【無職に転生 ~ 就職するまで本気出す①】【SQL】句の実行順序
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで本気出す】というチャレンジをします!!!!今月から2クール目が始まる大人気アニメのタイトルのまるパクリチャレンジです。これは単純にRailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。それだけではなくて実は昨日退職して文字通り無職に転生しましてプロニートになり毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!今日から就職が終わるまで頑張ります!ちなみに投稿する内容はまばらです。ただ、自分の知識不足がある領域になるかと思います(未経験なので全部たりませんが)。具体的には下記のとおり。
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
また技術だけでなくビジネス書についても書いていきたいと思っています。理由としてはこれから転職する上でスタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるために技術以外の視点も養っていきたいからです。なのでそれも含めて内定出るまで本気を出して投稿し続けます!
本日はSQLのSELECT文における「〜句」の実行順序について紹介します。
句の実行順序を把握する理由
説明の前ですが「なぜ実行順序を把握しなければならないのでしょうか」という疑問を持った方もいるかと思いますので、なぜやるかを説明します。
それは実行順序を理解することで取得データがどのようなフローを辿って加工され抽出されたのかがわかるからです。
例えば、単純なデータの取得文の場合取得データの順番を意識せずともどうしてそのデータが取得されrかわかると思います。下記はテーブルのデータ全権を取得している処理です。
SELECT * FROM テーブル名
ですが、下記の文章はどうでしょう?
SELECT DATE_FORMAT(post_date, '%Y%m') AS yyyymm ,post_type AS post_or_page ,COUNT(ID) AS cnt FROM posts WHERE (post_type = 'post' OR post_type = 'page') AND post_status = 'publish' AND post_date BETWEEN '20190101' AND '20191231' GROUP BY DATE_FORMAT(post_date, '%Y%m') ,post_type HAVING COUNT(ID) > 1 ORDER BY yyyymm ,post_or_page
どのようなデータが取得されるかが見てすぐにはわからないですよね。ですのでSQL文を読んでいくと思うのですが、どこから見ていけばいいかわかりますか?SELECTから?FROMから?最も効率の良いやり方は実行順序順に辿っていくことではないでしょうか。そうすればデータが取得されるフローを追っていくことができ、どのようなデータが取得されるのかを判断できると思います。なので理解しておいて損はないはず!
ざっくりと句の種類
SELECTで使用する主な句についてはざっくりと以下のとおり。あまり深くは説明しません。
- SELECT
データ取得のための句。どの列を取得するのかを指定します。ほんとによく使います。
SELECT ID, 注文日
- FROM
どのテーブルからデータを取得するのかを指定する句。これがなければ動きません。
SELECT ID, 注文日 FROM 注文
- WHERE
テーブルの中のどのデータを取得するかを指定します。例えば、IDが100231のデータを取得するのであれば以下のように記述。
SELECT ID, 注文日 FROM 注文 WHERE ID = 100231
- JOIN (LEFT JOIN, RIGHT JOIN, FULL JOIN)
2つのテーブルを関連カラムを通して結合する句。これによって複数のテーブルを加工してデータを取得できます。多分初学者が滅茶苦茶つまづく。
SELECT ID, 商品.商品名 FROM 注文 JOIN 商品 ON 商品ID = 商品.商品ID
- ORDER BY
順序をソートできる句。単体だとあまり意味がない。LIMIT句と一緒に使われるケースが多そう。
SELECT ID, 注文日 FROM 注文 ORDER 注文日 DESC
- LIMIT句とOFFSET句
・LIMIT・・・取得したデータを何行取得するかを指定する句。
・OFFSET・・・LIMITをどこから始めるかを指定する句。OFFSETを指定しなければLIMITは一番上の行から取得してしまうが、OFFSETを使うことで上から何行レコードを飛ばすかを指定する。
ちなみにデータベースによってはLIMITとOFFSETは書き方が異なる。
SELECT ID, 注文日 FROM 注文 ORDER 注文日 DESC LIMIT 2 OFFSET 2 // 3行目から2行取得する
- GROUP BY
同じ値を持つデータごとにグループ化する句。例えば、動物のテーブルがあるとして動物の種類ごとにデータを集計したい場合に使われます。
ここで集計という言葉が出ましたが、基本的にGROUP BYは集計関数と言われる、SQLでテーブルの列の合計や平均、行数など指定した列を様々な値にして集計する関数と併用されます。集計関数は5種類あります。
・SUM・・・列の合計を計算する
・AVG・・・列の平均を計算する
・COUNT・・・レコードの数を計算する
・MAX・・・列の最大値を計算する
・MIN・・・列の最小値を計算する
例えば、SUMを使って下記テーブルから値段(price)の合計を取得するとします。
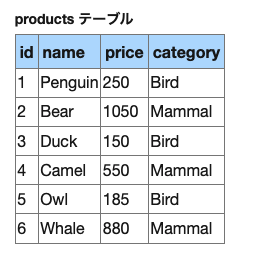
レコードの値の合計を求める (sum集計関数の利用) - SQLの構文
SELECT AVG(price) AS 平均価格 FROM Products
集計関数の特徴としてデータが1レコードになってしまうという特徴があります。これをGROUP BYを使うことで、ある種類ごとの合計金額や平均価格を求めることができます。例えばcategoryごとの平均価格を取得するには以下のクエリを発行します。
SELECT category AS カテゴリー, AVG(price) AS 平均価格 FROM Products GROUP BY category
- HAVING
HAVINGはGROUP BYの処理と併用されます。例えば、上述した処理で各動物ごとの平均価格を求めましたが、平均価格が500円以下のものは出力しないという条件を追加するとします。その時にWHEREを使うかと思いきやそうではなくHAVINGで制約する必要があります。理由としては後述しますが、この記事の主題である実行順の影響です。
SELECT category AS カテゴリー, AVG(price) AS 平均価格 FROM Products GROUP BY category HAVING AVG(price) >= 500
他にもいくつか句はありますがここまでにしておきます。
実行順序
ようやく実行順序について説明できます。結論から先に言うと以下のような順序で実行されます。
FROM/JOIN ↓ WHERE ↓ GROUP BY ↓ HAVING ↓ SELECT ↓ ORDER BY ↓ LIMIT/OFFSET
① FROM/JOIN
最初はFROMとJOINです。SQLを書く順番からFROMが1番最初に実行され、その次にJOINが実行されます。この2つの句によりどこからデータを抽出するかを決めることができます。つまり、データの加工前の合計作業セットを決定します。
FROM
第12回 データベースを作る(テーブル作成) | shell-mag
JOIN
② WHERE
JOINとFROMでデータ一式は揃いましたが、これら2つの句は細かい指定をすることができずテーブル全体を揃えます。テーブルの中のある特定のデータのみを使いたい場合にWHEREでそのデータを抽出します。データ一式から不要なデータを取り除くためにWHEREが実行されます。
【SQL入門】WHEREで検索条件の指定方法をわかりやすく解説 | 侍エンジニアブログ
③ GROUP BY
WHEREで必要なデータを抽出したらそれらのデータをGROUP BYでグループ分けします。これにより、あたかもグループの種類ごとにテーブルを作ることができます。
繰り返しですが、GROUP BYはクエリに集計関数がある場合にのみ使用する必要があるため、集計関数を使用しないのであればここはスキップされます。

グラフ-Azure Databricks - SQL Analytics
④ HAVING
ここまでで取得したいデータはできているのですが、GROUP BYでデータをまとめた結果、不要なデータが出てくるかもしれません。そのため、集計関数実行後にWHEREのように制約をするためにHAVINGをここで実行します。
ここがWHEREが集計関数を使った後の制約に実行できない理由です。実行順序がGROUP BYより先にあるWHEREは、それよりも後に実行されるGROUP BYの処理の結果に対して制約することができません。そのためHAVINGが利用されます。
- WHERE・・・FROM/JOINで揃えたデータから不要なデータを制約
- HAVING・・・集計関数実行後の不要なデータを制約
⑤ SELECT
ここまでで加工されたデータをSELECTで取得します。SELECTはデータを取得するのみですのでHAVINGまでに実行されたデータが取得データです。
⑥ ORDER BY
SELECTで取得したデータを並び替えします。

⑦ LIMIT/OFFSET
最後に並び替えたデータのどの行を取得するのかを指定します。並び替えることでさらに取得したいデータに加工を施すことができます。
終わりに
説明は所々手抜きかもしれませんが、一応一通り説明しました。実行順は調べれば確かに出ますが、SQLを書く時や読む時にいちいち調べていたら時間がもったいないです。また、SQLを読む速さも上がると思うので覚えておいて損はないです!以上!明日も本気出します!