【無職に転生 ~ 就職するまで毎日ブログ出す③】【Rails】sorceryを使ったSlackログイン①
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!大人気アニメのタイトルをまるパクリした毎日投稿チャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
本日はログインgemであるsorceryを使用してSlackログインを実装する記事を書いていきたいと思います!しかし、かなりやることが多いので二回の記事に分けて行いたいと思います!
SlackログインはSorceryでできるようになった!
実は自分がslackログインを実装したのはdeviseとomniauthのgemを組み合わせで行いました。理由としてはsorceryではエラーが起きていたからです。自分は1、2週間かけてsorceryでslackログインができない理由を調査したことがあります。しかし、どうやってもできなかったので明らかにgem側の問題と結論づけました。というのもslack.rbというsorceryのslack認証ファイルの更新が5年前で止まっていたからです。
しかし、最近なぜか更新されていることを発見し、Pull Requestが投げられていることを確認しました!
これでsorceryでもslackログインができるようになったらしいので自分も本当にできるようになったか確認したところ、しっかりとできるようになっていました!!!!そのため、この記事でその方法を詳しく紹介します!
セットアップ
Slackログインを実装する前に、ユーザーモデルの作成など必要な設定をしておきます。基本的には公式と同様の流れで設定を行います。
GitHub - Sorcery/sorcery: Magical Authentication
gem 'sorcery'
$ bundle install
下記コマンドを実行してマイグレーションファイルやsorceryの設定ファイルを作成
$ rails generate sorcery:install Running via Spring preloader in process 74291 create config/initializers/sorcery.rb generate model User --skip-migration rails generate model User --skip-migration Running via Spring preloader in process 74315 invoke active_record create app/models/user.rb invoke test_unit create test/models/user_test.rb create test/fixtures/users.yml insert app/models/user.rb File unchanged! The supplied flag value not found! app/models/user.rb create db/migrate/20211003000947_sorcery_core.rb
作成されたマイグレーションファイルは以下のようになります。
class SorceryCore < ActiveRecord::Migration[6.1] def change create_table :users do |t| t.string :email, null: false t.string :crypted_password t.string :salt t.timestamps null: false end add_index :users, :email, unique: true end end
変更は特に必要ないのでそのままrails db:migrateします。
$ rails db:migrate
マイグレーションファイルの設定に合わせてモデルのファイルにもバリデーションを設定しておきます。
class User < ApplicationRecord authenticates_with_sorcery! validates :email, uniqueness: true, presence: true validates :password, presence: true end
ここまでで必要な設定は完了です!
Slack Developersでの設定
まず下記ページにアクセスします。
Slack API: Applications | Slack
下記のような画面になっているので、上部にある「Create New App」をクリックします。
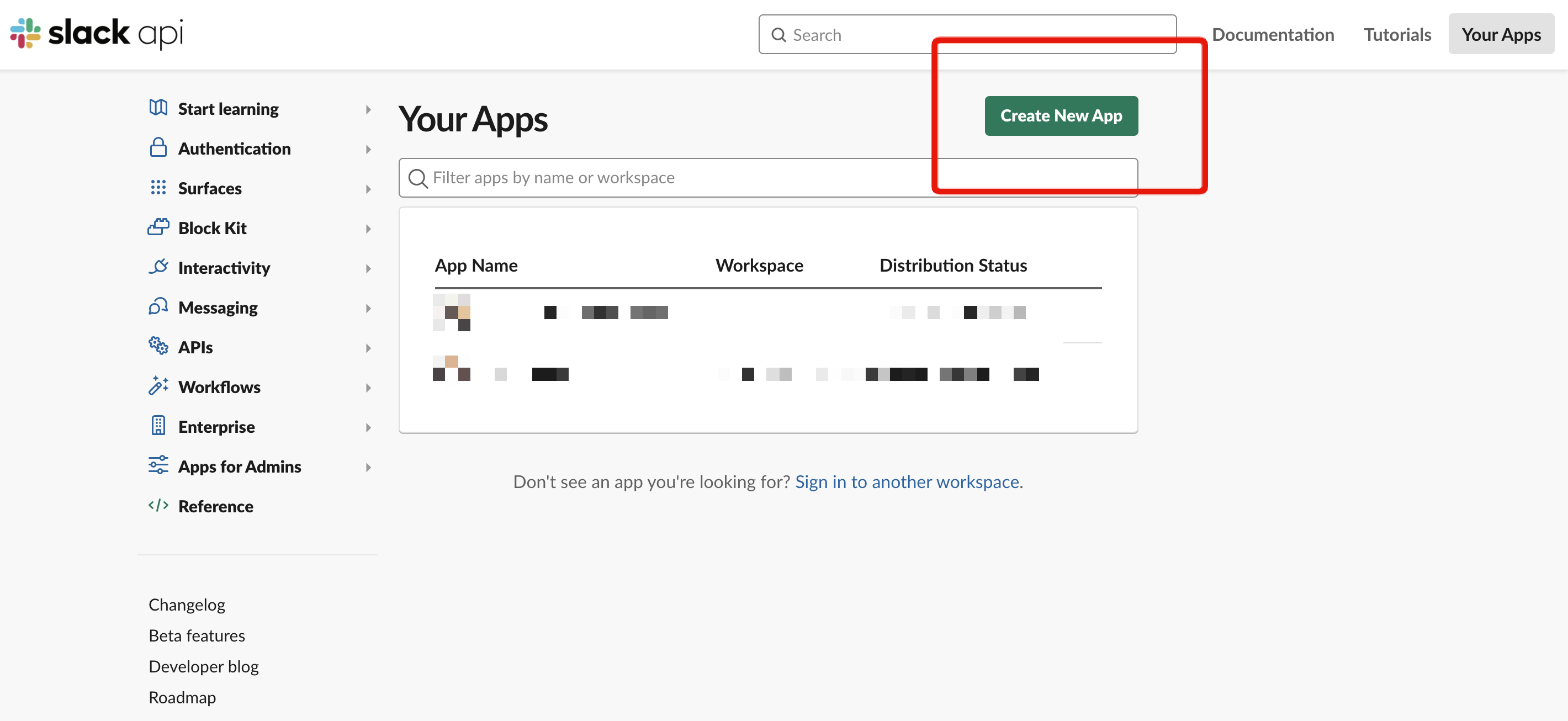
すると以下のようなモーダルが開きました。
Choose how you’d like to configure your app’s scopes and settings.
「アプリのスコープや設定をどのように設定するかを選択してください。」と説明されています。ここではSlack標準の設定である「From scratch」を選択します。
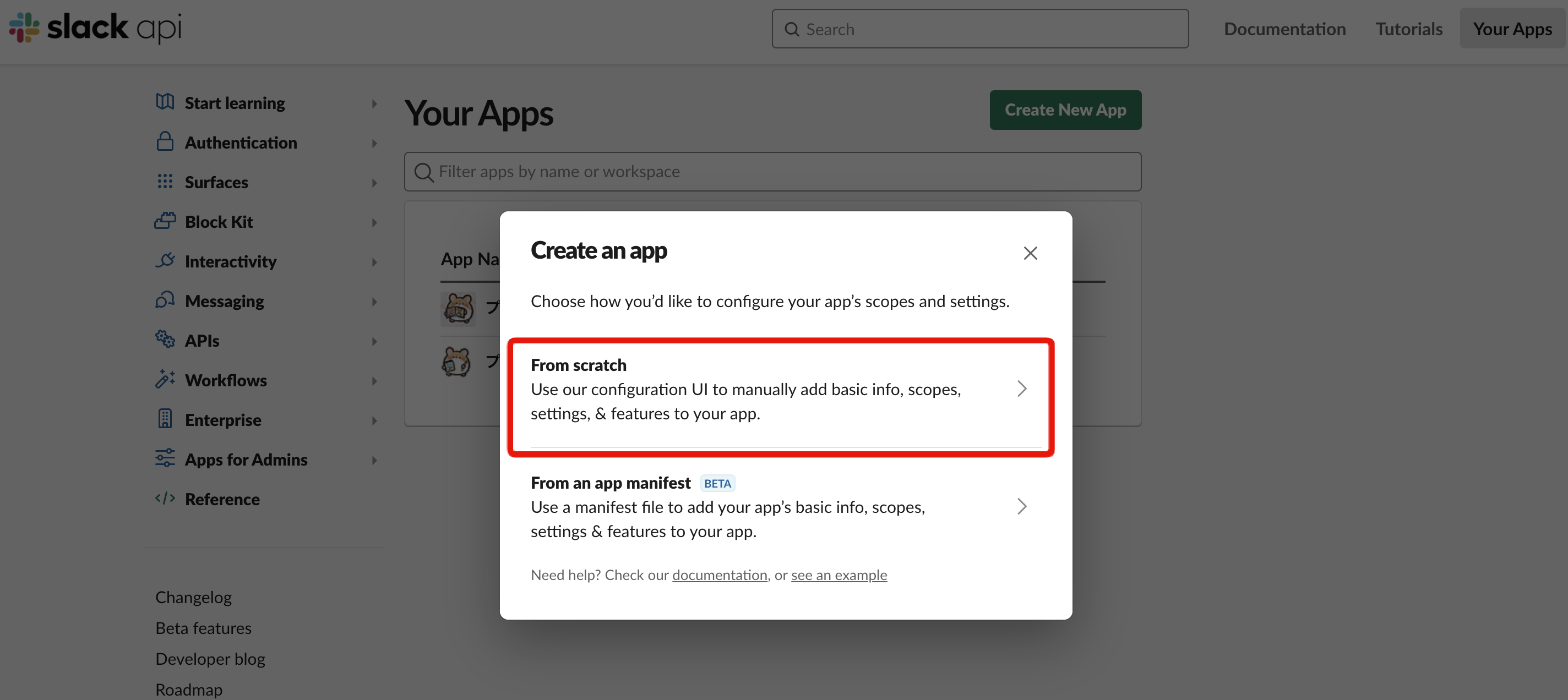
次に別のモーダル が開きアプリの名前と開発ワークスペースを選択します。
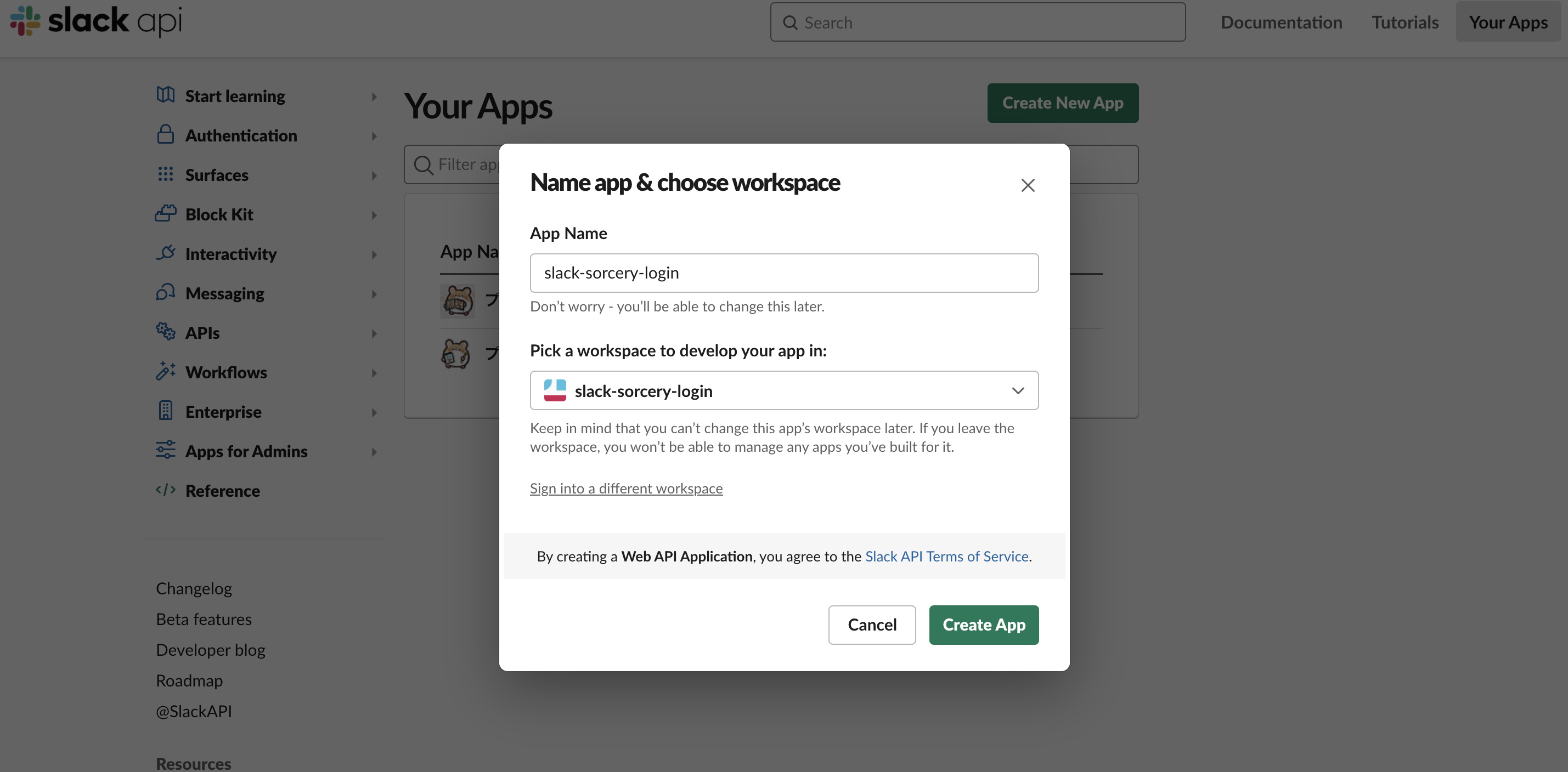
アプリの名前は分かりやすいものにしておきます。
- App Name → 「slack-sorcery-login」
開発ワークスペースとはSlackアプリを開発する際に使用するワークスペースです。既に参加しているワークスペースでも構いませんが、アプリように新しく開発ワークスペースを作成したほうがいいと思います。ワークスペースの作成方法については以下のリンクから作成してください。
自分は新しく「slack-sorcery-login」をいうワークスペースを作成して、それを開発ワークスペースとして選択しました。
- Pick a workspace to develop your app in: → 「slack-sorcery-login」
最後に「Create App」を押してアプリを作成します。成功すると下記のようなSlack Appの開発画面に遷移します。これでアプリの作成は完了です。
最後にClient IDとClient Secretを確認します。上記の画面を下にスクロールすると確認できます。後ほどこちらは使用します。
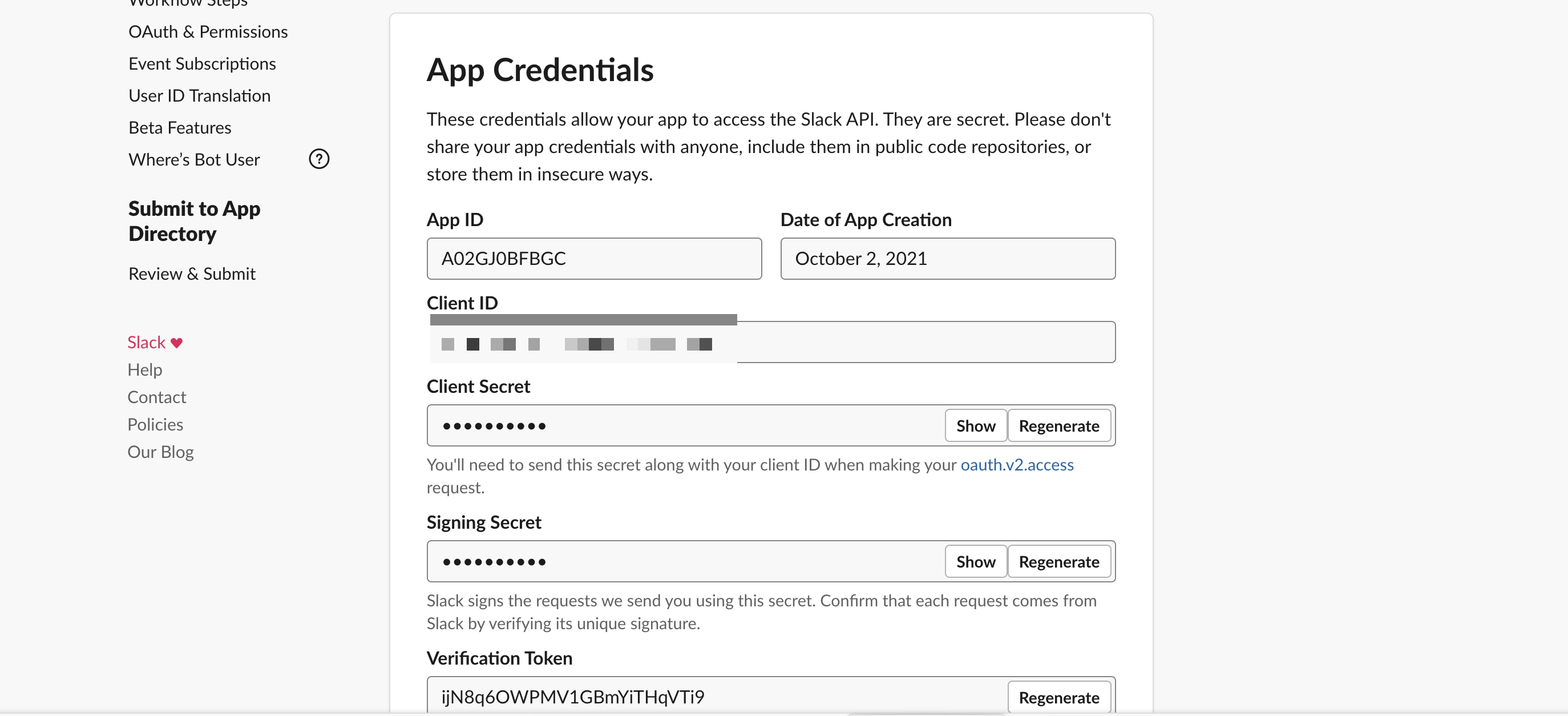
Slackログイン用のファイル設定
アプリを作成できればいよいよSorceryのSlack認証機能を実装します。基本的にはSorceryの公式の外部認証のwikiに沿って実装します。
Authenticationテーブル & モデルの作成
External · Sorcery/sorcery Wiki
最初に外部認証用のテーブルを作成します。下記コマンドでマイグレーションファイルを作成します。
$ rails g sorcery:install external --only-submodules gsub config/initializers/sorcery.rb File unchanged! The supplied flag value not found! app/models/user.rb create db/migrate/20211003005016_sorcery_external.rb
作成されたマイグレーションファイルは下記になります。
class SorceryExternal < ActiveRecord::Migration[6.1] def change create_table :authentications do |t| t.integer :user_id, null: false t.string :provider, :uid, null: false t.timestamps null: false end add_index :authentications, [:provider, :uid] end end
providerとは外部認証を提供しているアプリを指します。Twitter、Facebook、LINEなどが挙げられます。そしてマイナーではありますがSlackもその中の一つです。
変更は特に必要ないのでそのままrails db:migrateします。
$ rails db:migrate
次に作成したauthenticationsテーブルに合わせてモデルも作成します。理由はわからないのですが、rails g sorcery:install external --only-submodulesではモデルのファイルは作成されません。よってモデルは別で作成する必要があります。
それではモデルを作成します。マイグレーションファイルはもう既に作成しているので、--migration=falseオプションを付けています。
$ rails g model Authentication --migration=false
Authenticationモデルにbelongs_to :userを追加
# app/models/authentication.rb class Authentication < ActiveRecord::Base belongs_to :user end
Userモデルにはhas_many :authentications, dependent: :destroyとaccepts_nested_attributes_for :authenticationsを追加
# app/models/user.rb class User < ApplicationRecord authenticates_with_sorcery! validates :email, uniqueness: true, presence: true validates :password, presence: true has_many :authentications, dependent: :destroy accepts_nested_attributes_for :authentications end
Sorcery.rbの設定
次にsorcery.rbでSlackの認証の設定を記述します。sorcery.rbで「Slack」と検索すると下記の部分が確認できます。
# config.slack.callback_url = "http://0.0.0.0:3000/oauth/callback?provider=slack" # config.slack.key = '' # config.slack.secret = '' # config.slack.user_info_mapping = {email: 'email'}
コメントアウトを外しconfig.slack.keyにはClient ID、config.slack.secretにはClient Secretを記述します。しかし、直書きするのはよくないので環境変数はcredentialsに定義します。
config.slack.callback_url = "http://0.0.0.0:3000/oauth/callback?provider=slack" config.slack.key = Rails.application.credentials.dig(:slack, :clinet_id) config.slack.secret = Rails.application.credentials.dig(:slack, :client_secret) config.slack.user_info_mapping = {email: 'email'}
credentialsの編集方法は下記Qiitaを参照ください。
Rails5.2から追加された credentials.yml.enc のキホン - Qiita
$ EDITOR="vi" bin/rails credentials:edit
下記のように記述します。
slack: client_id: 2572424345441.2562011521556 client_secret: 6627c1e772a94532566a2c8588927608client_secret
また、どの外部認証を使うかを明記する必要があるため、sorcery.rbの83行目のコメントアウトされている部分のコメントアウトを外し、slackを追加します。
config.external_providers = [:slack]
また、「user.authentications_class」とsorcery.rbで検索し、外部認証のクラスを明記するために下記のようにAuthenticationクラスを指定します。
# --- user config --- config.user_config do |user| ... # -- external -- user.authentications_class = Authentication ... end
適当なログインページを作成
現状どこにもviewを書いていないのでログインページを適当に作ります。
ログインページを適当に追加
現状どこにもviewを書いていないので、ログインするためのページを適当に作ります。
$ rails g controller home index
次にコントローラーを編集します。sorceryのヘルパーメソッド、require_loginを追加します。
# app/controllers/home_controller.rb class HomeController < ApplicationController skip_before_action :require_login def index ;end end
# app/controllers/application_controller.rb class ApplicationController < ActionController::Base before_action :require_login end
routes.rbにHomeControllerのindexアクションをルートパスに指定します。
Rails.application.routes.draw do root to: "home#index" end
viewも作っておきましょう。中身は記述しなくても良いのでファイルだけ作成しておきます。
<!-- app/views/home/index.html.erb -->
本記事での実装はここまでとします!次回でslackログインを最後まで実装します!
参考記事
【無職に転生 ~ 就職するまでブログ出す②】【書籍】エッセンシャル思考
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまでブログ出す】というチャレンジをしています!!!!大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日はロングセラー書籍である「エッセンシャル思考」について書いていこうと思います!
結論
先に本の結論から話します。
「皆さんの人生は無駄だらけです。無駄をなくしていきましょう。」
いきなり暴言失礼しました。ですが、本書を一言で表すとこんな感じになるなと思っています笑
タイトルの「エッセンシャル思考」が何であるかと言うと、「99%を捨て残りの1%に注力する」です。私たちは人生の中で非常に様々なことに取り組みます。その取り組みは人それぞれでありその種類や取り組んでいる量も違います。
エッセンシャル思考ではその取り組みのほとんど(99%)は無駄であると言います。なぜなら複数の取り組みは一つの方向に向いておらず様々な方向に向いているからです。エッセンシャル思考では何か一つの重要なことに絞り、それに全力を注ぐことです。それとついをなす言葉として非エッセンシャル思考があり、それが様々な取り組みを行っている状態です。そして、本書はエッセンシャル思考をもって一つにことに注力して生きていくことが成功する上で重要なファクターとなると述べています。

非エッセンシャル思考
私たちは日常的に様々な取り組みを行っています。しかし、それは当然のことで一つのことしか人生をやっている人間なんていません。なぜなら「やることがいっぱいだから」です。
「何当然のことをいっているのでしょう??????」
そう思われる方、わかります。ただ、やることがいっぱいな状態って果たしてそれは仕方ないことなのでしょうか?
例を上げます。例えば、あなたはとても優秀でたくさんの人から頼りにされるとします。皆さんはあなたを頼りがいのある人と思い、あなたは頼られ尊敬されています。あなたはそんな状態にハッピーです。満足しています。だから頼まれたらタスクをたくさんこなして褒められてさらにハッピーです。しかし、その成果は中途半端です。
この状態が非エッセンシャル思考です。つまり、やることがいっぱいな状態はあなたが他人から引き受けたり他人から取ったりした結果です。様々な方向に矢印が飛んでいる状態はこのようにあなたが能動的か受動的か取ったタスクによって生まれます。
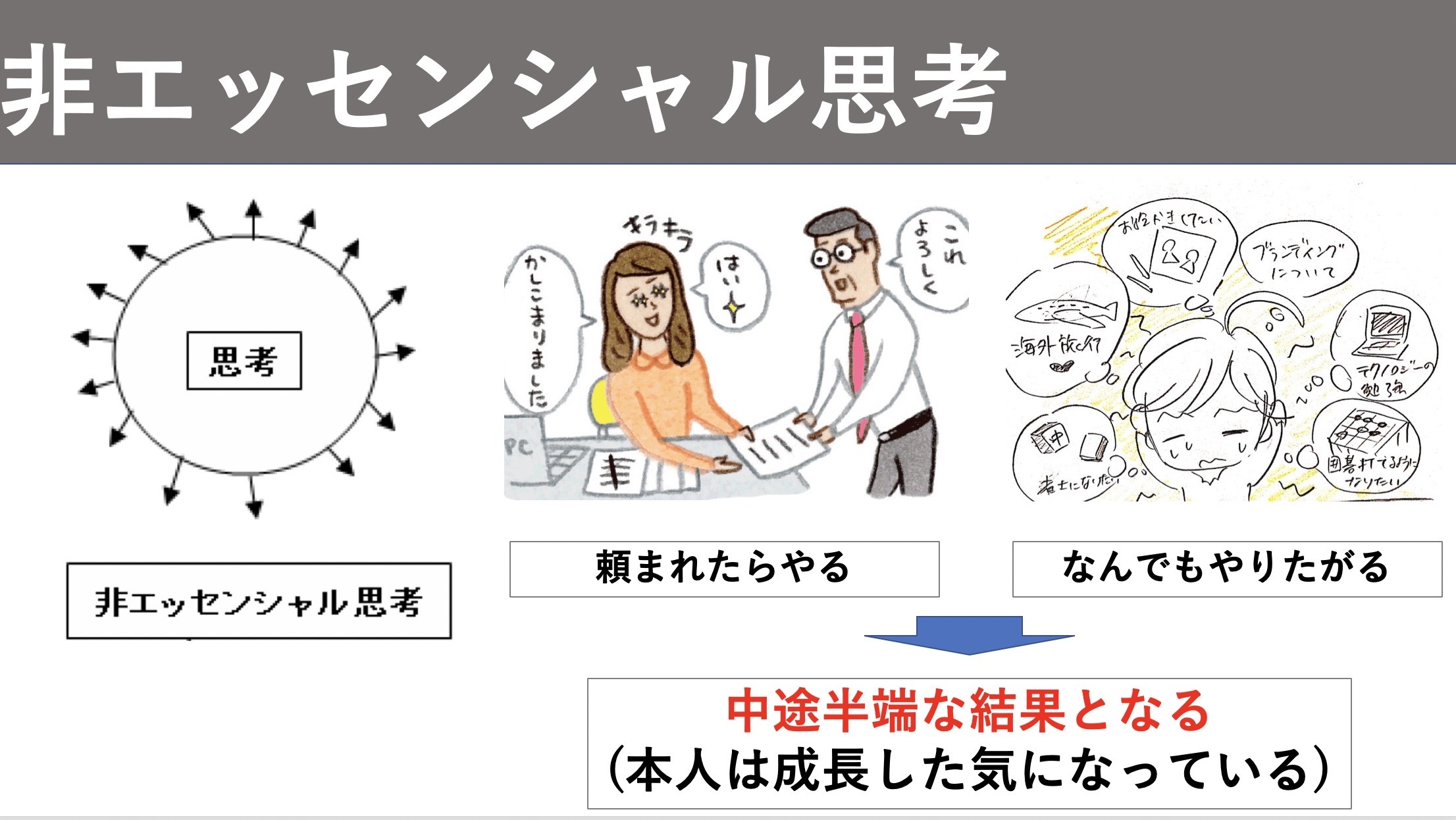
非エッセンシャル思考の原因
上述した通り非エッセンシャル思考はよくある頼まれた結果陥っている状態です。ですのでその原因は明白で「Noと言う力がない」ためです。仕事をむやみやたらに引き受けて、相手に悪いと思い断れず、結果タスクが増えすぎている状態です。それによって、あなたがしたいことに使える時間が減り、逆に他の人がやりたいことをできるという状態になります。

エッセンシャル思考の特徴
非エッセンシャル思考はよくないことはなんとなくわかるけど、エッセンシャル思考ってどんな状態だろう?エッセンシャル思考の人の特徴としては下記の二つが挙げられます。
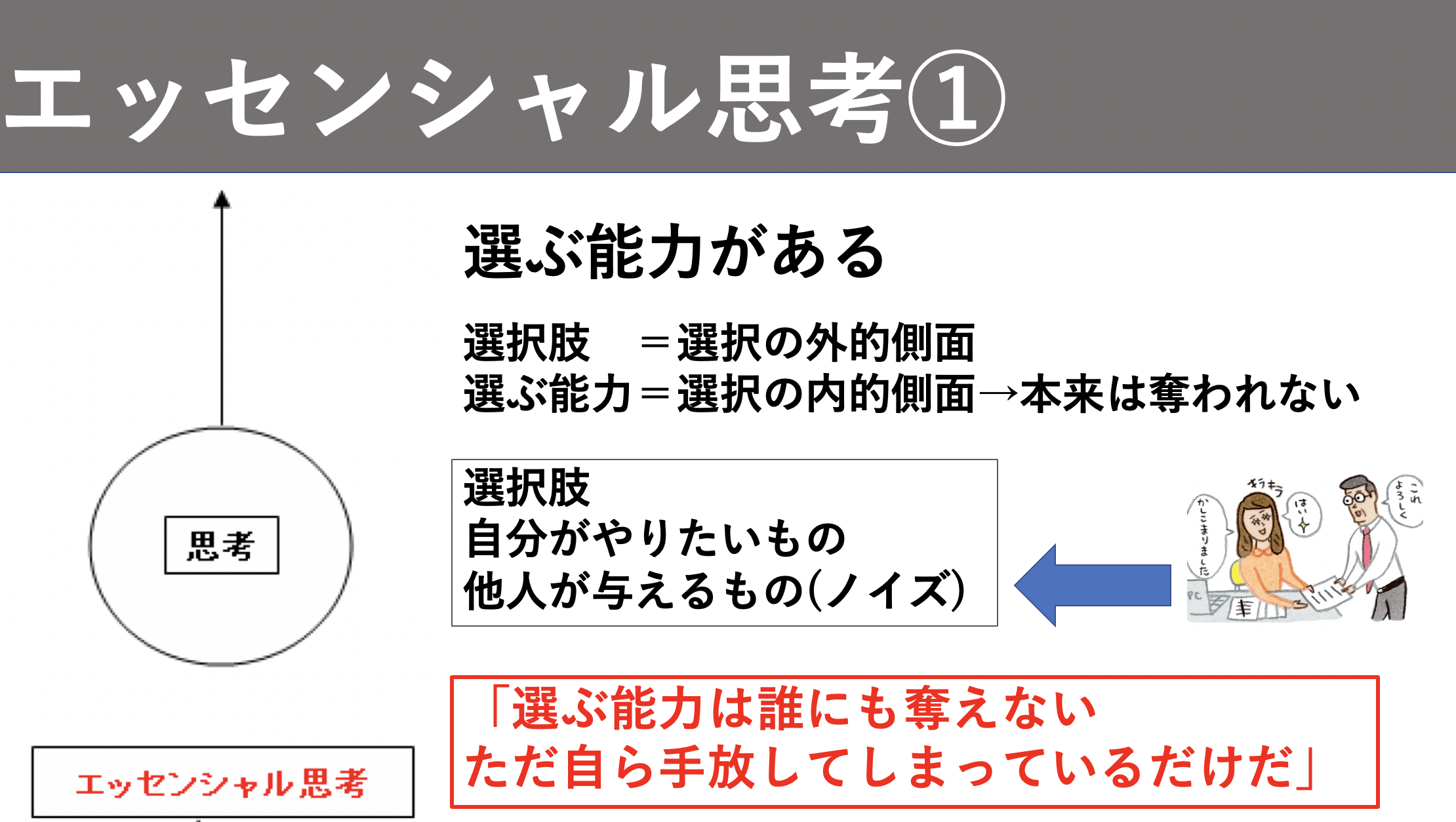
**選ぶ能力がある**
まず選ぶ能力ですが、そのままの意味であなた自身が選びたいと思って主体的に選ぶ能力です。具体的には、様々な選択肢が世の中にはあると思いますが、それを振り切りあなた自身が選びたいものを選ぶ能力です。
「そんなん当たり前じゃん。」みたいなことは言われるかもしれませんが、その選んだものは本当にあなた自身がしたくて選んだものですか?本当は選ばされたものなんじゃないでしょうか?他人から与えられた選択肢(本書ではノイズという)を選んでいませんか?
選ぶことは本来あなた自身の特権であり誰にも奪えないはずなのに、他人との関係性や気遣いで選ばされてしまったことはたくさんあると思います。これが非エッセンシャル思考です。
エッセンシャル思考は選ぶ能力があります。他の人から頼まれても必要なければ断ります。自分がしたいことを選びます。
**トレードオフを知っている**
エッセンシャル思考はなぜ自分で選ぶ能力があるのかと言うと、何かを選ぶことは何かを捨てることを知っているからです。
集中を阻害してくるのは他人が何かを頼んでくる時です。でもそれをやろうとすると今取り組んでいるやりたいことができなくなります。時間は無限ではなく有限で、相手の頼みを承諾した結果大切な時間を他人のために使うことになります。
トレードオフの考えがエッセンシャル思考を持つ人には常にあります。当たり前のようで意外と意識していないことです。

エッセンシャル思考になる方法
ここまでエッセンシャル思考について説明してきましたが、すごいシンプルですよね!誰しもが相手から与えられた選択肢ではなく、自分が選んだことをしていたいですよね。でも、実際にどう生活していればエッセンシャル思考になれるのでしょうか?本書では3種類の技術、10以上もの方法が紹介されているのですが、この記事では2つだけ紹介させていただきます。
**線引きをする(重要なことを見極める技術)**
これはすごく簡単な方法で今からでも取り組めます。要は90点ルールを取り入れて各選択肢に点数をつけて90点以下は全てNOとしてやらないこととします。この方法が魅力的なことは90点と非常にハードルが高いことです。だいたい他人の選択肢って感覚的にそこまで重要じゃないけどやらないといけないなーと思ってしまうもので、そう言ったものは大体60点ぐらいだと思うんですよね。90点以下は絶対やらないと決めること60点の選択肢なんてものは簡単に切り捨てです。

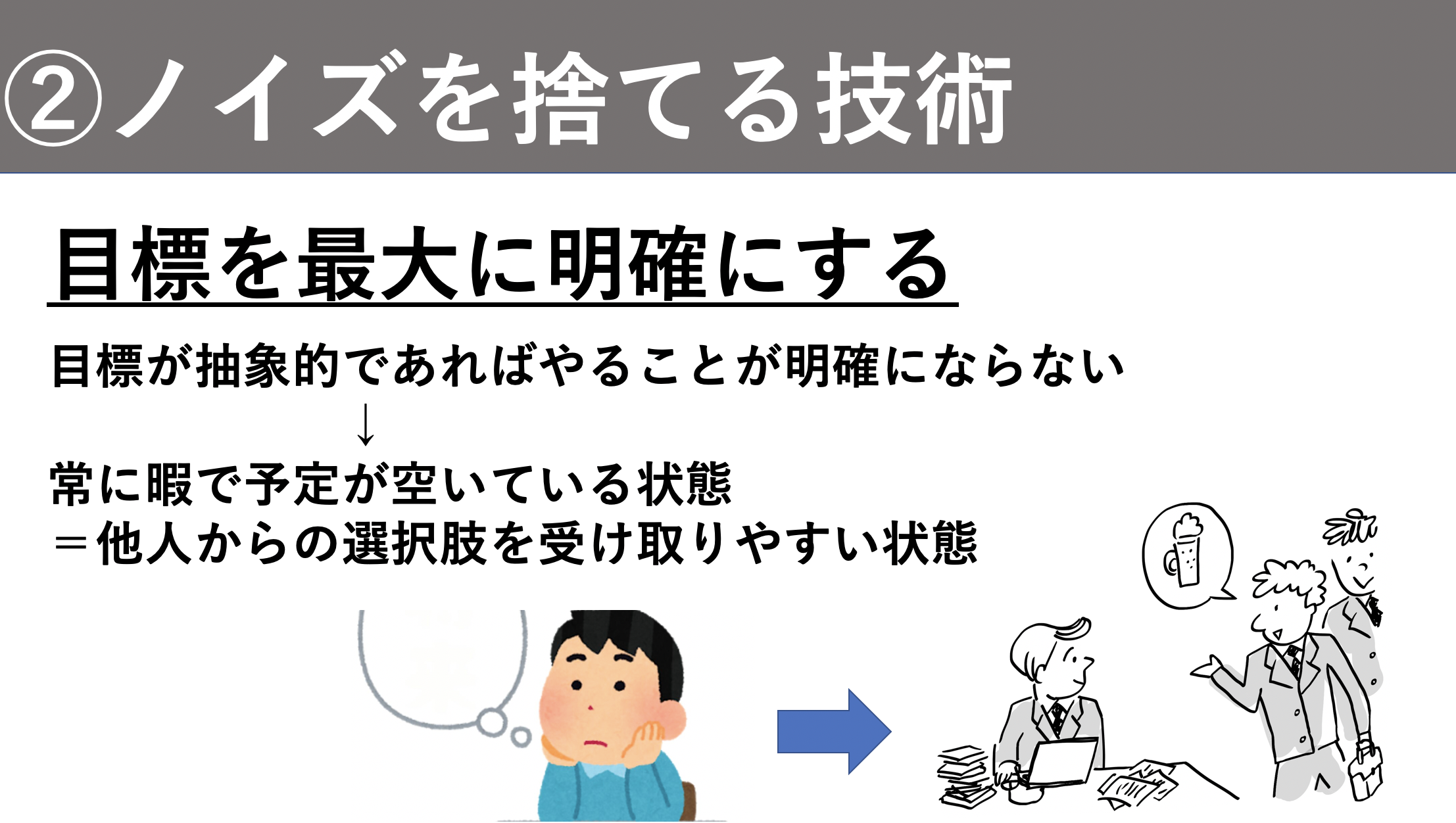
目標を最大に明確にする(重要なことを見極める技術)
普段自分たちが生活しているときに今やるべきことをわかっている人はどれぐらいいるでしょうか。だいたいわかっていない人が多いはずで、自分がやるべきことがわかっていない状態なので、他の選択肢が与えられてもそれをやる余裕があるから引き受けられるんですよね。暇である状態は他人からの選択肢を受け取りやすいのです。
今やることが明確であれば、他人から与えられた選択肢と今やっていることの重要性が比較できるので簡単に取捨選択することができます。なので常に目標を明確にしておくことが重要です。
あとは本書で!
本書はかなり分かりやすい本でした!ですが自分たちの時間が有限であり、限られた時間の中で自分がやりたいことに注力していくことが大事であると改めて思わされました!是非本書を読んでみてください!エッセンシャル思考になる方法がたくさん詰まっています!
【無職に転生 ~ 就職するまで本気出す①】【SQL】句の実行順序
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで本気出す】というチャレンジをします!!!!今月から2クール目が始まる大人気アニメのタイトルのまるパクリチャレンジです。これは単純にRailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。それだけではなくて実は昨日退職して文字通り無職に転生しましてプロニートになり毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!今日から就職が終わるまで頑張ります!ちなみに投稿する内容はまばらです。ただ、自分の知識不足がある領域になるかと思います(未経験なので全部たりませんが)。具体的には下記のとおり。
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
また技術だけでなくビジネス書についても書いていきたいと思っています。理由としてはこれから転職する上でスタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるために技術以外の視点も養っていきたいからです。なのでそれも含めて内定出るまで本気を出して投稿し続けます!
本日はSQLのSELECT文における「〜句」の実行順序について紹介します。
句の実行順序を把握する理由
説明の前ですが「なぜ実行順序を把握しなければならないのでしょうか」という疑問を持った方もいるかと思いますので、なぜやるかを説明します。
それは実行順序を理解することで取得データがどのようなフローを辿って加工され抽出されたのかがわかるからです。
例えば、単純なデータの取得文の場合取得データの順番を意識せずともどうしてそのデータが取得されrかわかると思います。下記はテーブルのデータ全権を取得している処理です。
SELECT * FROM テーブル名
ですが、下記の文章はどうでしょう?
SELECT DATE_FORMAT(post_date, '%Y%m') AS yyyymm ,post_type AS post_or_page ,COUNT(ID) AS cnt FROM posts WHERE (post_type = 'post' OR post_type = 'page') AND post_status = 'publish' AND post_date BETWEEN '20190101' AND '20191231' GROUP BY DATE_FORMAT(post_date, '%Y%m') ,post_type HAVING COUNT(ID) > 1 ORDER BY yyyymm ,post_or_page
どのようなデータが取得されるかが見てすぐにはわからないですよね。ですのでSQL文を読んでいくと思うのですが、どこから見ていけばいいかわかりますか?SELECTから?FROMから?最も効率の良いやり方は実行順序順に辿っていくことではないでしょうか。そうすればデータが取得されるフローを追っていくことができ、どのようなデータが取得されるのかを判断できると思います。なので理解しておいて損はないはず!
ざっくりと句の種類
SELECTで使用する主な句についてはざっくりと以下のとおり。あまり深くは説明しません。
- SELECT
データ取得のための句。どの列を取得するのかを指定します。ほんとによく使います。
SELECT ID, 注文日
- FROM
どのテーブルからデータを取得するのかを指定する句。これがなければ動きません。
SELECT ID, 注文日 FROM 注文
- WHERE
テーブルの中のどのデータを取得するかを指定します。例えば、IDが100231のデータを取得するのであれば以下のように記述。
SELECT ID, 注文日 FROM 注文 WHERE ID = 100231
- JOIN (LEFT JOIN, RIGHT JOIN, FULL JOIN)
2つのテーブルを関連カラムを通して結合する句。これによって複数のテーブルを加工してデータを取得できます。多分初学者が滅茶苦茶つまづく。
SELECT ID, 商品.商品名 FROM 注文 JOIN 商品 ON 商品ID = 商品.商品ID
- ORDER BY
順序をソートできる句。単体だとあまり意味がない。LIMIT句と一緒に使われるケースが多そう。
SELECT ID, 注文日 FROM 注文 ORDER 注文日 DESC
- LIMIT句とOFFSET句
・LIMIT・・・取得したデータを何行取得するかを指定する句。
・OFFSET・・・LIMITをどこから始めるかを指定する句。OFFSETを指定しなければLIMITは一番上の行から取得してしまうが、OFFSETを使うことで上から何行レコードを飛ばすかを指定する。
ちなみにデータベースによってはLIMITとOFFSETは書き方が異なる。
SELECT ID, 注文日 FROM 注文 ORDER 注文日 DESC LIMIT 2 OFFSET 2 // 3行目から2行取得する
- GROUP BY
同じ値を持つデータごとにグループ化する句。例えば、動物のテーブルがあるとして動物の種類ごとにデータを集計したい場合に使われます。
ここで集計という言葉が出ましたが、基本的にGROUP BYは集計関数と言われる、SQLでテーブルの列の合計や平均、行数など指定した列を様々な値にして集計する関数と併用されます。集計関数は5種類あります。
・SUM・・・列の合計を計算する
・AVG・・・列の平均を計算する
・COUNT・・・レコードの数を計算する
・MAX・・・列の最大値を計算する
・MIN・・・列の最小値を計算する
例えば、SUMを使って下記テーブルから値段(price)の合計を取得するとします。
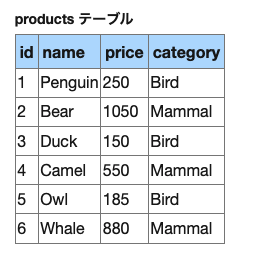
レコードの値の合計を求める (sum集計関数の利用) - SQLの構文
SELECT AVG(price) AS 平均価格 FROM Products
集計関数の特徴としてデータが1レコードになってしまうという特徴があります。これをGROUP BYを使うことで、ある種類ごとの合計金額や平均価格を求めることができます。例えばcategoryごとの平均価格を取得するには以下のクエリを発行します。
SELECT category AS カテゴリー, AVG(price) AS 平均価格 FROM Products GROUP BY category
- HAVING
HAVINGはGROUP BYの処理と併用されます。例えば、上述した処理で各動物ごとの平均価格を求めましたが、平均価格が500円以下のものは出力しないという条件を追加するとします。その時にWHEREを使うかと思いきやそうではなくHAVINGで制約する必要があります。理由としては後述しますが、この記事の主題である実行順の影響です。
SELECT category AS カテゴリー, AVG(price) AS 平均価格 FROM Products GROUP BY category HAVING AVG(price) >= 500
他にもいくつか句はありますがここまでにしておきます。
実行順序
ようやく実行順序について説明できます。結論から先に言うと以下のような順序で実行されます。
FROM/JOIN ↓ WHERE ↓ GROUP BY ↓ HAVING ↓ SELECT ↓ ORDER BY ↓ LIMIT/OFFSET
① FROM/JOIN
最初はFROMとJOINです。SQLを書く順番からFROMが1番最初に実行され、その次にJOINが実行されます。この2つの句によりどこからデータを抽出するかを決めることができます。つまり、データの加工前の合計作業セットを決定します。
FROM
第12回 データベースを作る(テーブル作成) | shell-mag
JOIN
② WHERE
JOINとFROMでデータ一式は揃いましたが、これら2つの句は細かい指定をすることができずテーブル全体を揃えます。テーブルの中のある特定のデータのみを使いたい場合にWHEREでそのデータを抽出します。データ一式から不要なデータを取り除くためにWHEREが実行されます。
【SQL入門】WHEREで検索条件の指定方法をわかりやすく解説 | 侍エンジニアブログ
③ GROUP BY
WHEREで必要なデータを抽出したらそれらのデータをGROUP BYでグループ分けします。これにより、あたかもグループの種類ごとにテーブルを作ることができます。
繰り返しですが、GROUP BYはクエリに集計関数がある場合にのみ使用する必要があるため、集計関数を使用しないのであればここはスキップされます。

グラフ-Azure Databricks - SQL Analytics
④ HAVING
ここまでで取得したいデータはできているのですが、GROUP BYでデータをまとめた結果、不要なデータが出てくるかもしれません。そのため、集計関数実行後にWHEREのように制約をするためにHAVINGをここで実行します。
ここがWHEREが集計関数を使った後の制約に実行できない理由です。実行順序がGROUP BYより先にあるWHEREは、それよりも後に実行されるGROUP BYの処理の結果に対して制約することができません。そのためHAVINGが利用されます。
- WHERE・・・FROM/JOINで揃えたデータから不要なデータを制約
- HAVING・・・集計関数実行後の不要なデータを制約
⑤ SELECT
ここまでで加工されたデータをSELECTで取得します。SELECTはデータを取得するのみですのでHAVINGまでに実行されたデータが取得データです。
⑥ ORDER BY
SELECTで取得したデータを並び替えします。

⑦ LIMIT/OFFSET
最後に並び替えたデータのどの行を取得するのかを指定します。並び替えることでさらに取得したいデータに加工を施すことができます。
終わりに
説明は所々手抜きかもしれませんが、一応一通り説明しました。実行順は調べれば確かに出ますが、SQLを書く時や読む時にいちいち調べていたら時間がもったいないです。また、SQLを読む速さも上がると思うので覚えておいて損はないです!以上!明日も本気出します!
【書籍】世界一やさしい「やりたいこと」の見つけ方
はじめに
みなさんこんにちは、大ちゃんの駆け出し本紹介ブログです笑
本日はいつもの技術的なアウトプットとは違い、本の紹介をしようと思います。現在就職活動中で本を読む機会があるのですが、アウトプット派としては読んだ本をアウトプットせずにはいられないなと!
今回紹介する本は【世界一やさしい「やりたいこと」の見つけ方】です。これは自己分析で悩んでいる人、やりたいことがわからず迷走している人に是非読んでいただきたい一冊です!

著者について
著者は八木仁平さんという自己理解のプログラムを運営されている社長さんです。
なぜこの方が自己理解に関するプログラムを運営されているのかというと、著者の原体験に理由があります。
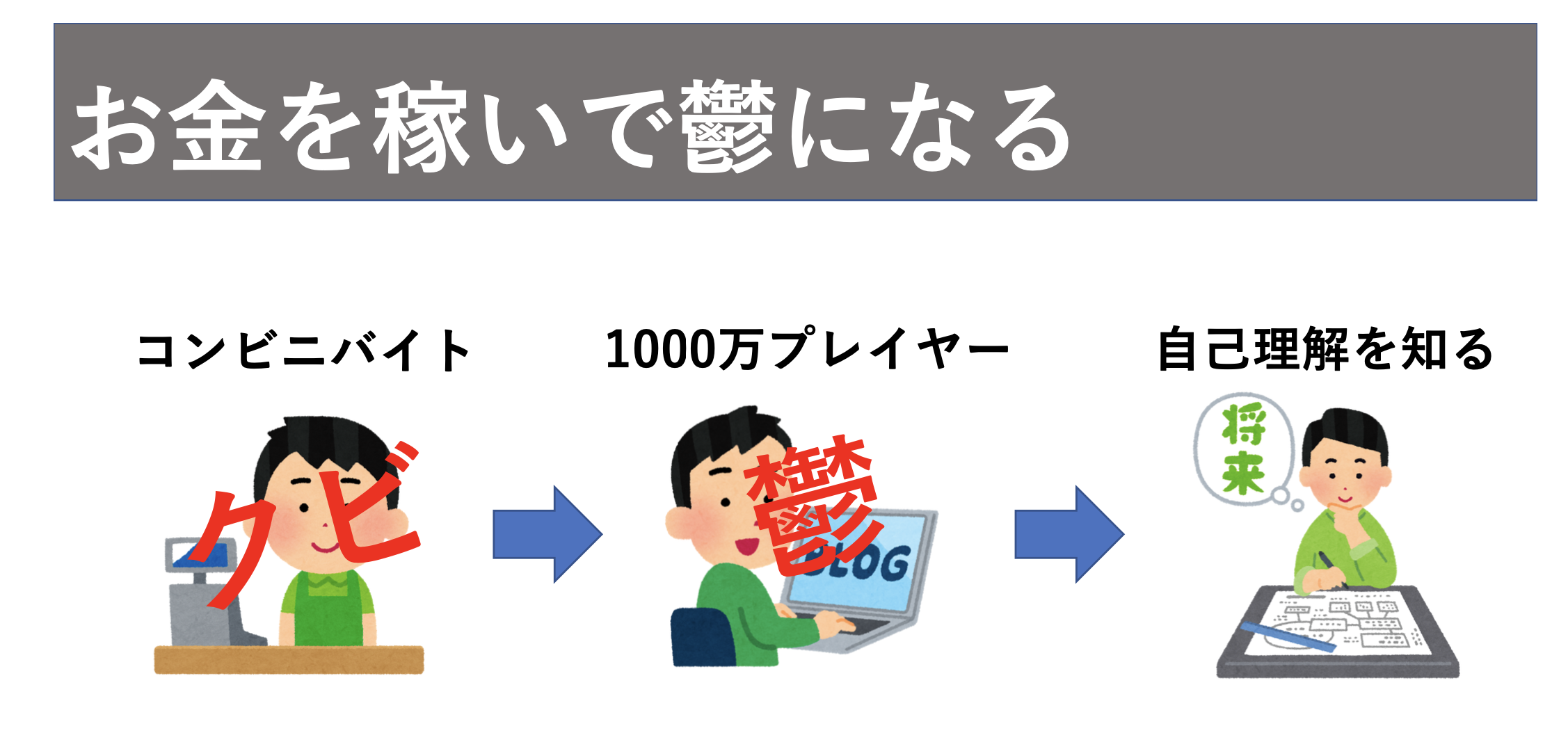
学生時代にコンビニバイトをしていたそうなのですが、かなり短期間でクビになってしまったそうです。というのも、コンビニバイトに対するモチベーションがなく、全くやる気がなかったそうです、、。
次にブロガーとして活動するとブログは大成功、学生なのに年収は1000万と自分からしたら非常に羨ましいと思いました。しかし、次第に「なぜブログを書くのだろうか」とモチベーションの源泉がないままブログを必死に書き続け他結果、最終的に鬱になってしまいました、、。そしてブログを書くこともやめてしまいました。
そんな中著者はあるとき自己理解についての記事を読み、次第に自己理解に対する興味が湧いていきました。それが最終的には現在のように自己理解プログラムとしてビジネスができるほどになっています。
著者は過去のコンビニバイトとブロガーの原体験をもとに自己理解について研究しました。そして、自己理解で本当にやりたいことを見つけることは簡単な公式に当てはめれば誰でもできるものなのだということを発見します。この記事ではその公式を重点的にご紹介します。
結論
先に公式の結論から述べます。本当にやりたいことの見つけ方は以下の公式に当てはめれば誰でも簡単に見つかります。
本当にやりたいこと = 好きなこと ✖︎ 得意なこと ✖︎ 大事なこと
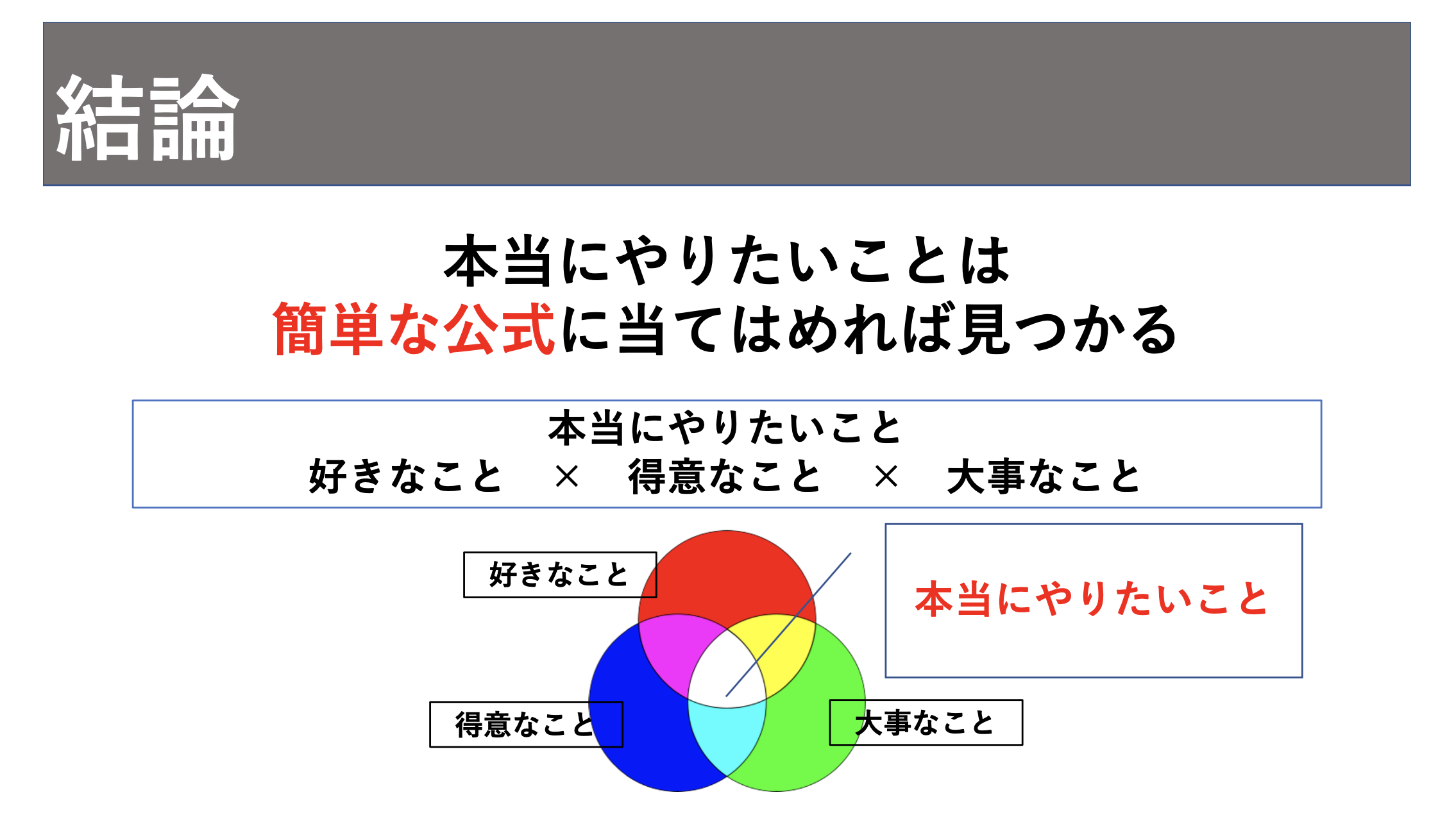
図で分かる通り公式には3つの変数があります。
- 好きなこと
- 得意なこと
- 大事なこと
この変数を全て当てはめて3つが共通している部分が本当にやりたいことになります。
本では、【大事なこと → 得意なこと → 好きなこと】の順番で変数を当てはめていくべきだと述べられているので、大事なことから紹介していきます。
大事なこと
大事なこととは何でしょうか?
それは人生をどういきたいか、つまり人生の目的は何なのかということが大事なことです。いきなり壮大ですね笑でも、誰しもが無意識のうちに人生の目的を持っているものなんです。ここでいう人生をどういきたいかは「あなたの価値観」と置き換えればわかりやすくなると思います。
例えば、以下のような例は全て人生の目的です。
- 自由に生きたい
- 人を楽しませたい
- 人に優しく生きたい
限りある人生の中で何を成し遂げていくのか、何をしていたいのか、何が幸福であるか。それらは決まって各々の心中にあるものであり、あなたの価値観となっています。その価値観があなたが譲ることができない大事なことなのでしょう。
なぜこの価値観を見つける必要があるのかというと、この価値観があなたの仕事の目的を定義するからです。この価値観を自分と他人に与えることが仕事の目的になるのです。

「??????」
疑問に思った皆さん、ちょっと待って。説明します。
この価値観を自分に与えるのはすごくわかりやすいですよね。例えば、「人を楽しませたい」人が仕事をしているときに人を楽しませれたら、それはその仕事が自分の価値観を満たしてくれていますよね。自分の価値観がそのまま仕事の目的になっています。
では価値観を他人に与えるとはどういうことでしょうか。
価値観を他人に与えるとはつまり、あなたが大事にしていることと同じ体験を他人にしてもらうということです。例えば、上述した「人を楽しませたい」人はなぜ人を楽しませたいのでしょうか。おそらくその人はその人が楽しんでいる時がいちばん人生が充実していると考えてるから、人を楽しませたいとおもっていると予想できます(誰しもがそうではありませんが、、)。だからこの人生が充実している状態を他の人にも届けたい、だから人を楽しませたいという価値観の元仕事をするのです。これが価値観を他人に与えるということです。
著者の自己理解の例を使って説明すると、下の図のようになります。
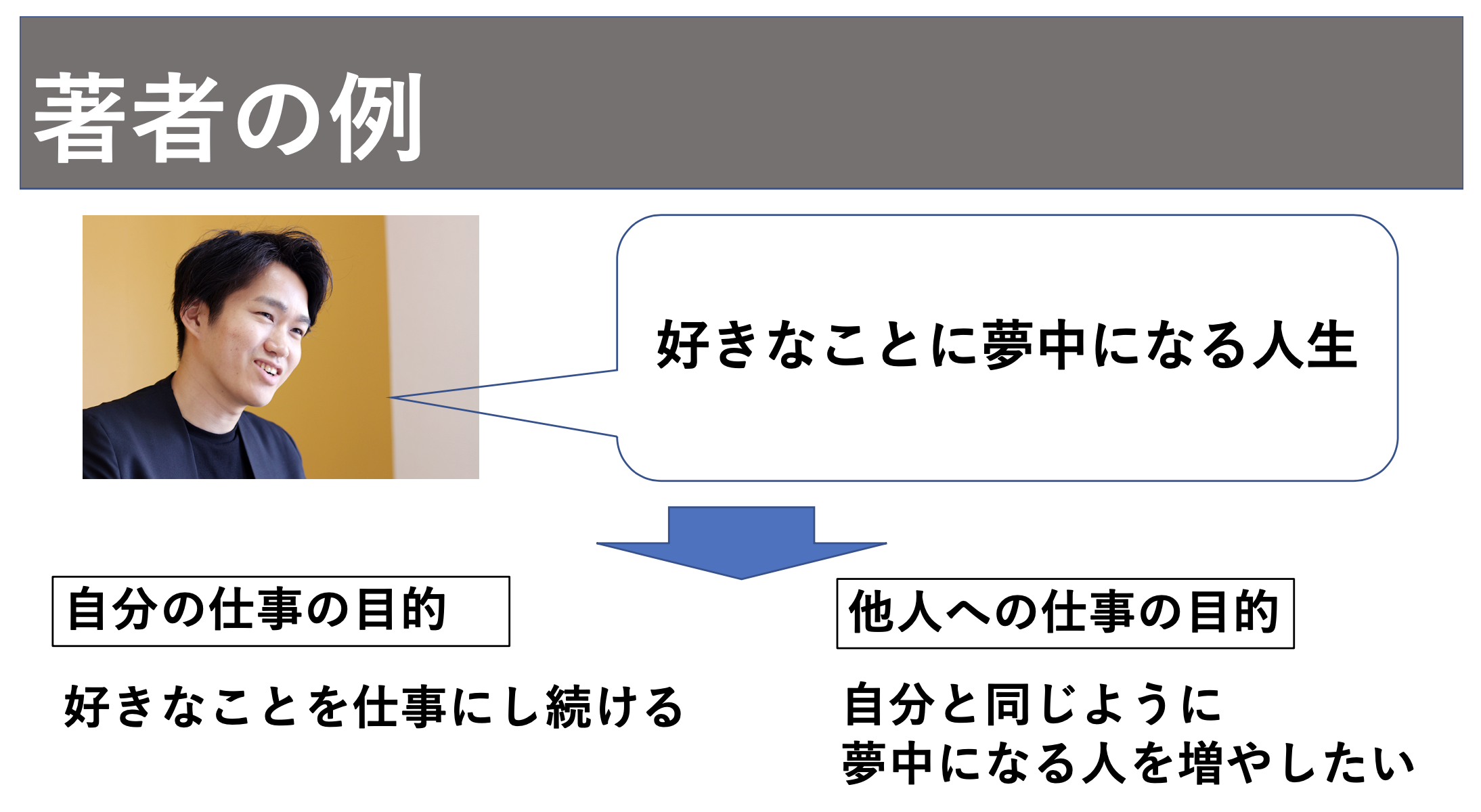
自己理解を知り好きなことに夢中になる人生が大事なことであることを知った著者は、仕事では好きなことを仕事にし続けるという目的で自己理解を仕事にし、自分と同じように好きなことに夢中になる人を増やすために自己理解プログラムを運営しています。
大事なことが他人への仕事の目的になる感覚は実のところ自分もあまりよくわかっていません。。。ですが、自分の大事にしている価値観の源泉が他の人にも体験していただけるのであれば、それは非常に嬉しいことなんだと思います。
得意なこと
大事なことの理解はめちゃくちゃ大変だったと思いますが、得意なことは非常に単純明快なものです。
得意なこととは「無意識の癖」です!
「??????」
待って逃げないでお願いだから。
「得意なことが無意識の癖?得意なことって運動とか音楽とかそういう才能じみたことなのかと思うのですが?」と自分は最初思いました。著者が言う得意なことは才能ではなく、普段無意識でやっていること全てなのだそうです。
例えば、
- 右手で字を書く
- 慎重に行動する
- 自分から勉強する意欲を作れる
これらが全て得意なことになります。言い換えるならば、「やっていて苦しくないこと」なのだそうです。

やっていて苦しくないことってすごく大事な視点です。つまり、自分は当たり前にできているのに、他の人は当たり前にできていないということです。
例えば、自分は毎日勉強時間を現在当たり前のように確保しています。しかし、他の人がこれをできるかと言ったらそうではないです。勉強嫌いで毎日だらだら過ごす人もいます。このように自然に自分がやっていることをリストアップしましょう。
得意なことを見つけることで何が分かるのかと言うと、あなたにとって適切な職業、業務内容が決まります。例えば、慎重に行動することが無意識である人が下記の図のどちらの業務が適切でしょうか?
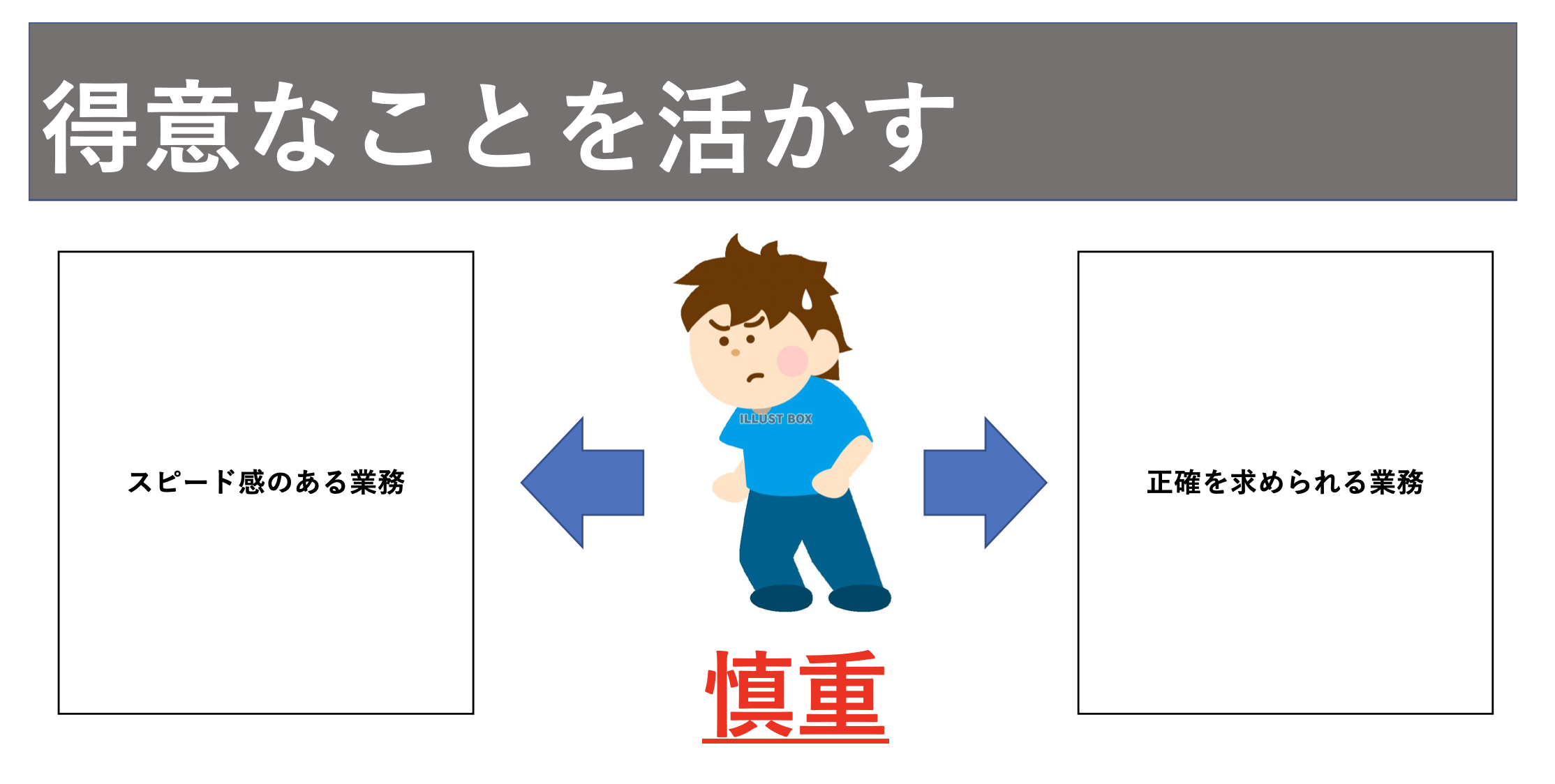
慎重な人がスピード感のある業務をやるのであればそれは適切ではないでしょう。慎重に行動することが無意識のうちに行動しているのに、それを意識的に変えなければならないのですから。逆に性格を求められる業務は適切と言えるでしょう。
このように無意識の癖をリストアップすることで職業や業務内容が明らかになり、あなたに適したポジションが何なのかが明確になっていきます。
得意なことの補足
ここで本にはなかった自分の意見なのですが、自分は無意識にできているもの = 習慣化できているものと定義しました。
自分は習慣化する取り組みを過去何度か行ったのですが、習慣化できたものと習慣化できなかったものがあります。
習慣化できた
- 毎日プログラミング勉強
- ブログのアウトプット
習慣化できなかったもの
- 毎日料理をする
- 超早起き(5時ぐらい)
毎日料理をするなんて他の人にとったらお茶の子さいさいだと思うんです。でも自分はできません笑。逆にブログのアウトプットを嫌ってやらない人もいるでしょう。でも自分はできます!ドヤ!
このように習慣化できたものと習慣化できなかったことを分別し、習慣化できたものを分析すると、いろいろな無意識の癖が出てきます。例えば、毎日プログラミング勉強が苦しくないのであれば、「勉強を続けることが苦しくない」、「何かを作ることが苦しくない」といったたくさんの苦しくないことが見つかります。これが無意識の癖ということでしょう。
このことから、習慣化に取り組むことで失敗することはメリットと考えるようになりました。なぜなら、習慣化できなかったものは「やっていて苦しいもの」であり、苦手なこととして割り切ることができるからです。なのでいっぱい習慣化に取り組んでみましょう!失敗したらそれはあなたの得意ではないことです。

好きなこと
これはいちばん単純明快ですね。興味を持ち続けられるもの、疑問が次から次に湧いてくるものが好きなことです。
好きなことを仕事にすればモチベーションは無限に湧いてくるものです。仕事をしている時も楽しいですし、働くことが楽しくてやめられません。
お金を目的にして仕事をする人はここが弱いです。何のために仕事をしているのかわからず、モチベーションがわきません。かえって苦しいです。
でもこれって当たり前のことですよね。自己分析の本とかネットの安直な記事にもありそうです。
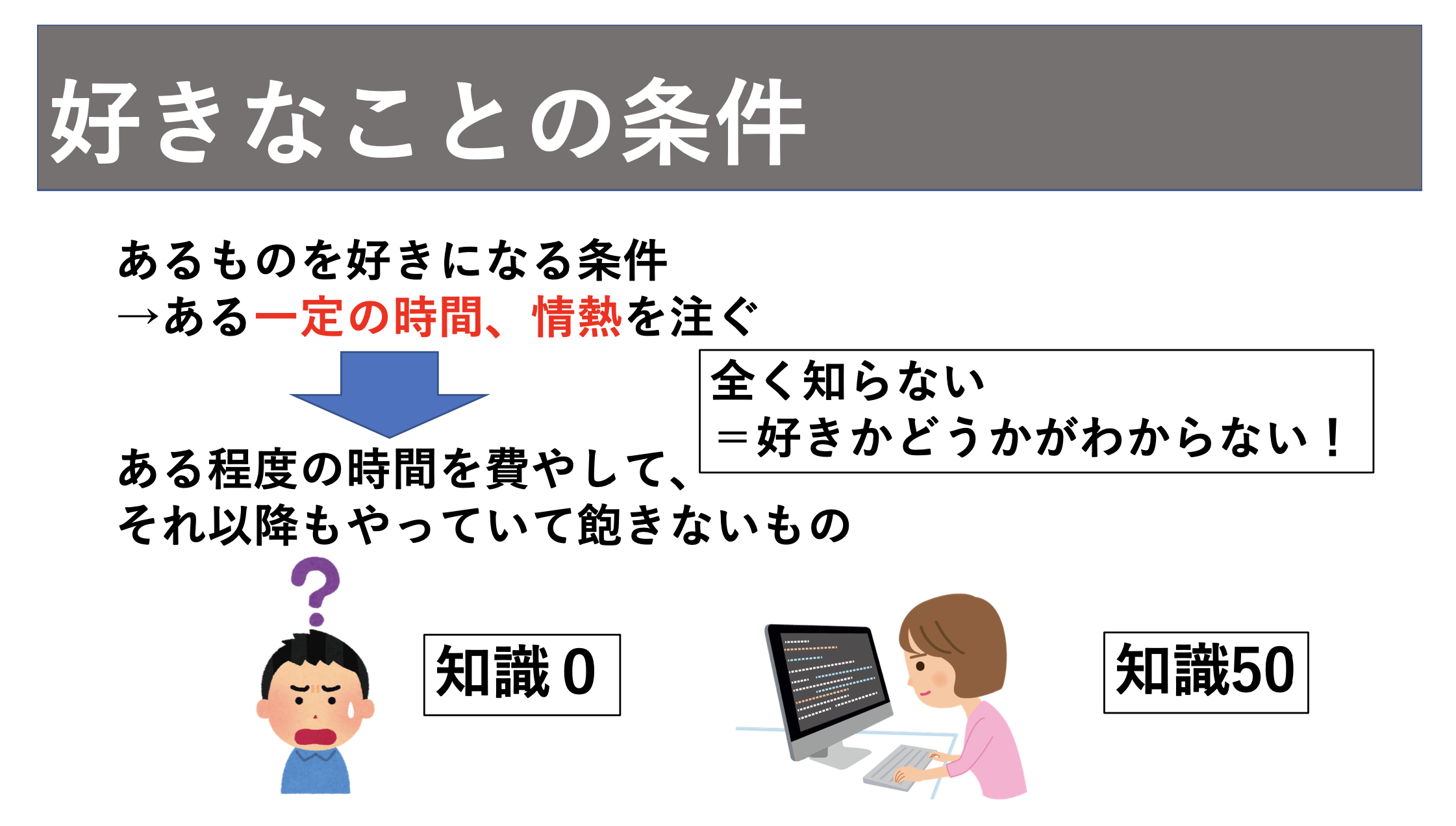
しかし、著者はここでも従来の自己分析とは異なる好きなことを定義しています。好きなことは疑問が湧いてしかたないことですが、それは今そうでなくても良いということです。なぜなら、今好きでないものは将来的に好きになるかもしれないからです。
好きでないものが好きになるためには一定の時間、情熱が必要です。ある程度時間を費やして、それ以降もやっていて飽きないものが好きなものになります。
例えば、私は現在プログラミングを勉強していてかなり好きになり、現在も勉強をしています。しかし、最初は本当に理解できず、意味もわからず、なんだこれとめちゃくちゃストレスでした。エンジニアは皆最初そうだったに違いありません。しかし、プログラミングを勉強していくうちにある程度理解を深めていきプロダクトを完成させるまでに至ると、プログラミングが好きになりました。好きなものはこうして変わっていくのです。
本当にやりたいことを仮説する
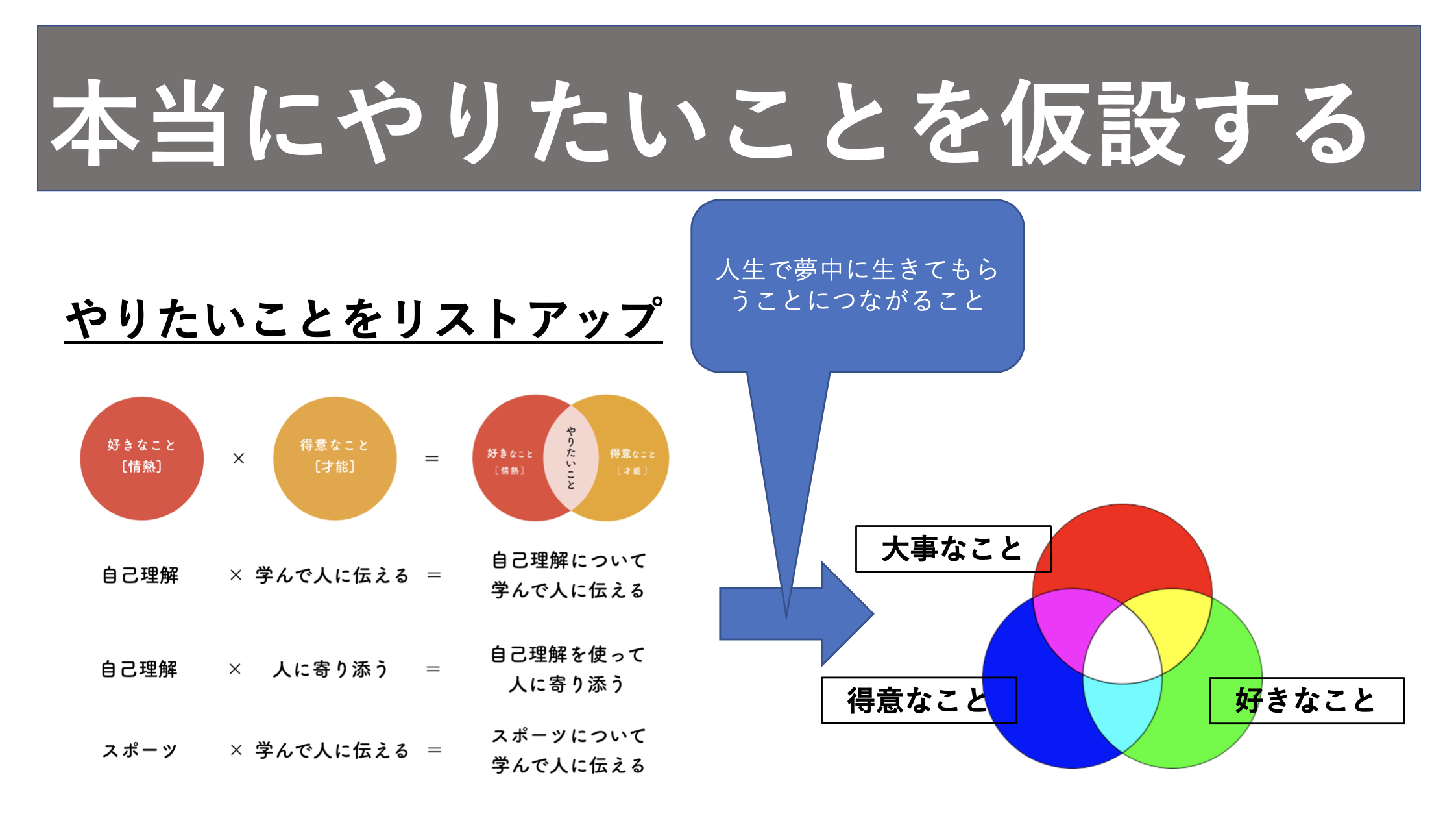
好きなこと、得意なこと、大事なことを見つけたとはそれを公式に当てはめます。まずはやりたいことをリストアップします。やりたいことは好きなこと ✖️ 得意なことです。
面白いことはどこかの要素が共通していても、他が違えばやりたいことは違ってくるということです。例えば、著者のように自己理解が好きでも得意なことが人に寄り添うことであればやりたいことはカウンセリングとかの1対1の仕事になります。
このようにやりたいことをリストアップした後は大事なことと合わせて、そのやりたいことが自分にあっているのかを確認します。このように、やりたいことに大事なことを掛け合わせることで本当にやりたいことが見つかります。
ですが、本当にやりたいことが見つかったとしても、それは仮説です。実際にやってみて違ってしまう場合もあります。それは、3つの要素の何かが間違っているからかもしれません。なぜなら、3つの要素はあなたの考えであり、あなたしかわかりません。だからこそ、本当にやりたいことが見つかってもそれはあくまで仮説なのです。だから、その仮説を検証するために就職、転職、起業をするのです。
結論
結論を再び載せますが、
本当にやりたいこと = 好きなこと ✖︎ 得意なこと ✖︎ 大事なこと

そして各要素に関してはざっくりですが

という感じになります。
終わりに
自己分析で迷っているかたや人生で迷走している方にとてもお勧めできる一冊です!本当にやりたいことを見つけてもっと幸せに生き続けることができますように。
【Ruby】?の付くArrayクラスのインスタンスメソッド
はじめに
みなさんこんにちは。大ちゃんの駆け出し技術ブログです。
今回は?がつくArrayクラスのメソッドです。基本的には簡単なものが多いです。
all?
レシーバーである配列の要素が全て真であればtrueを返却し、要素の中に一つでも偽である要素があればfalseを返すメソッドです。極端にいうと下のような感じ。
[true, true, true].all? # => true [true, false, true].all? # => true
単体だとあまり使い勝手が良くありませんが、ブロックを渡すとかなり便利に使用できます。
例えば、全ての配列の要素が0より大きい数字であればtrueを、一つでも負の数があればfalseを返して欲しいとします。様々な方法が考えられますが、無理やり下記のように実装してみましょう。
result = true [1, 2, 3].each do |num| if num < 0 result = false break end end
一つでも負の数があればfalseを返して繰り返し処理を終了する処理です。確かにこれでも実装できますが少々コードの記述が多くなってしまいます。
上記のコードをall?メソッドにブロックを渡して実装してみます。
[1, 2, 3].all? { |num| num > 0 }
これで上述したコードと同じような処理になります。条件式でブロックを渡すことで各配列の要素をその条件式に代入することができます。
空の配列に対してall?メソッドを使用する場合はtrueを返します。
[].all? # => true [].all? {|num| num > 0 } # => true
any?
全ての要素がfalseの場合にのみfalseを返します。どれか一つの要素がtrueの場合直ちにtrueを返します。挙動としてはall?と似ていますが、all?の場合は全ての要素が&&演算子のようにtrueでなければいけませんが、any?の場合は||演算子のようにどれか一つでもtrueであればtrueを返します。
[-1, -2, 3].any? { |num| num > 0 } # => true
空の配列に対してany?メソッドを使用する場合はfalseを返します。
[].any? # => false [].any? {|num| num > 0 } # => false
empty?
レシーバーの配列の要素数が0の場合はtrue、そうでなければfalseを返却します。
[].empty? # => true [1].empty? # => false
empty?は配列だけでなく、Stringクラスのインスタンスメソッドでもあります。文字数が0の時だけtrue、それ以外はfalseを返します。
"111111".empty? #=> false " ".empty? #=> false "".empty? #=> true
eql?(array)
レシーバーと引数の配列が等しいかどうかを真偽値で返すメソッドです。要素が同じでも配列の順番が違えば異なる配列とみなされます。
[1,2,3].eql? [1,2,3] # => true [1,2,3].eql? [1,3,2] # => false
eql?メソッドはIntegerにもStringにもインタンスメソッドとして定義されています。
"a".eql?("a") # => true
include?(val)
引数のvalと等しい要素がレシーバーの配列に含まれている場合にtrue、含まれていない場合はfalseを返します。
[1,2,3].include?(1) # => true [1,2,3].include?(0) # => false
引数は一つしか指定できないので注意してください。2つの要素が含まれているか確認したい場合は2回include?メソッドを呼び出します。
[1,2,3].include?(0,1) # ArgumentError (wrong number of arguments (given 2, expected 1)) [1,2,3].include?(1) && [1,2,3].include?(0) # => false
none?
これは完全にall?の逆です。全ての要素がfalseであればtrueを返します。逆に一つでもtrueの要素があればfalseを返します。少しややこしいですね。
[false, false, false].none? # => true [false, false, true].none? # => false
ブロックを渡せばall?と同様に条件式を渡すことができます。
[1, 2, 3].none? { |num| num < 0 } # => true
one?
今まで紹介きたメソッドと似ていますが、一つの要素だけ真だった場合にtrue、それ以外はfalseを返すメソッドです。
[false, false, true].one? # => true [false, true, true].one? # => false [false, false, false].one? # => false
一つの要素だけが真であることを確認するために処理は2つ目の真の値が確認されるまで続きます。
【Ruby】eachの付くArrayクラスのインスタンスメソッド
はじめに
みなさんこんにちは。大ちゃんの駆け出し技術ブログです。
先日の記事ではArrayクラスのインスタンスメソッドを中心に記事を出しましたが、記事では書かなかったeachの付くメソッドがいくつもあったので本記事ではそれを紹介します。
メソッドは英単語と同じで知っているか知らないかで変わってくるので、覚えておいて全く損はないなと思います。
each
言わずと知れたRubyの繰り返し処理で頻出するメソッド。元の配列の各要素を評価するメソッドですね。
[1, 2, 3].each do |i| puts i end #=> 1 # 2 # 3
基本的には他のeachが付くメソッドはこのeachメソッドがベースとなっています。
ちなみにこのeachメソッドを使う際は他の方法で再現可能かどうかを考えるべきだそうです。eachの処理は繰り返し処理の基本の処理であり、複雑な処理をする場合は他のメソッドで再現可能担っていることが多いそうです。
例えば、以下のようにわざわざ空の配列を作成して別の配列を加工したものを空の配列に格納するようなメソッドはmapメソッドで代用可能です。
list = (1..5).to_a # [1,2,3,4,5]の配列 array = [] # 空の配列を用意 list.each do |i| array << i * 2 # 要素を2倍にしたものを空の配列に格納 end
mapメソッドを使う場合
list = (1..5).to_a # [1,2,3,4,5]の配列 array = list.map { |i| i * 2 }
mapを使う方が明らかにシンプルにかけます。Arrayクラスのインスタンスメソッドは複雑な処理が非常に多く用意されていると思うので、eachを使う場合はその処理を他のメソッドで置き換えることが可能かどうかを意識した方がよさそうです。
each_index
eachの時は配列の要素を取得しましたが、こちらはインデックスの値を使用して処理を行います。
["a", "b"].each_index do |i| puts i end #=> 0, 1
正直この処理はあまり使いどころが思い浮かびませんでした。元の配列の要素を使用した評価ができないからです。
インデックスを使う場合は次に紹介するeach_with_indexの方が使う機会が多そうです。
reverse_each
eachのレシーバーの要素を逆にして評価を行うメソッドです。
a = [ "a", "b", "c" ] a.reverse_each {|x| puts x } #=> a, b, c
上記は下記の処理を1つのメソッドにまとめたものです。
a = [ "a", "b", "c" ] a.reverse.each {|x| puts x } #=> a, b, c
2つのメソッドだと効率が悪いので1つにまとめているという感じですね。コードの記述量は変わりません。
each_with_index
each_with_indexはeachとeach_indexを組み合わせたものです。ブロック内で使えるものは要素とその要素のインデックス番号です。
["a", "b"].each_with_index do |s, i| puts [s, i] end #=> ["a", 0] # ["b", 1]
このメソッドを使う例として、評価時の要素の前後の要素のインデックス番号を取得したい時などに使用できると思います。
ary=["a", "b", "c"] count=ary.size ary.each_with_index{|v,i| prev_idx = (i-1)%count next_idx = (i+1)%count }
この処理は自分のスクールの受講生さんがアウトプットしていた処理です。配列の要素数を取得して
count=ary.size
インデックス番号からマイナス1をした値を配列の要素数で割った余りが評価中の要素の手前のインデックス番号(prev_idx)、プラス1をした値を配列の要素数で割った余りが評価中の要素の後ろのインデックス番号(next_idx)になります。
ary.each_with_index{|v,i|
prev_idx = (i-1)%count
next_idx = (i+1)%count
}
実際に出力してみると確認できます。
ary=["a", "b", "c"] count=ary.size ary.each_with_index{|v,i| prev_idx = (i-1)%count next_idx = (i+1)%count p "#{v}を評価中" p "手前は#{ary[prev_idx]}" p "後ろは#{ary[next_idx]}" } #=> "aを評価中" #"手前はc" #"後ろはb" #"bを評価中" #"手前はa" #"後ろはc" #"cを評価中" #"手前はb" #"後ろはa"
each_cons
このメソッドは先に処理を見てもらった方が理解できると思います。
list = (1..5).to_a list.each_cons(3) {|v| p v} # => [1,2,3], [2,3,4], [3,4,5]
each_consは引数に数値を指定する必要があります。
each_cons(n) # nは自然数
この数値の数で先頭から要素を区切って、その区切った要素を配列としてブロック内で使用することができます。
{|v| p v} # vには区切った配列:1巡目であれば[1,2,3]
次の巡目ではレシーバーの配列の次の2つ目の要素を先頭に引数の数で区切った配列をブロック内で使用します。
{|v| p v} # vには区切った配列:2巡目であれば[2,3,4]
この循環処理は区切った配列の要素にレシーバーの配列の最後の要素が含まれた場合に終了します。
この処理は言葉では説明しづらいですが処理を見ればかなりわかりやすいですよね。
ちなみに、もし引数がレシーバーの要素数より大きい場合何も出力されません。つまりエラーにもなりません。
list = (1..5).to_a list.each_cons(6) {|v| p v} # => 何も出力されない
each_slice
こちらも先に処理を見てみましょう。
(1..10).each_slice(3) {|v| p v} # => [1, 2, 3] # [4, 5, 6] # [7, 8, 9] # [10]
each_consと異なる点としては、循環する際に次の要素に手前の要素が含まれないということです。
each_cons
(1..10).each_cons(3) {|v| p v} # => [1, 2, 3] # [2, 3, 4] # 前の処理の要素が含まれている
each_slice
(1..10).each_slice(3) {|v| p v} # => [1, 2, 3] # [4, 5, 6] # 前の処理の要素は含まれない
そして、最後の要素数が引数の数値より少ない場合でも配列として出力されます。
(1..10).each_slice(3) {|v| p v} # => [1, 2, 3] ・ ・ # [10] # 引数の数より少ないけど出力される
each_with_object
引数にオブジェクトを指定してそのオブジェクトとレシーバーの各要素を使用してブロック内で処理を行います。
[1, 2, 3].each_with_object [] do |i, array| array << i**i p array end # [1] # [1, 4] # [1, 4, 27]
面白い点としては渡したオブジェクトが繰り返し処理で更新されていくところです。どういうことかというと、以下のように渡したオブジェクトに対して要素を追加すると、
array << i**i # 空の配列に1が格納される
次の処理ではarrayに1の要素が格納されている状態になります。
array << i**i # [1]の配列に4が格納される
引数で渡すオブジェクトはオブジェクトであれば何でもいいのでかなり使い勝手が良さそうです。
【Ruby】Arrayクラスのインスタンスメソッド
はじめに
こんにちは!大ちゃんの駆け出し技術ブログです。
個人的にRubyのメソッドを学習したくて、現在「Rubyがミニツク」などでメソッドの使い方を学習しています。やはりあまりにも数が多く、「どうせググるし覚えなくてもいいんじゃね」という甘えた考えが出てきてしまいます。ですが、頭の片隅にでも各メソッドの動きをちょこっと覚えておくだけでも、もっと簡単にコードをかけたりするものだと思うので、今回はArrayクラスのRubyのメソッドについて学習します。
全部はアウトプットできない
とはいうもののArrayクラスのメソッドは大量です。(どのクラスもそうですが)

ですので、比較的に利用頻度の高いメソッドを紹介します。伊藤淳一さんが利用頻度の高いメソッドを下記記事で提示していますので、そこから個人的に使ったことがない物を紹介します。
それだけだと伊藤さんの記事を見ればいいじゃんとなるので、Arrayクラスのインスタンスメソッドからもいくつか紹介します。下記の合計8個のメソッドを取り上げます。
- flatten/flatten!/flat_map/collect_concat
- transpose
- zip
- uniq/uniq!
- each_with_index
- difference
- filter_map
flatten/flatten!/flat_map/collect_concat
flatten は入れ子構造になっている配列を平坦化した配列を生成して返します。平坦化とはつまり入れ子構造になっていない状態です。
a = [1, [2, 3, [4], 5]] p a.flatten #=> [1, 2, 3, 4, 5]
変数aは3重の入れ子構造になっていますが、flattenを使うことで入れ子構造になっている箇所が全て平坦化されます。flattenは「平らにする」という意味で、名前と処理が似ているので覚えやすいです。
前提としてレシーバーは入れ子構造の配列でないと変化がありません。入れ子構造になっていない配列をレシーバーにすると、そのまま平坦な配列が返却されます。
a = [1, [2, 3, [4], 5]] p a.flatten #=> [1, 2, 3, 4, 5] p a.flatten.flatten #=> [1, 2, 3, 4, 5]
flattenは元の配列を破壊しませんが、flatten!は元の配列を破壊します。
a = [1, [2, 3, [4], 5]] p flatten #=> [1, 2, 3, 4, 5] p a #=> [1, [2, 3, [4], 5]] p flatten! #=> [1, 2, 3, 4, 5] p a #=> [1, 2, 3, 4, 5]
flat_mapはmapメソッドとflattenメソッドの組み合わせたような処理をします。collect_concatはflat_mapのエイリアスです。
mapメソッドだけだと下記のような入れ子構造の配列に対して全ての要素を2倍にした場合、返却される値も入れ子構造になってしまいます。
[[1,2], [3,4]].map{|array| array.map{|j| j*2}} # => [[2,4], [6,8]]
flat_mapを使うことで返却値を平坦な配列にすることができます。
[[1,2], [3,4]].flat_map{|array| array.map{|j| j*2}} # => [2,4,6,8]
transpose
transposeメソッドはレシーバーの配列を行列と見立てて、行列の入れ替えをするメソッドです。
p [[1,2], [3,4], [5,6]].transpose # => [[1, 3, 5], [2, 4, 6]]
行列の入れ替えのためにレシーバーの配列は下記要件を満たしておく必要があります。
まずレシーバーは入れ子構造になっていないといけません。行列と見立てることができないためです。よって平坦な一次元配列をレシーバーとするとエラーが起きます。
[1,2,3].transpose # => TypeError (no implicit conversion of Integer into Array)
[[1,2], [3,4], [5,6,7]].transpose # => IndexError (element size differs (3 should be 2))
しかし、空の配列に他してはレシーバーにすることができます。
[].transpose
# => []
zip
引数に渡した配列の各要素からなる配列とレシーバーの配列を組み合わせた入れ子構造に配列を返却します。入れ子の数はレシーバーの要素数に準拠します。引数の要素数がレシーバーの要素数より少ない場合、入れ子の中の該当箇所の要素はnilになる。
a1 = [1,2,3] => [1, 2, 3] a2 = [4,5] => [4, 5] a3 = [6,7,8,9] => [6, 7, 8, 9] a1.zip(a2,a3) => [[1, 4, 6], [2, 5, 7], [3, nil, 8]] # レシーバー(a1)の要素数は3なのでa3の4番目の要素は消える a1 = [1,2,3,4] => [1,2,3,4] a1.zip(a2,a3) => [[1, 4, 6], [2, 5, 7], [3, nil, 8], [4, nil, 9]] # レシーバー(a1)の要素数は4なので4つの配列が返却される
uniq/uniq!
配列から重複した要素を取り除いた新しい配列を返します。この処理はかなり使い勝手が良さそうですね!
[1,2,3,4,5,6,1,2].uniq # => [1,2,3,4,5,6]
uniqについて面白いと思ったのはブロックを与えると挙動が変化することです。例えば下記のような配列があるとします。
[1,2,3,4,5,6,"1","2"]
これにuniqメソッドを使用しても返却される配列に変化はありません。1はintegerですが"1"はstringだからです。
[1,2,3,4,5,6,"1","2"].uniq #=> [1,2,3,4,5,6,"1","2"]
しかし、uniqメソッドにブロックを以下のように渡すことで、ブロックが返した値が重複した要素を取り除いた配列を返します
[1,2,3,4,5,6,"1","2"].uniq { |n| n.to_s } #=> [1,2,3,4,5,6]
評価の順番は先頭の要素からです。つまり、もしstringの"1"と"2"がintegerの1,2より先頭に近い要素にあれば、取り除かれるのはintegerの1と2になります。
["1","2",1,2,3,4,5,6].uniq { |n| n.to_s } #=> ["1","2",3,4,5,6]
each_with_index
要素とそのインデックスをブロックに渡して繰り返し処理を実行します。
ary=["a", "b", "c"] ary.each_with_index{|v,idx| p v p idx } # => "a", 0, "b", 1, "c", 2
eachで繰り返し処理を行うよりもこちらの方がより複雑な処理をすることができそうです。
difference
引数の配列の要素を取り除いた配列を生成して返します。
[ 1, 1, 2, 2, 3, 3, 4, 5 ].difference([ 1, 2, 4 ]) # => [ 3, 3, 5 ]
挙動としてはかなりシンプルです。引数は必ず配列ではないといけないため、注意してください。
[ 1, 1, 2, 2, 3, 3, 4, 5 ].difference(1,2,3) # => TypeError (no implicit conversion of Integer into Array)
【個人用】gemの使用理由まとめ
はじめに
こんにちは!大ちゃんの駆け出し技術ブログです。 下記Gemfileですがこれが自分のPFで使用したものです。
# Gemfile source 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.7.3' gem 'rails', '6.0.3.5' # Assets gem 'sass-rails', '>= 6' gem 'webpacker', '~> 4.0' # Authentication for Slack gem 'devise', github: 'heartcombo/devise', branch: 'ca-omniauth-2' gem 'ginjo-omniauth-slack', require:'omniauth-slack' gem "omniauth-rails_csrf_protection" # Slack API gem 'slack-ruby-client' # OGP gem 'meta-tags' # 権限 gem "pundit" gem "administrate" # Serializer gem 'active_model_serializers', '~> 0.10.0' gem "ams_lazy_relationships" gem 'puma', '~> 4.1' gem 'carrierwave' gem 'fog-aws' # Config gem 'dotenv-rails', require: 'dotenv/rails-now' gem 'parser', '< 2.6.6.0' # cron gem 'whenever', require: false # Database gem 'pg', '>= 0.18', '< 2.0' gem 'redis-rails' # Model gem 'enum_help' gem 'active_hash' gem 'public_uid' # UI/UX gem 'rails-i18n' gem 'devise-i18n' gem 'jbuilder', '~> 2.7' gem "tailwindcss-rails", "~> 0.3.3" gem 'slim-rails' gem 'html2slim' # Error monitoring gem 'sentry-rails' gem 'sentry-ruby' # Performance monitoring gem 'newrelic_rpm' gem 'bootsnap', '>= 1.4.2', require: false group :development, :test do # Test gem 'factory_bot_rails' gem 'rspec-rails' gem 'simplecov', require: false #CLI gem 'spring' gem 'spring-watcher-listen', '~> 2.0.0' gem 'spring-commands-rspec' # Debugger gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] gem 'better_errors' gem 'binding_of_caller' gem 'pry' gem 'pry-byebug' gem 'pry-doc' gem 'pry-rails' # Code analyze gem 'rails_best_practices' gem 'rubocop' gem 'rubocop-checkstyle_formatter' gem 'rubocop-rails' gem 'rubocop-rspec' end group :development do gem 'bullet' gem 'foreman' gem 'listen', '~> 3.2' gem 'web-console', '>= 3.3.0' end group :test do gem 'capybara' gem 'faker' gem 'webdrivers' gem "webmock" end gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]
今回は各Gemの使用理由を雑に述べていきたいと思います。
devise
言わずと知れた認証系アプリに必要な機能を簡単に追加できる便利なgem
仕様理由
Slackログインの方法を様々な方法で試した結果、deviseとomniauthの方法しかできなかったため。
SlacKという比較的ユーザ情報の悪用の危険度が高いものを使用するので、認証周りはあまり自分でコーディングすることはセキュリティ面で不安だったため避けたかった ↓ 認証gemを使用することは必須 ↓ * Sorcery・・・slack.rbが2016年より更新されていなかったため、正しく認証できずエラーが返ってきていた。
もうエラーは解決されたみたい。正しくログインできるかもしれない。 github.com
devise-token-auth・・・講師にもPRを出して1週間ほど試していたが解決できず断念
devise × omniauth・・・唯一slackログインが正常にできて、かつ認証をdeviseに任せられる方法だった
~'heartcombo/devise’とマスターブランチを指定している理由は対応Gemがrubygemsにリリースされていないので、masterブランチを指定している
~gem 'devise', github: 'heartcombo/devise', branch: 'ca-omniauth-2'と指定している理由については下記記事を参照
gem 'ginjo-omniauth-slack', require:'omniauth-slack'
Slackのauth用のgem。
仕様理由
比較的スター数が少ないが、メンテナンスが頻繁にされていたため使用しました。 用途としてはauthと同じ。
require:'omniauth-slack'としている理由は公式の書き方にそう書いてあるから
gem "omniauth-rails_csrf_protection"
仕様理由
omniauth2.0に対応するため。詳しくは下記記事。
gem 'slack-ruby-client'
SlackとAPI通信を行うためのgem。
仕様理由
botと通信を行うときには基本的にこれを使っている。 ※ ユーザーの投稿とかは基本的にfaradayでAPI通信。
gem "pundit"
認可を管理するGem
仕様理由
Pundit vs cancancan
Punditの場合各モデルに対して権限を設定できる
cancancanの場合、各モデルの権限をすべてAbilityファイルに記述する
よって、モデル数が多い自分のアプリではPunditのほうがいいと思った
gem "administrate"
管理画面自体は自分だけがログインできる実装
理由:管理周りでもしミスでもしてSlack情報流れたら怖いと思い、自分だけが管理できる仕様にした。
よって比較的簡易的に管理画面を実装したかった
rails_admin active_admin Administrate
Administrateを選んだ理由は後々管理画面を実装する際にお客様にも使ってもらう必要があるため、カスタマイズの拡張性が高いgemを選んだ
gem 'active_model_serializers', '~> 0.10.0'
仕様理由
スター数が多きいのと、各モデルのシリアライズされたときのJSONのカスタマイズが容易。
gem "ams_lazy_relationships"
仕様理由
batch_loaderを使用してActiveModelSerializerのN + 1問題を良しなに解決してくれるgem
理由が少し心配なので後で下記記事から理由を抽出 bajena3.medium.com
gem 'carrierwave'
画像をアップロードするときに使われるライブラリ。
仕様理由
viewsをvue.jsで書く場合は、Carrier Waveを使うらしい(下記記事を参照)
- 理由 erbを書かない場合はactive storageの強みを活かせない
erbを使うか否かの違いは、HTML内に<%= %>を使えるかどうか Active Storageは前提として、<%= %>でform_withで入力したりや@imageとかで画像表示をする時に、この中に画像の処理を記述することで、controllerのコード記述を少なく書ける
言い換えれば、<%= %>を使わずに画像を処理・保存するとなると、どこで画像処理などのプログラムを記述すれば良いかわかりにくい
その点、CarrierWaveを使う方法では、CarrierWave::Uploaderというクラスが生成され、ここに画像の処理するコードを記載すれば良いんだなとわかりやすい
gem 'fog-aws'
carriwaveを使用してAWSにアップロード。
仕様理由
carriwaveの通常の保存先はpublic/uploads配下
ファイルが重くなるためAWSのS3にアップロード
gem 'dotenv-rails', require: 'dotenv/rails-now'
環境変数管理
仕様理由
シンプルに環境変数を記載できる
heroku上だと環境変数をいちいち指定しなければならない。
master.keyファイルをアップロードできるのがcredentialを使用するメリット
gem 'enum_help'
仕様理由
enumの値を国際化できるから。機能が仕様理由。
gem 'active_hash'
仕様理由
Prefectureを登録する際に固定値となるため導入
のちにCategoryテーブルを追加するときにも使用
しかし、Categoryテーブルの場合はカテゴリーが増える可能性があったため、テーブルを作ってしまえばよかったと反省している
わざわざデプロイせずともデータを作成すればCategoryを追加できるのが強み
gem 'public_uid'
ランダム値を格納するカラムを作成。
仕様理由
SecureRandomの存在を知らなかった。。。変更するか検討する。
gem "tailwindcss-rails", "~> 0.3.3"
tailwindをインストールする
仕様理由
プロフ帳のデザインにする以上、Bootstrap感はあまり出したくなかったため導入
他にもsemantic UIとかあったけど、Tailwindのほうが流行っていたと感じたため導入
ファイル自体は非常に重いらしいが導入してそこまで重いと感じなかったので使用
gem 'sentry-rails' & gem 'sentry-ruby'
Sentryを導入するgem
仕様理由
bugsnagと比較してドキュメントの記事数が豊富
Heroku上だと一番使われている
それに伴う開発サポート
gem 'newrelic_rpm'
アプリケーションのパフォーマンスをあらゆる角度からリアルタイムで可視化
仕様理由
正直まだ活用できていないので後で見る
gem 'factory_bot_rails'
定義構文をわかりやすく書くことができるテストデータを作成するgem
仕様理由 テストデータとしては一番メジャーだと思う
gem 'rspec-rails'
こちらも言わずと知れたテストGem。
仕様理由
Miniテストよりも多く現場で使われているテスト形式だから
gem 'simplecov', require: false
Rspecで書いたテストのカバレッジを計測してくれるツールです。カバレッジとは、コード全体に対して、どの程度の範囲をテストがカバーできているかを算出したもの。
仕様理由
ある程度Rspecはちゃんと書きたいと思ってたため、simplecovがあればどの程度の範囲をテストがカバーしているか見れるので便利。
gem 'spring'
Spring は Rails アプリケーションの preloader(プリローダー)の gem 。 Rails アプリケーションをバックグラウンドで走らせたままにしておくことにより(pre + load = 前もってロードしておく)、bin/rails や bin/rake コマンドの2回目以降の起動時間が短縮
gem 'spring-watcher-listen', '~> 2.0.0'
springのファイルシステム検知方法をポーリング方式からlistenを使用した方法に変更する。 ポーリングとは、主となるシステムが他のシステムに対して一定間隔で順番に変更がないか確認する制御方式で、いつ起こるかわからないイベントを監視する際に用いられる。
gem 'spring-commands-rspec'
Springのrspecコマンドを実装
仕様理由 bin/rspecを使うことで二度目以降のrspecの実行時間の短縮につながる
gem 'better_errors'
デフォルトのエラー画面をわかりやすく整形してくれるgem。
仕様理由
デフォルトのエラーが面よりもデバッグがしやすく見やすい
### gem 'binding_of_caller'
上記better_errorsと一緒に使うことで、ブラウザ上でirbを使えるようになるgem。
仕様理由
デバッグが不可彫りできるので便利
gem 'pry'
もしかしたらいらないかも。。。。。。。 調べたら来れなくても動くかもしれない。。。
gem 'pry-byebug', gem 'pry-doc', gem 'pry-rails'
pry-rails
- Rails console で Pry が起動するようになる
- pry-rails を入れるまでは irb が起動する
- show-routes などのコマンドが Rails console で使えるようになる
- Rails console で help と打つと、使えるコマンドがわかる
- binding.pry をソースコード中に挟むとそこがブレークポイントとなり、そこで処理を止めてデバッグできるようになる
- pry-rails だけではステップ実行はできない
pry-byebug
- binding.pry で止めたところからステップ実行ができる
- 例えば next コマンドで一行ずつ実行できる
- $ 現在のソースを表示
pry-doc
- show-method コマンドで C で書かれたコードやドキュメントも出力できるようになる
- show-method は Pry のコマンドで通常は Ruby で書かれたコードやドキュメントのみ出力できる
参考 qiita.com
gem 'rails_best_practices'
rails_best_practicesは、railsアプリのコードの質をチェックするメトリクスツール
gem 'rubocop', gem 'rubocop-checkstyle_formatter', gem 'rubocop-rails', gem 'rubocop-rspec'
Rubyに関わる構文規則チェック
Rubocopを回す際にチェックするフォーマットを指定できる
$ bundle exec rubocop --require rubocop/formatter/checkstyle_formatter --format RuboCop::Formatter::CheckstyleFormatter --no-color --rails --out tmp/checkstyle.xml
Railsに関わる構文規則チェック
rspecに関わる構文規則チェック
仕様理由
インデントやコードに問題がある場合の自動検出。ある程度きれいなコードにしたかった。
gem 'bullet'
N + 1問題を検出できる
仕様理由
モデル数が多くN + 1問題が非常に出やすいと思ったため、bulletを導入
gem 'listen', '~> 3.2'
ファイルの変更、追加、削除を検知し、何かしらの処理を行うことができるようになる。
gem 'web-console', '>= 3.3.0'
ViewまたはControllerのコードに「console」というメソッドを記述することでブラウザ上でコンソールの操作ができるようになる。
gem 'capybara'
ブラウザ上でテストを確認できる
「リンクのクリック」「フォームの入力」「画面表示の検証」などをコマンドでシミュレートできる
仕様理由 Rspecを実行する際にブラウザでも意図したとおりに画面が遷移しているか確認できるため
gem 'faker'
簡単に多種多様なダミーデータをデータベースに投入できるgem
仕様理由 ダミーデータ用
gem 'webdrivers'
webdriverの自動インストール、自動更新を行う。
gem "webmock"
外部へのHTTPリクエストをスタブ化してくれる
外部API呼び出しのあるアプリケーションを開発する場合、テストやローカル環境での動作確認まで本物のAPIを呼び出していると、時間がかかり開発の生産性が下がるのでAPIモックを使用する
仕様理由 APIを使用しているためSlackログイン用のMocなどが必要だった。
gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]
タイムゾーンが記載されたライブラリで、Windowsではタイムゾーンが記載されたファイルがない為、このgemが必要となる。
【オブジェクト指向設計ガイド】単一責任
はじめに
おはようございます!大ちゃんの駆け出し技術ブログです!
綺麗なコードを書きたいということで、 Railsのデザインパターンも学習していますが、下記書籍で綺麗な設計について学んでいます。
オブジェクト指向設計実践ガイド ~Rubyでわかる 進化しつづける柔軟なアプリケーションの育て方
内容は少しわかりづらくポートフォリオ作成段階では理解できなかったのですが、ポートフォリオが完成した今この本を読むと、「あのコードはこう書けばよかったんだな」と思いつつ読み進めることができています。ただ、それでも理解しづらい部分がたくさんあるため今回はこの本の第二章、「単一責任クラス」について要約したいと思います。
変更が簡単なコードとは
オブジェクト指向設計ガイドで「良い」とされている設計は、将来的に変更を加える際にその変更が非常にしやすい状態である設計を指していると思います。変更が簡単なコードにはTRUEの性質が伴うべきだと述べられています。
- 見通しが良い(Transparent)・・・ 変更がもたらす影響・変更箇所が明確にわかっている
- 合理性 (Reasonable)・・・どんな変更でもかかるコストは変更がもたらす利益の割にあっている
- 利用性が高い(Usable)・・・ 新しい環境、予期していなかった環境でも再利用できる
- 模範的(Exemplary)・・・ コードに変更を加える人が上記の品質を自然と保つようなコードになっている
このTRUE品質のコードにするための設計方法がこの本を通して学べることです。そしてTRUE品質のコードにするための最初の一歩とは、それぞれのクラスが単一の責任を持つように徹底することです。
単一責任クラスの見極め方
以下のクラスはこの本の説明で使われる自転車のギアのクラスです。
class Gear attr_reader :chainring, :cog def initialize(chainring, cog) @chainring = chainring @cog = cog end def ratio chainring / cog.to_f end end
Gearクラスは自転車のギアのことを指しています。そしてクラスには3つのメソッドが定義されています。
chainring・・・チェーンリングの大きさ
cog・・・コグの大きさ
ratio・・・ギアの比率を求めるメソッド
Gear.new(52, 11).ratio # => 4.7272727272
上記のGearクラスは現在比率を求めるメソッドとそれを求めるたに必要なメソッドのみが定義されており、極めて単一の責任がある状態と言えます。
しかし、ここで上記のクラスにギアインチを求めることができるようにして欲しいと設計変更が求められました。ここでいうギアインチは「車輪の直径(リムの直径 + (タイヤの厚み × 2)) × ギアの比率」で算出することができます。よって以下のようにクラスを変更しました。
class Gear attr_reader :chainring, :cog, :rim, :tire def initialize(chainring, cog, rim, tire) @chainring = chainring @cog = cog @rim = rim @tire = tire end def ratio chainring / cog.to_f end def gear_inches ratio * (rim + (tire * 2)) end end
追加されたメソッドとしては以下のとおりです。
rim・・・リムの直径
tire・・・タイヤの厚み
gear_inches・・・ギアインチを求めるメソッド
Gear.new(52, 11, 26, 1.5).gear_inches # => 137.0909090909090
今現在クラスは正常に動作しています。特にバグらしいバグもないわけですが、今現在のクラスは果たして単一責任クラスなのでしょうか。それを見極める方法として2つの方法が説明されています。
クラス(メソッド)が単一責任かどうか見極める方法
①あたかもそれに知覚があると仮定し質問する
「Gearクラスさん、あなたの比率を教えてくれませんか?」→ ○
「Gearクラスさん、あなたのタイヤのサイズを教えてくれませんか?」→ × (⇒ 自転車のギアは本来タイヤのサイズを知りません)
② 一文でクラスを説明してみる
「Gearクラスはギアの比率を教える責任がある」 → ○
「Gearクラスはギアの比率を教える責任がある。それと、タイヤのサイズを教える責任がある。」→ × (⇒「それと」や「または」が含まれていれば、それは単一責任から外れている)
①、②の方法で変更後のギアクラスでは本来知ることがないタイヤのサイズを知っていることが明らかです。つまり、現在のギアクラスは単一の責任ではなく複数の責任を持っていることがわかります。
複数責任から単一責任へ
複数の責任があると言うことは、その責任を別のクラスに渡すことが必要になります。それが既存のクラスに渡すのか、それとも新しいクラスを作成するのかは場合によりますが、今回はGearくらすしかない状態ですので後者の新しいクラスを作成して責任を移譲する方法をとります。
まず、変更前のクラスを確認します。
class Gear attr_reader :chainring, :cog def initialize(chainring, cog) @chainring = chainring @cog = cog end def ratio chainring / cog.to_f end end
ここにはリムもタイヤの情報も書いてはいけません。複数の責任を負うことになるためです。しかし、ギアインチを求める機能はGearクラスには必要です。したがってリム及びタイヤは別クラスで定義し、Gearクラスでgear_inchesメソッドを定義します。
ではまず新しいクラスを定義します。新しいクラスにはリムとタイヤの情報があります。この情報がありそうなクラス名として正しそうなのはWheel(車輪)です。
class Wheel attr_reader :rim, :tire def initialize(rim) @rim = rim @tire = tire end end
そして、gear_inchesメソッドで「車輪の直径(リムの直径 + (タイヤの厚み × 2))」が必要となるので、それを求めるdiameterメソッドを定義します。
class Wheel attr_reader :rim, :tire def initialize(rim) @rim = rim @tire = tire end def diameter rim + (tire * 2) end end
そしてGearクラスにてgear_inchesメソッドを定義します。しかし、ここでGearクラスにはリムもタイアの情報もありません。どうするのかというと、WheelクラスのインスタンスであるwheelというメソッドをGearクラス内に定義します。
class Gear attr_reader :chainring, :cog, :wheel def initialize(chainring, cog) @chainring = chainring @cog = cog @wheel = wheel end def ratio chainring / cog.to_f end def gear_inches ratio * wheel.diameter end end
Gearクラスのインスタンスを作成する場合、Wheelクラスのインスタンスの作成も必須になるということです。
Gear.new(52, 11, Wheel.new(26, 1.5))
これにより二つのクラスが各々に単一の責任をもつ状態になりました。gear_inchesメソッドも正常に動作します。
Gear.new(52, 11, Wheel.new(26, 1.5)).gear_inches
なぜ単一責任が重要なのか
上記のように単一責任にしたことでなぜTRUE品質になるのでしょうか。それには以下の理由があります。
別のクラスとの依存性がわずかしかないため、単独で変更した時に他のクラスへの影響がほとんどないため
ここでこの本を読む上で重要な依存性という言葉が出てきます。依存性とはつまり、あるクラスがあるクラスのことを知っている状態です。例えば、上記のGearクラスはwheelありきでインスタンスが作成されるため、wheelとなるオブジェクトがあることを知っています。(Wheelクラス自体の存在は知りません。あくまでwheelとなるオブジェクトがあることだけを知っています。ここの理解は少し難しいです。。。)
反対にWheelクラスは他のクラスについて何も知らない状態です。つまり、依存性がまったくないのクラスになります。よって、GearクラスもWheelクラスも互いに依存性がほとんどない状態と言えるでしょう。
これはコードの変更に対する別クラスへの影響がほとんどないことにつながります。例えば、Wheelクラスに新しくhogeの情報を加えたとします。
class Wheel attr_reader :rim, :tire, :hoge def initialize(rim) @rim = rim @tire = tire @hoge = hoge end def diameter rim + (tire * 2) end end
しかし、この変更が起きたとしても既存のGearクラスに対してコードを変更する必要がありません。依存性がないことで、WheelクラスもGearクラスもコードを変更した時に互いに及ぼす影響がほとんどないのです。
単一責任はメソッドでも必要なことです。
単一の責任のメソッドからよく外れがちなのが繰り返し処理です。例えば、下記のメソッドを自分のポートフォリオで使用していた、「チャンネルの固有のIDと同じIDのチャンネルをレシーバーのチャンネル一覧から抽出する」メソッドです。
def get_same_id_channel(channels:, channel_id:) channel = channels.select { |channel| channel.dig("id") == channel_id }[0] channel end
一見して説明は「そして」などはないですが、メソッドの中身を見ると、「繰り返し処理で各々のチャンネルのIDをdigメソッドで取り出す。そして、指定したIDのチャンネルと同じIDのチャンネルをレシーバーのチャンネル一覧から抽出する」処理をしています。よって上記の繰り返し処理は以下のように変更できます。
def get_same_id_channel(channels:, channel_id:) channel = channels.select { |channel| channel_id(channel) == channel_id }[0] channel end def channel_id(channel) channel.dig('id') end
チャンネルIDを取り出す処理は別メソッドに置き換えることで責任を単一にすることができました。
【Railsデザインパターン①】Decorator
綺麗なコードを書きたい!!!
こんにちは、大ちゃんの駆け出し技術ブログです。
みなさん、綺麗なコード書きたくないですか??
最近自分はポートフォリオをリリースしまして、リリース後のユーザーの反応から機能などを追加しているのですが、まあコードがぐちゃぐちゃしていて追加が難しい。「これなんのためのコードだっけ?」って思うことは何度もあります。
でも、ふと思いました。
「綺麗なコードってどんなコード?」
自分がコーディングをするたびこれはどこに記述するのがベストなのだろうと考えようとはするのですが、最適解がわからず現場で学んでいくしかないのかなと感じていました。そんなとき、下記の記事を見つけました。
Railsのデザインパターンとは
Railsのデザインパターン。これはどんなことを指しているのでしょうか。
Railsにおけるデザインパターンとは、モデルやコントローラ、ビューに頻出する実装パターンを、オブジェクト設計の原則にもとづいて抽象化したパターンのことです。
ここで出てくるキーワードとして「オブジェクト設計の原則」というものがあります。この言葉の意味はざっくりまとめると下記のようになります。
1つのクラスに1つの役割
https://www.amazon.co.jp/オブジェクト指向設計実践ガイド-Rubyでわかる-進化しつづける柔軟なアプリケーションの育て方-Sandi-Metz/dp/477418361X
つまり、Railsのデザインパターンとは、1つのクラスに1つの役割という設計を保つことをRailsのコーディングで実践する方法ということになります。
何故このようなデザインパターンがあるのか。
デザインパターンは、アプリケーションが大きくなるにしたがって起こりがちな設計上の問題を防ぐために必要になります。 代表的な問題がFat ModelやFat Controller、Fat Viewです。Railsはデフォルトでモデルやコントローラ、ビューを用意しています。用意されたこのファイル群だけにコードを記述していくと、オブジェクト指向設計の原則を守るのは難しいです。つまりコードが肥大化してしまいます。 こうなると拡張性や再利用性がなく、またテストも書きづらくなります。これを防ぐために、オブジェクト指向設計の原則に基づいてクラスを分割していく必要があります。
https://applis.io/posts/rails-design-patterns#railsにおけるデザインパターンとは
自分の場合、Fat Controllerが目立ちます。そのため、コードを拡張する時に何度も同じコードを書いている時がたびたびあって、その度に拡張子づらいと思うのです。Railsのデザインパターンとはざっくりまとめると
「Railsで綺麗なコードを書く頻出の方法」
ということができるでしょう。
今回からいくつかの記事にまたがってRailsの全てのデザインパターンをまとめていきたいと思います。デザインパターンは全部で9つあるそうですが、1つずつ紹介していきます
Decoratorオブジェクト
Decoratorオブジェクトの責務
モデルに対するビューのロジックをカプセル化する
Railsではビュー側で表示する見た目・内容を変更したい場合があります。例えば、以下のように日時を表示するviewファイルがあるとします。start_datetimeはdate型のカラムです。
<p> <%= event.start_datetime %><br><br> </p> 表示:2021-09-09 15:00:00 UTC
お分かりのように非常に表示が見づらい。これを日本標準時でYYYY/MM/DD hh:mmの形式で表示する場合、以下のようになります。
<p> <%= event.start_datetime.strftime('%Y/%m/%d %H:%M') %><br><br> </p> 表示:2021/09/09 15:00
しかし、ビュー側にロジックを書くのはよろしくないとされているため、これをモデルに記述します。
# event.rb class Event < ApplicationRecord def formatted_time start_datetime.strftime('%Y/%m/%d %H:%M') end end
<p> <%= event.formatted_time %><br><br> </p> 表示:2021/09/09 15:00
ここでの問題は、viewに表示したいメソッドを追加したけれど、モデルに書くと肥大化してしまうことです。モデルでのメソッドはビューだけでなくコントローラーで使われるメソッドも多く含まれる場合があります。全てのロジックをモデルに移すとFat Modelというモデルにたくさんのコードが書かれてしまう問題が出てきてしまいます。オブジェクト設計の原則である変更しやすいコードから外れてしまいます。
そこで登場するのがDecoratorオブジェクトです。ビューで表示するロジックはモデルではなくDecoratorオブジェクトのファイルに記述する(ロジックのカプセル化)というデザインパターンです。
Decoratorオブジェクトをサポートするgemとして2つのgemがあるそうです。
見たところどちらもメンテナンスは最近されています。しかし、draperの方がスター数が5000に対して、active_decoratorは950程度とかなり差があるため、今回はdraperを使うこととします。
draper
導入
① インストール
Gemfileに記述してインストール
# Gemfile gem 'draper'
$ bundle install
② コマンドのアクティベーション
rails generate draper:installというコマンドを打つことで次に使用するコマンドを使えるようにします。app/decorators/application_decorator.rbというファイルが作成されます。
$ bundle exec rails generate draper:install Running via Spring preloader in process 50409 create app/decorators/application_decorator.rb
作成されたファイルは以下のようになります。推測できる通り、ApplicationControllerのように他のdecoratorファイルと共通する処理を書くためのファイルです。今回は使用しません。
# app/decorators/application_decorator.rb class ApplicationDecorator < Draper::Decorator # Define methods for all decorated objects. # Helpers are accessed through `helpers` (aka `h`). For example: # # def percent_amount # h.number_to_percentage object.amount, precision: 2 # end end
③ モデル用のdecorator.rbを生成します。
②で下記コマンドが使えるようになりました。
$ rails generate decorator モデル名
今回はeventモデルを装飾したいため、eventモデルを指定してdecoratorファイルを生成します。
$ bundle exec rails generate decorator event Running via Spring preloader in process 56951 create app/decorators/event_decorator.rb
生成されたファイルは下記になります。
# app/decorators/event_decorator.rb class EventDecorator < Draper::Decorator delegate_all # Define presentation-specific methods here. Helpers are accessed through # `helpers` (aka `h`). You can override attributes, for example: # # def created_at # helpers.content_tag :span, class: 'time' do # object.created_at.strftime("%a %m/%d/%y") # end # end end
ここでdelegate_allという記述がありますが、これは元のモデルファイルに書かれているロジックがdecoratorファイルでも使用できるようにしています。例えば、先ほど記述したformatted_timeメソッドがモデルファイルevent.rbに記述されていれば、event_decorator.rbでもformatted_timeメソッドが利用できるようになります。ここで新しく同様のメソッドを書く必要がなくなるので、DRYに則っていますね。
④ decoratorファイルにロジックを記述
# app/decorators/event_decorator.rb class EventDecorator < Draper::Decorator delegate_all def formatted_time object.start_datetime.strftime('%Y/%m/%d %H:%M') end end
ここでいうobjectはモデル自身です。デコレートしているモデルを参照するメソッドと理解しておきます。
ビュー側ではdecorateと明示して以下のように記載します。
<p> <%= event.decorate.formatted_time %><br><br> </p> 表示:2021/09/09 15:00
helperとの違い
ここでhelperメソッドというこれまたビューを装飾するためのファイルがあると思います。これを使えばロジックをビューやモデルに書くことなく、helperに書くことで同様の実装が可能になると思います。
しかし、helperとdecoratorの用途は差別化されています。
helperはモデルから独立し直接関係していない描画ロジックを実装するのに用います。それに対してDecoratorは特定のモデルにがっつり関連した描画ロジックを実装するのに用いるというものです。
今回の場合、eventモデルのstart_datetimeというカラムをガッツリ参照しています。そのため、decoratorを使用することが正しそうです。
反対に、helperには何を書くのかというと、eventに関する関連ページでeventモデルを参照しない描画ロジックを記述すると思います。例えば、event一覧ページがあるとして、そのページに「本日(YYYY/MM/DD)のイベント」と表示させる時に使えます。
# app/helpers/events_helper.rb module EventsHelper def event_at_date Date.today.to_time.strftime('%Y/%m/%d') end end
参考記事
オブジェクト指向設計原則とは
decoratorを導入して、viewの記述をすっきりさせ、modelの肥大化を回避する【Day 3/30 2nd】
Decoratorの役割とDraperについて