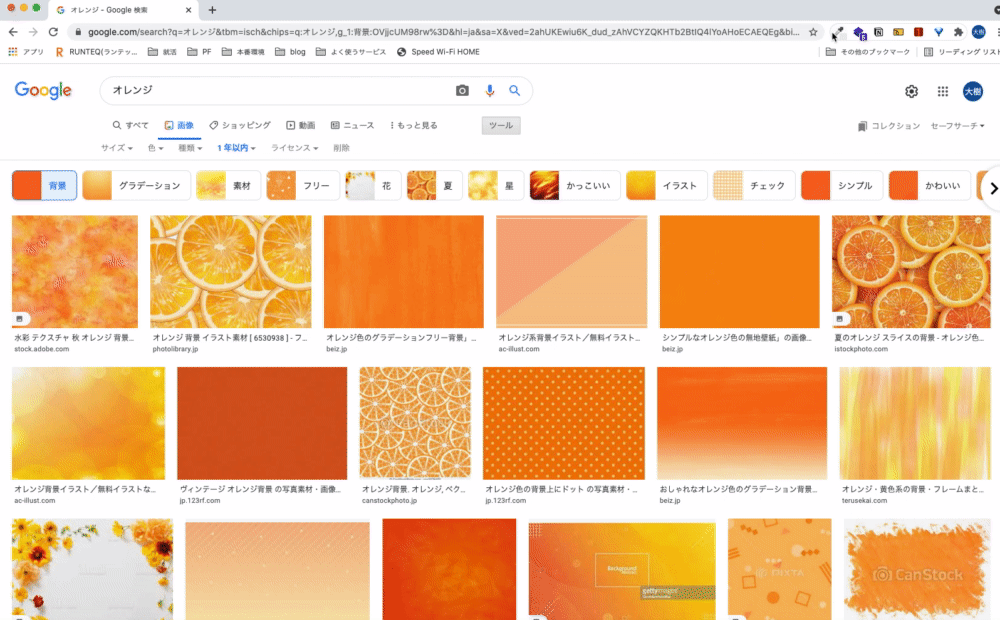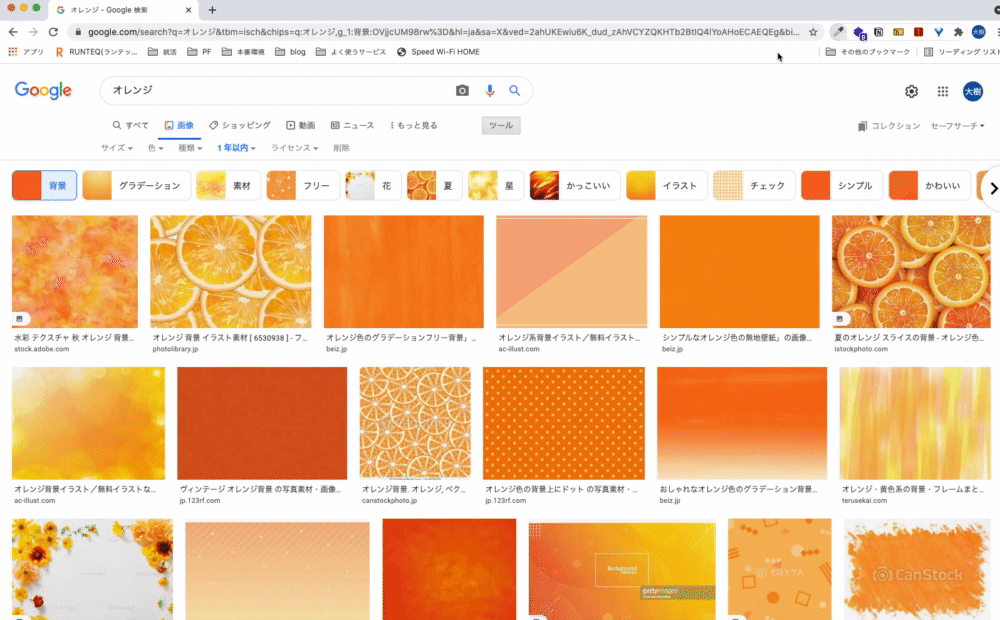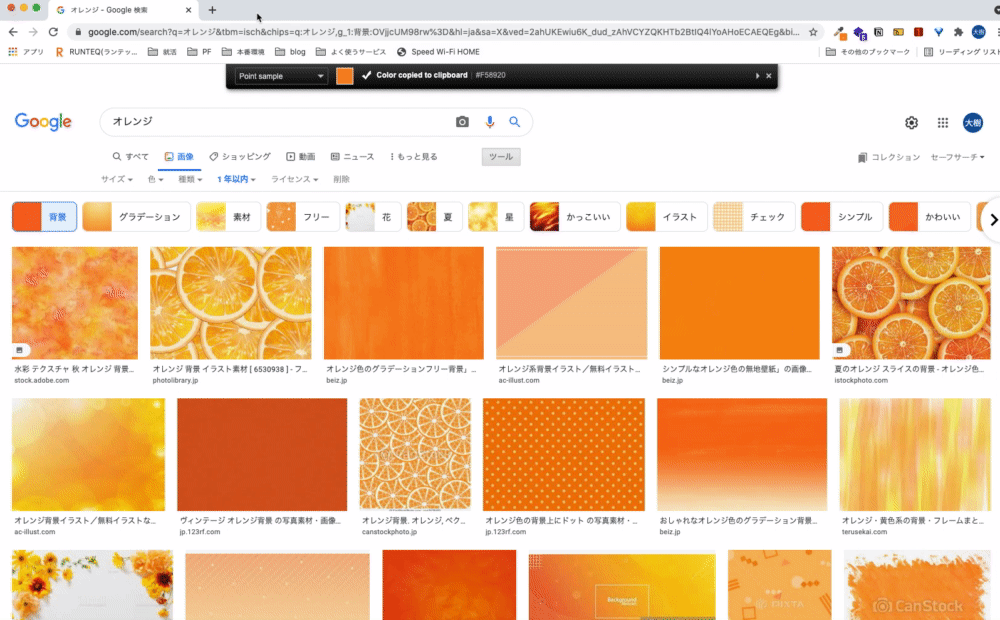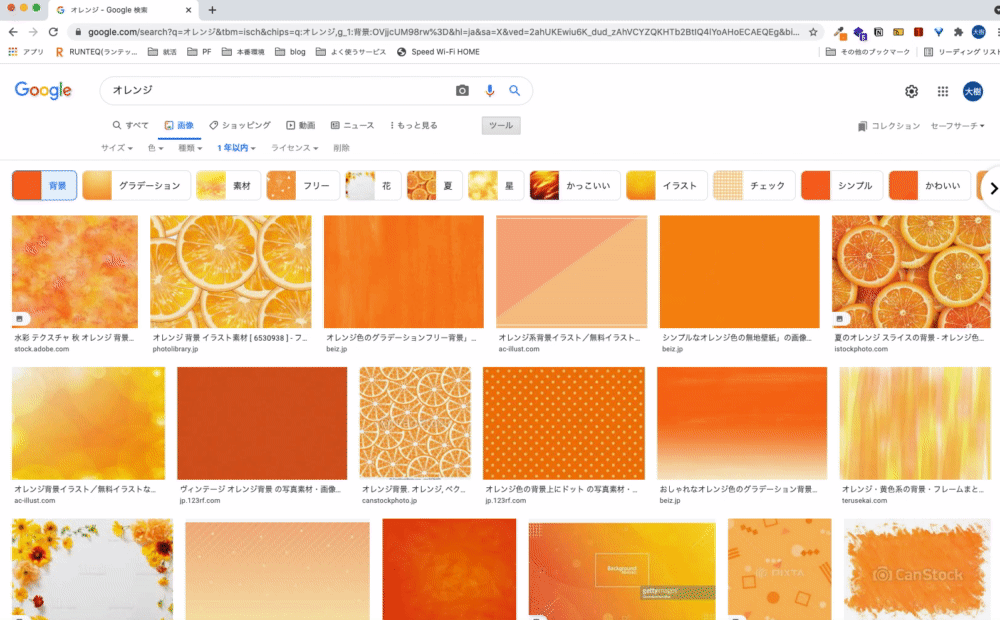
画面上にある色のカラーコードをコピーすることができます。
こちらは昔から愛用しているので少し古く見えてしまいます。今だとこの拡張機能以外にもcssの色に関するツールはいくつも出ているみたいなので、各々で比較検討してみてください。
Clipy
こちらは番外編でChromeの拡張機能ではありません。下記サイトよりMacに実際にダウンロードしてください。
昨日はシンプルでコピーアンドペーストする際に過去にコピーしたものをストックすることができるツールです。
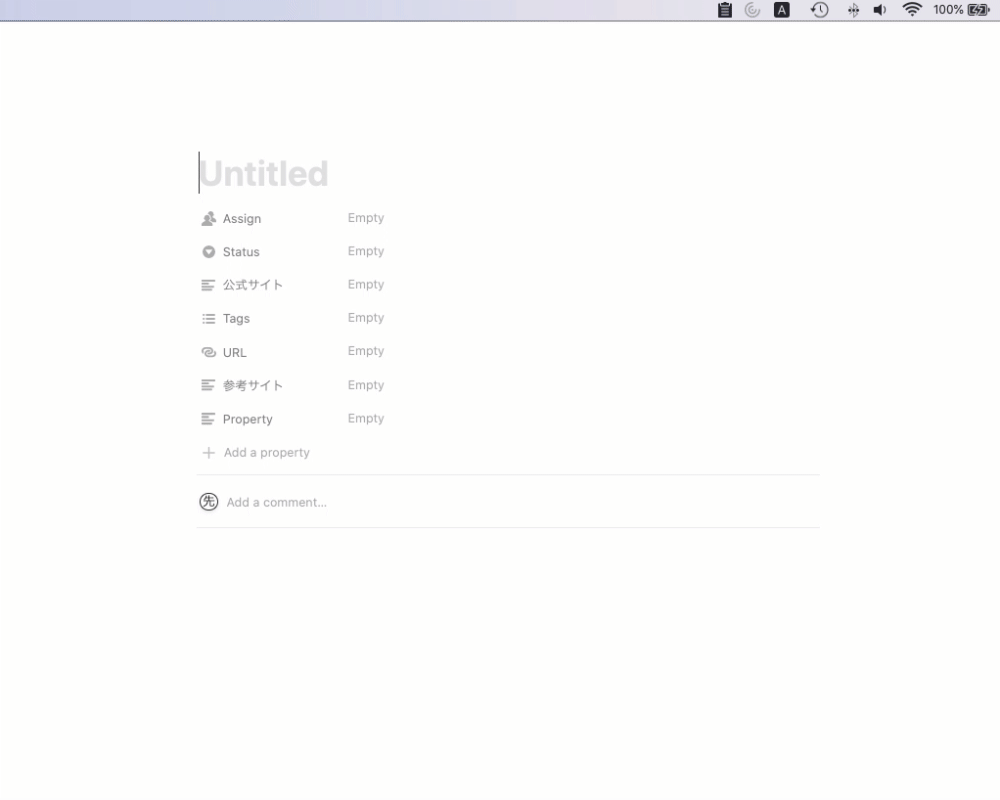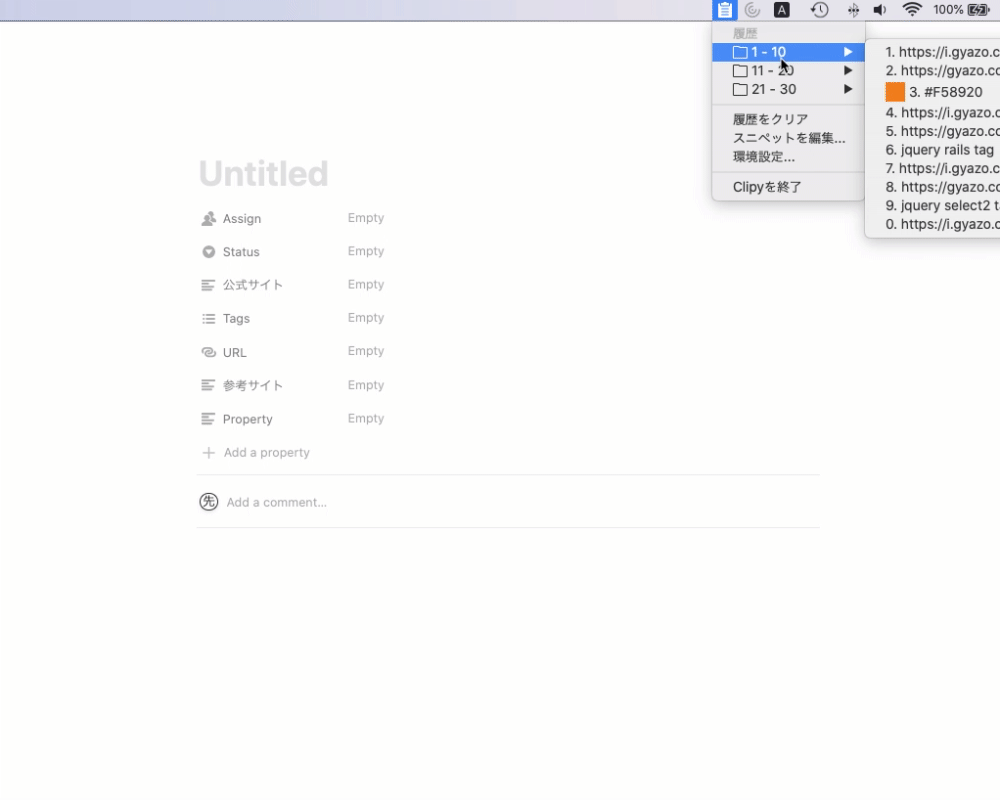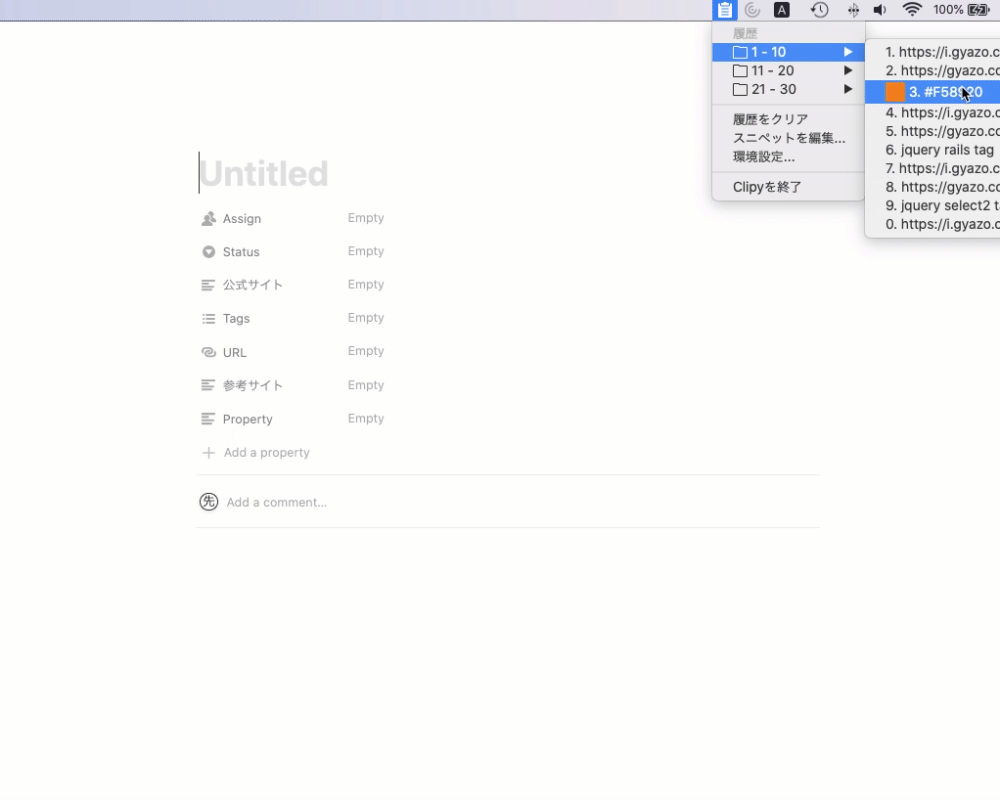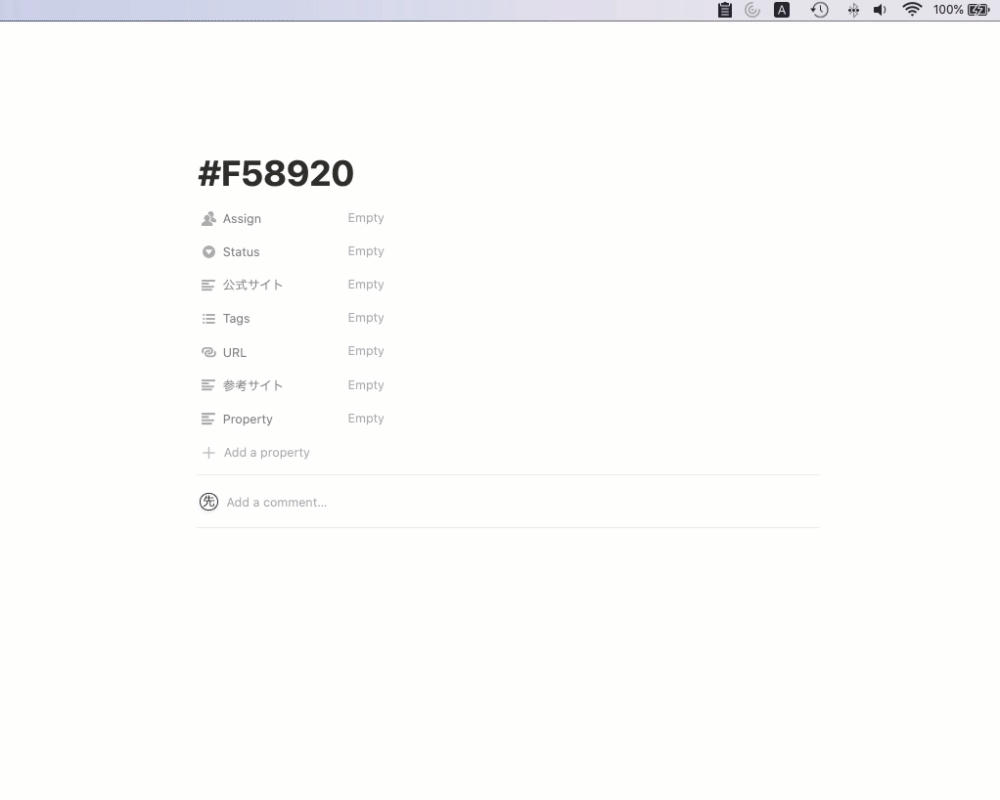
何度も同じものをペーストすることや間違ってコピーをしてもともとコピーしていたものが上書きされてしまうことはよくあると思います。そんな時に上記のツールをインストールしておけば安心です。
終わりに
次回はタグ機能についてシェアしたいと思います。