【無職に転生 ~ 就職するまで毎日ブログ出す_13】【Ruby】Enumerable
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。

RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
本日はEnumerableについて解説します。Arrayクラスや昨日までのHashクラスの勉強をした時に以下のように継承しているメソッド欄に常にEnumerableがありました。

気になったので調べてたのでここに記載しておきます。なお、調べる量がほとんどなかったので今回の記事はかなり短くなると思います。
Enumerableとは
Enumerableとは一体何なのか?その回答が公式のRubyリファレンスマニュアルに載っていたので引用します。
繰り返しを行なうクラスのための Mix-in。このモジュールのメソッドは全て each を用いて定義されているので、インクルードするクラスには each が定義されていなければなりません。 Array, Hash, Range, Enumerator等のクラスで、 Enumerableモジュールはインクルードされています。ただし、効率化のため、そのクラスでEnumerableと同名・同等の機能を再定義(オーバーライド)しているケースも少なくなく、特にArrayクラスでは同名のメソッドを再定義していることが多いです。
"繰り返しを行なうクラスのための Mix-in(ミックスイン)"とあります。ミックスインとはクラスにincludeモジュール名(or extend モジュール名)でモジュールにあるメソッドを取り込むことを指します。例えば、以下のようにモジュールが定義されていれば、
module Hoge def foo p 'foo' end end
下記のようにミック心の記述を書くことでモジュールに定義されているメソッドが使用できます。
class Animal include Hoge end animal = Animal.new animal.foo # => 'foo'
つまり、Enumerableとはモジュールのことだったのです。そしてArray, Hash, Range, Enumerator等のクラスにミックスインされているということですね。
Enumerableモジュールで定義されているメソッドは以下のようになります。

そしてこれらはすべてeachメソッドを用いて定義されているらしいです。eachメソッド自体はEnumerableモジュールで定義されていないので、ミックスインするクラスには必ずeachメソッドが定義されている必要があります。eachメソッドが定義されているクラスとしてArray, Hash, Range, Enumeratorのクラスは該当するということです。
また、Enumerableモジュールで定義されているメソッドがミックスインされるクラスにも定義されていることがあるらしいですね。引用元ではArrayクラスで定義されているメソッドが重複していることが多いそうです。リファレンスを参照すると確かに多くの同名メソッドが定義されていました。
まだ確証はありませんが、オーバーライドされないEnumerableモジュールのメソッドはおそらくArrayクラスと重複していないメソッドになるでしょう。

これらを把握すれば大体Enumerbleモジュールのメソッドは覚えられているのかなと思います。
Rangeクラス、Enumeratorクラス
上述したことでEnumerableの説明は終わりです。流石にこれだけだとあまりにも短いと思ったので、EnumeratorがミックスインされるクラスとしてArrayとHashはわかるのですが、RangeとEnumeratorについてはあまりピンとこなかったので確認しておきます。
Rangeクラス
範囲オブジェクトのクラス。範囲オブジェクトは文字どおり何らかの意味での範囲を表します。数の範囲はもちろん、日付の範囲や、「"a" から "z" まで」といった文字列の範囲を表すこともできます。
この範囲オブジェクトのクラスについてはよく使うことも多いかなと思います。
(1..3) => 1..3
これは普段何気なく使っていましたがRangeクラスというオブジェクトのインスタンスなんですね。classメソッドでクラスが確認できます。
(1..3).class => Range
この範囲オブジェクトはRangeクラスを用いでインスタンス化もできます。
Range.new(1, 5) => 1..5
基本的には繰り返し処理などで使われるケースが多そうです。
Range.new(1, 5).each {|n| puts n} # 出力 1 2 3 4 5
Rangeクラスについてはかなり内容が濃いので別の記事でまたアウトプットしたいです。
Enumeratorクラス
each 以外のメソッドにも Enumerable の機能を提供するためのラッパークラスです。また、外部イテレータとしても使えます。 (中略) Enumerator を生成するには Enumerator.newあるいは Object#to_enum, Object#enum_for を利用します。また、一部のイテレータはブロックを渡さずに呼び出すと繰り返しを実行する代わりに enumerator を生成して返します。
このクラスについてはあまりよくわからなかったのですが下のような使い方をするそうです。下記のような使い方が外部イテレーターと言います。
authors = Enumerator.new do |y| y << '村上春樹' y << '吉本ばなな' y << '小川洋子' end authors.next => "村上春樹" authors.next => "吉本ばなな" authors.next => "小川洋子
Ruby の Enumerator とたわむれる | Engineers' Blog
終わりに
この間JQueryの記事を書くと言ったのですが今日はこの記事の内容にしました。 今回だいぶ内容が薄くてすみません💦 次の記事ではJQueryについて書こうと思います。
【無職に転生 ~ 就職するまで毎日ブログ出す_12】【Ruby】ハッシュの使い方②
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
本日もハッシュについて復習していきます。昨日もハッシュについて学びましたがさらに深めるべく復習していきます。
【無職に転生 ~ 就職するまで毎日ブログ出す_11】【Ruby】ハッシュの使い方 - 大ちゃんの駆け出し技術ブログ
いつも大変お世話になっているチェリー本の第5章にかなり具体的に書かれているので、それを参考にしつつ他の記事も引用して開発できたらなと思います。
プロを目指す人のためのRuby入門 言語仕様からテスト駆動開発・デバッグ技法まで (Software Design plusシリーズ)
追加でハッシュのメソッド
昨日は少しだけ紹介できなかったので再度使えそうなメソッドを紹介していきます。再掲しますがハッシュのメソッドは非常に多いです。ですが、多くの挙動はArrayと同じですので、覚えてしまえばどちらにも使えてしまうので一石二鳥です!

fetch
キーを指定してそれに対応するバリューを取得します。
hash = {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}
hash.fetch(:ruby)
=> :rails
digメソッド に続きまた取得のメソッドですね。digメソッドと違う点として、キーが見つからない場合にエラーになります。
hash.fetch(:java) # KeyError (key not found: :java)
KeyErrorと指定したキーが見つからないというエラーになります。これでは本来の【ハッシュ[キー]】との差別化があまりないように見えますが、実はfetchメソッドは第二引数を指定することができます。この第二引数はKeyErrorが起こった場合、つまり指定したキーが見つからなかった場合、第二引数で指定した値が返り値として返却されます。つまりKeyErrorを回避することができます。
hash.fetch(:ruby, "KeyErrorを回避") => :rails hash.fetch(:java, "KeyErrorを回避") => "KeyErrorを回避"
階層が深いキーに対しては使うことができないようです。なぜなら引数が二つまでしか定義できないためです。第二引数はかならずKeyErrorが起きたときの返り値となるため、階層が深いキーの取得にはあまり向かないかなと思います。
fetch(key, default = nil)
hash = {frameworks: {ruby: :rails, python: :Django, JS: :Vuejs}}
=> {:frameworks=>{:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}}
hash.fetch(:frameworks,:ruby)
=> {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}
merge
レシーバーと引数のハッシュを結合させて新しいハッシュを返します。
another_hash = {java: :Spring_Framework}
=> {:java=>:Spring_Framework}
hash.merge(another_hash)
=> {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs, :java=>:Spring_Framework}
これはハッシュの追加、更新とほとんど同様の挙動ですが、引数のハッシュによって更新と追加を同時に行えます。というのもメソッドの挙動としてはレシーバーであるハッシュに対して引数にレシーバーにはない新しいキーがあればそれを追加し、レシーバーに既にある既存のキーがー引数で渡されればそれを更新します。
another_hash = {java: :Spring_Framework, JS: :React}
=> {:java=>:Spring_Framework, :JS=>:React}
hash.merge(another_hash)
=> {:ruby=>:rails, :python=>:Django, :JS=>:React, :java=>:Spring_Framework}
上記では既にキーがある:JSと同じキーば引数にも含まれており、そのバリューは違う値である:Reactです。よってもとのレシーバーの:Vuejsが更新され:Reactに変わっています。
mergeメソッドはrailsではよくストロングパラメータの定義箇所で使われています。
params.require(:モデル名).permit(:キー名, :キー名,・・・).merge(user_id: current_user.id)
invert
invertメソッドはキーと値を入れ替えたハッシュを返します。
hash = {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}
hash.invert
=> {:rails=>:ruby, :Django=>:python, :Vuejs=>:JS}
ハッシュの中身を大きく操作するメソッドなので使い所は分かりませんが、便利なメソッドであることは間違い無いです。ちなみに下記のようにバリューが同じハッシュがある場合、最後の要素の組み合わせが返却されます。
hash = {ruby: :rails, python: :Django, JS: :Vuejs, Javascript: :Vuejs}
=> {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs, :Javascript=>:Vuejs}
hash.invert
=> {:rails=>:ruby, :Django=>:python, :Vuejs=>:Javascript}
元のハッシュより短くなってしまいますが同じキーは二つ存在することはできないためです。よって最後に評価される1番後ろの組み合わせだけが残ります。
transform_keys
すべてのキーに対してブロックを呼び出した結果で置き換えたハッシュを返します。値は変化しません。
Hash#transform_keys (Ruby 3.0.0 リファレンスマニュアル)
キーに対して評価しそれを反映させた新しいハッシュを返します。
hash.transform_keys {|k| k.upcase}
=> {:RUBY=>:rails, :PYTHON=>:Django, :JS=>:Vuejs, :JAVASCRIPT=>:Vuejs}
transform_values
すべての値に対してブロックを呼び出した結果で置き換えたハッシュを返します。キーは変化しません。
Hash#transform_values (Ruby 3.0.0 リファレンスマニュアル)
transform_keysとは逆のことをします。
hash.transform_values {|v| v.upcase}
=> {:ruby=>:RAILS, :python=>:DJANGO, :JS=>:VUEJS, :Javascript=>:VUEJS}
ハッシュ < = > 配列
ハッシュから配列に変換する方法、その逆である配列からハッシュに変換する方法は簡単です。to_aとto_hメソッドを使います。
hash.to_a => [[:ruby, :rails], [:python, :Django], [:JS, :Vuejs], [:Javascript, :Vuejs]] hash.to_a.to_h => {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs, :Javascript=>:Vuejs}
ただし、ハッシュから配列にした時にきれいな配列として返るわけではなく階層の配列として返却されています。そのため、Arrayクラスのメソッドであるflattenメソッドも同時に使うパターンもありそうです。
hash.to_a.flatten => [:ruby, :rails, :python, :Django, :JS, :Vuejs, :Javascript, :Vuejs]
終わりに
次の記事ではJQueryについて書こうと思います。JQueryを全然勉強したことがなくて今チーム開発で使っていて全く読めずめちゃくちゃ困っています。
参考記事
【無職に転生 ~ 就職するまで毎日ブログ出す_11】【Ruby】ハッシュの使い方
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
本日はハッシュについて復習していきます。普段Railsを学習している時に何かと出てくるハッシュですが、特に自分から進んで使おうとしなかったので、いざ自分から使おうとなるとあまり記述が浮かんでこなかったので、この記事でしっかり復習できればと思います。
いつも大変お世話になっているチェリー本の第5章にかなり具体的に書かれているので、それを参考にしつつ他の記事も引用して開発できたらなと思います。
プロを目指す人のためのRuby入門 言語仕様からテスト駆動開発・デバッグ技法まで (Software Design plusシリーズ)
ハッシュとは
そもそもハッシュとは一言でなんぞやと思いましたので、伊藤さんの言葉を使って説明します。
ハッシュはキーと値の組み合わせでデータを管理するオブジェクトのことです。他の言語では連想配列やディクショナリ(辞書)、マップと呼ばれたりしています。
例えば、以下のような記述はハッシュです。
{"ruby" => "rails","python" => "Django", "JS" => "Vue.js" }
rubyはキーで値はrailsとあるように言語とそのフレームワークをデータとして管理しています。
ちなみにRailsでよく使うケースはparamsから値を取得する時です。
@user = User.find(params[:id])
要素の追加、変更、取得、削除
ハッシュは配列と同じようにデータを管理するオブジェクトなので、追加・変更・取得・削除などが可能です。
追加
まず取得ですが、例えば上述したハッシュにPHPとそのフレームワークのLaravelをハッシュに加えるとします。ハッシュを句追加する構文は【ハッシュ[キー] = バリュー】となります。
hash = {"ruby" => "rails","python" => "Django", "JS" => "Vue.js" }
hash['php'] = "Laravel" # ハッシュ[キー] = バリュー
hash
# => {"ruby"=>"rails", "python"=>"Django", "JS"=>"Vue.js", "php"=>"Laravel"}
1番最後の要素にphpとLaravelのデータが格納されました。
変更
次に変更ですがこれは追加の時と記述は同じです。ここでいう変更はバリューの変更になるので、既に格納されているキーを指定して、その対応するバリューの値が既存のバリューとは別の値を格納することで変更できます。例えば、JSのフレームワークをReactに変更する場合は下記のような記述になります。
hash = {"ruby" => "rails","python" => "Django", "JS" => "Vue.js" }
hash['JS'] = "React"
hash
# => {"ruby"=>"rails", "python"=>"Django", "JS"=>"React"}
取得
要素の取得、つまりバリューの取得は対応するキーをハッシュにつけることで取り出すことができます。構文としては【ハッシュ[キー]】でOKです。
hash["JS"] # => "React"
ちなみに指定したキーが見つからない場合はnilが返却されます。
hash["Java"] # => nil
削除
削除の場合はdeleteメソッドを使用します。このメソッドはHashクラスのメソッドで、引数にキーを指定することで、そのキーと対となるバリューの組み合わせをオブジェクトの要素から削除します。
hash = {"ruby" => "rails","python" => "Django", "JS" => "Vue.js" }
hash.delete("JS")
hash
# => {"ruby"=>"rails", "python"=>"Django"}
Hash#delete (Ruby 3.0.0 リファレンスマニュアル)
シンボル
ここでシンボルについても復習。普段Railsで何気なく使っているためあまり理解せずに使っていました。💦ちなみにRailsではどこで使われているのかというと、コールバックとかで使われていますね。:set_userがシンボルです。
before_action :set_user private def set_user @user = User.find(params[:id]) end
シンボルを表すクラス。シンボルは任意の文字列と一対一に対応するオブジェクトです。 文字列の代わりに用いることもできますが、必ずしも文字列と同じ振る舞いをするわけではありません。同じ内容のシンボルはかならず同一のオブジェクトです。
シンボルは先頭にコロンをつけて任意の文字をセットします。
:apple :japan :ruby_is_fun
シンボルと文字列の違い
シンボルと文字列は以下の4点で異なるようです。
① オブジェクトのクラスが違う
classメソッドで出力するとSymbolクラスが確認できます。
:ruby.class => Symbol "ruby".class => String
② 整数として管理される
チェリー本では以下のように書かれています。
シンボルはRubyの内部で整数として管理されます。表面的には文字列と同じように見えますが、その中身は整数なのです。
整数として管理されるため処理が文字列よりも高速になることがあります。
:ruby == :ruby # シンボルの方が早い "ruby" == "ruby"
③ 同じシンボルであれば同じオブジェクト
シンボルは形が同じであればそれは全て同一のオブジェクトとして扱われます。object_idメソッドを使えばわかるのですが、同一名のシンボルは全て同じオブジェクトであることがわかりますが、文字列の場合は全て異なります。
:ruby.object_id => 707228 :ruby.object_id => 707228 :ruby.object_id => 707228 "ruby".object_id => 280 "ruby".object_id => 300 "ruby".object_id => 320 "ruby".object_id => 340 "ruby".object_id => 360
Object#object_id (Ruby 3.0.0 リファレンスマニュアル)
よって同一名の文字列が大量に使われればそれだけメモリが奪われますが、シンボルの場合同じ名前を使ってもメモリは奪われません。
④ イミュータブル
シンボルは破壊的メソッドでは変更できないイミュータブルなオブジェクトです。
"ruby".upcase! => "RUBY" :ruby.upcase! (irb):36:in `<main>': undefined method `upcase!' for :ruby:Symbol (NoMethodError)
upcase!メソッドは破壊的メソッド でレシーバーの元の値も変更してしまいますが、シンボルは破壊的メソッドが定義されていないようですので、undefined method (定義されていない)エラーが返ってきます。
ちなみにupcaseメソッドはシンボルでも使えます。
:ruby.upcase => :RUBY
大文字のシンボルと小文字のシンボルを比較すると別のオブジェクトであることがわかります。
ruby.upcase.object_id => 701988 :ruby.object_id => 707228
ハッシュにシンボルを使う
シンボルを紹介したことで再びハッシュ。シンボルはハッシュによく使われるらしいです。ハッシュのキーをシンボルにして、文字列で定義するよりも高速に処理をすることが可能になります。
hash = {:ruby => "rails",:python => "Django", :JS => "Vue.js" }
hash[:ruby]
# => "rails"
ここでさらに【シンボル: 値】という形に直すことができます。 =>とは別の書き方ですね。返り値を見ると上述したものと見た目は変わっていないことから、同じハッシュが定義できていることがわかります。
hash = {ruby: "rails",python: "Django", JS: "Vue.js" }
=> {:ruby=>"rails", :python=>"Django", :JS=>"Vue.js"}
さらにバリューの方にもシンボルを使うことができるので【シンボル: :シンボル】という形でキーバリューを設定できます。
{ruby: :rails, python: :Django, JS: :Vuejs} # シンボルはコロンが挟めないのでここではVue.jsとは書けません。
=> {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}
ちなみにこのシンボルシンボルの見た目で思い出したのは下記のような記述ですね。
has_many :likes, dependent: :destroy
destroyやdependentは文字列として新しくメモリを消費する必要はないのでこのように書かれているのかなと思いました。
ハッシュのメソッド
ここではハッシュクラスで定義されているメソッドを紹介します。ハッシュはArrayと比べて利用頻度低いしそこまで使わないと考えていましたが、調べてみるとたくさんありました。
全部は紹介しきれないので使えそうなメソッドをいくつかピックアップしました。
keys
レシーバーのハッシュのキーを配列として返します。
{ruby: :rails, python: :Django, JS: :Vuejs}.keys
=> [:ruby, :python, :JS]
values
上記のkeysとは違いバリューの配列を返します。
{ruby: :rails, python: :Django, JS: :Vuejs}.values
=> [:rails, :Django, :Vuejs]
has_key?
引数のキーがハッシュの中に含まれているかをどうか確認するメソッドです。真偽値が返ってきます。
{ruby: :rails, python: :Django, JS: :Vuejs}.has_key? :python
=> true
{ruby: :rails, python: :Django, JS: :Vuejs}.has_key? :java
=> false
dig
digメソッドは実際によく自分も使いました。これはキーを引数で指定してハッシュを取得するメソッドです。
{ruby: :rails, python: :Django, JS: :Vuejs}.dig(:ruby)
=> :rails
上記の挙動を見ると上述したバリューの取得と挙動が同じではないかと思うかもしれません。
{ruby: :rails, python: :Django, JS: :Vuejs}[:ruby]
=> :rails
しかし、digメソッドはハッシュが二次元になればなるほど便利です。二次元配列とあるようにハッシュにも階層を作ることができます。
hash = {frameworks: {ruby: :rails, python: :Django, JS: :Vuejs}}
=> {:frameworks=>{:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}}
hash[:frameworks]
=> {:ruby=>:rails, :python=>:Django, :JS=>:Vuejs}
hash[:frameworks][:ruby]
=> :rails
hash[:frameworks][:java]
=> nil
ここで深い階層の値を取り出す時にもしframeworksが誤記載をしてしまうとエラーが起きてしまいます。frameworkとsを外してみます。
hash[:framework][:java] # undefined method `[]' for nil:NilClass (NoMethodError)
これはhash[:framework]でnilが返却され、nilをレシーバーに[:java]が実行されているためです。
それをdigでは回避することができます。
hash.dig(:framework, :java) => nil
先ほどとは違い名前が違うシンボルを引数に指定しても返却される値はnilになります。取得する時はこちらの方がエラーになることがなく便利です。ただ、 バグの温床にもなるので濫用は避けたいところです。
each/each_key/each__value
繰り返し処理でもハッシュは利用できます。ブロック内ではキーとバリューを同時に使用することができます。
hash = {frameworks: {ruby: :rails, python: :Django, JS: :Vuejs}}
hash.each {|k,v| puts k, v}
# 出力
ruby
rails
python
Django
JS
Vuejs
ちなみに変数を一つにすることもできます。その場合、変数の中身はキーとバリューの配列になります。
hash.each {|x| p x}
# 出力
[:ruby, :rails]
[:python, :Django]
[:JS, :Vuejs]
each_keyとeach__valueはレシーバーのハッシュのキーだけを繰り返し処理したい場合やバリューだけを使用したい場合に使います。
hash.each_key {|k| p k}
# 出力
:ruby
:python
:JS
hash.each_value {|v| p v}
# 出力
:rails
:Django
:Vuejs
終わりに
次の記事もハッシュを書きます。ではまた。
【無職に転生 ~ 就職するまで毎日ブログ出す_10】【Ruby】競技プログラミングで使えそうな記述
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日やること
昨日より競技プログラミングに取り組んでいます。railsを使っている時には使わないようなメソッドや記述がたくさん出てきたのでここらへんでまとめておきます。主に使えると思ったものは以下の6つです。自分はまだ初めて2日しか経っていないので完全始めた人向けに書きますので、競技プログラミング熟練者からしたら否定されそうですが何卒ご容赦の程よろしくお願いします。
- 複数入力
- each_with_index
- index/find_index
- transpose
- gsub
- ブロックの連番
複数の値を入力
gets.split
これはpaizaで頻出というかこれを使えないと多くの課題をクリアできません。頻出と言わず問題を解く上で必須です。なぜかというとpaizaや競技プログラミングでは一度の入力で二つの数を定義しなければいけない時があります。例えば、速度と重さの変数x, yがあるとすると、それらを入力する際には下記のように一度の入力で定義する必要があるのです。
x y
それを可能にするのがgets.splitです。getsメソッドは入力値をそのまま文字列として出力します。
gets 123 => "123\n" # 後ろに改行コードが含まれてしまうのでchompメソッドと併用されることが多い gets.chomp 123 => "123"
splitはレシーバーの文字列を分割して配列にして返します。引数を指定しなければスペース区切りで分割できます。
"abc def ghi".split => ["abc", "def", "ghi"]
上述した二つの組み合わせで二つの変数を一度に入力できます。
gets.split 10 20 # => ["10", "20"]
しかし、gets.splitでは文字列の値しか取得できません。上記のように数字を出力してもそれは文字列として扱われます。そこでmapメソッドを用いて数値の入力を可能にします。
gets.split.map(&:to_i) 10 20 # => [10, 20]
each_with_index
このメソッドすごく便利です。with_indexとあるように繰り返し処理時にインデックス番号もブロック内で使うことができるメソッドです。
%i(1 2 3).each_with_index do |n, idx| p n, idx end => 1, 0 => 2, 1 => 3, 2
利用機会としては、例えばXがある時にこのXと等しい要素は配列の何番目にあるかを出力する処理などで使えます。
array.each_with_index do |n, idx| puts idx + 1 if n == X end
eachだと要素しか処理に使うことができませんが、インデックス番号も処理で使えることで複雑な処理を可能にします。
index/find_index
レシーバーの要素の中に引数で指定した要素が含まれていれば、その要素のindex番号を返すメソッドです。find_indexはindexのエイリアスなのですが、find_indexの方が記述的に挙動が分かりやすいので自分はこちらを使用しています。
[1,2,3,4,5].find_index(4) # => 3
使うタイミングとしては、条件とマッチしたインデックス番号を出力したい時に配列に格納する方法をとりました。
index_arrays << arrays.index(array)
transpose
二次元配列を行列とみなして行と列を入れ替えるメソッドです。
ary = [[1, 2], [3, 4], [5, 6]] p ary.toranspose # => [[1,3,5], [2,4,6]]
競技プログラミングだと入力の順番が決められています。そして繰り返し同じ数のす値を入力して二次元配列に格納する処理も出てきます。例えばある処理をN回行うといった時に、下記のようにN回文のデータが必要な場合に二次元配列にして格納される処理があります。
N.times.map (gets.split.map(&:to_i))
数字a 数字b 数字c 数字d 数字e 数字f 数字g 数字h 数字i 数字j 数字k 数字l 数字m 数字n 数字o 数字p
しか上述した配列の順番を以下のように行と列を入れ替えたい場合もあると思います。
[[数字a, 数字e, 数字i, 数字m],[数字b, 数字f, 数字j, 数字n],・・・]
そんな時はtransposeメソッドを使えば行と列を入れ替えればOKです。transposeメソッドは行と列の中の要素数が一致しないとエラーを起こしますが、競技プログラミングでは繰り返し入力する時の数は決まっているので使えるタイミングはかなりありそうです。
N.times.map (gets.split.map(&:to_i)).transpose
gsub
文字列を置換する便利なメソッドです。
文字列パターンを第一引数で指定して、マッチしたものを置換する文字を第二引数で指定します。
p 'abcdefg'.gsub(/def/, '!!') # => "abc!!g" p 'abcabc'.gsub(/b/, '<<\&>>') # => "a<<b>>ca<<b>>c" p 'xxbbxbb'.gsub(/x+(b+)/, 'X<<\1>>') # => "X<<bb>>X<<bb>>" p '2.5'.gsub('.', ',') # => "2,5"
複数のパターンを指定することもできます。
下の文字は母音をすべて空文字に置換するコードです。
puts gets.chomp.gsub(/a|i|u|e|o|A|I|U|E|O|/, "") aaaaiiiooobbb # => "bbb"
ブロックの連番
これは知らなかったのですが、ブロックの中の引数を1、2、_3と連番にして取り出すことができるんです。
gets.split.map(&:to_i).then{puts _3, _2, _1} 1 2 3 3 2 1
これは伊藤淳一さんの記事でも出されていました。
サンプルコードでわかる!Ruby 2.7の主な新機能と変更点 Part 1 - 番号指定パラメータ(numbered parameter) - Qiita
本来であれば繰り返し処理はインデックス番号を昇順に処理が進んでいきます。よって、インデックス番号が大きい要素はかなり後にならないと処理が始まらないのです。そこで連番を設けることで早く処理に使いたい要素を連番で指定できます。
【無職に転生 ~ 就職するまで毎日ブログ出す⑨】【書籍】反応しない練習
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。

RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本日の内容
本日は現役の草薙龍瞬さんという現役の僧侶の方が書かれた「反応しない練習」と言う本をご紹介します。この本を一言で表すと、「誰もが抱えるモヤモヤをはらすための本」です。内容は仏教が軸になっていますが、合理的で実践的な内容になっているので、布教活動とは思わず読んで下さると嬉しいです。
満員電車 = イライラ?
まずこの本の主題である「反応」について説明していきます。この本では反応とは無駄な感情の動きと言及しています。少し言い過ぎかもしれませんが、無駄な反応が多すぎるというのが主張されています。無駄な反応の一例として満員電車が挙げられます。満員電車は非常にイライラすると思います。私も埼京線という非常に混む電車に乗っているので、早く他の人降りないかなとか目の前の人早く立たないかなとかイライラしながら考えます。
しかし、ここで考え見て欲しいのが「満員電車に乗っている人が全てイライラしているのか?」ということです。確かにイライラしている人が多いかもしれませんが、イライラしていない人は確かにいます。満員電車という同じ現象にいるにもかかわらず、立ちながら楽しそうに音楽を聴いている人もいると思います。この違いは満員電車という現象に対して心が反応していいるかいないかによって生まれます。現象に心が反応しているから怒りやイライラという無駄な特にならない感情が生まれているということです。
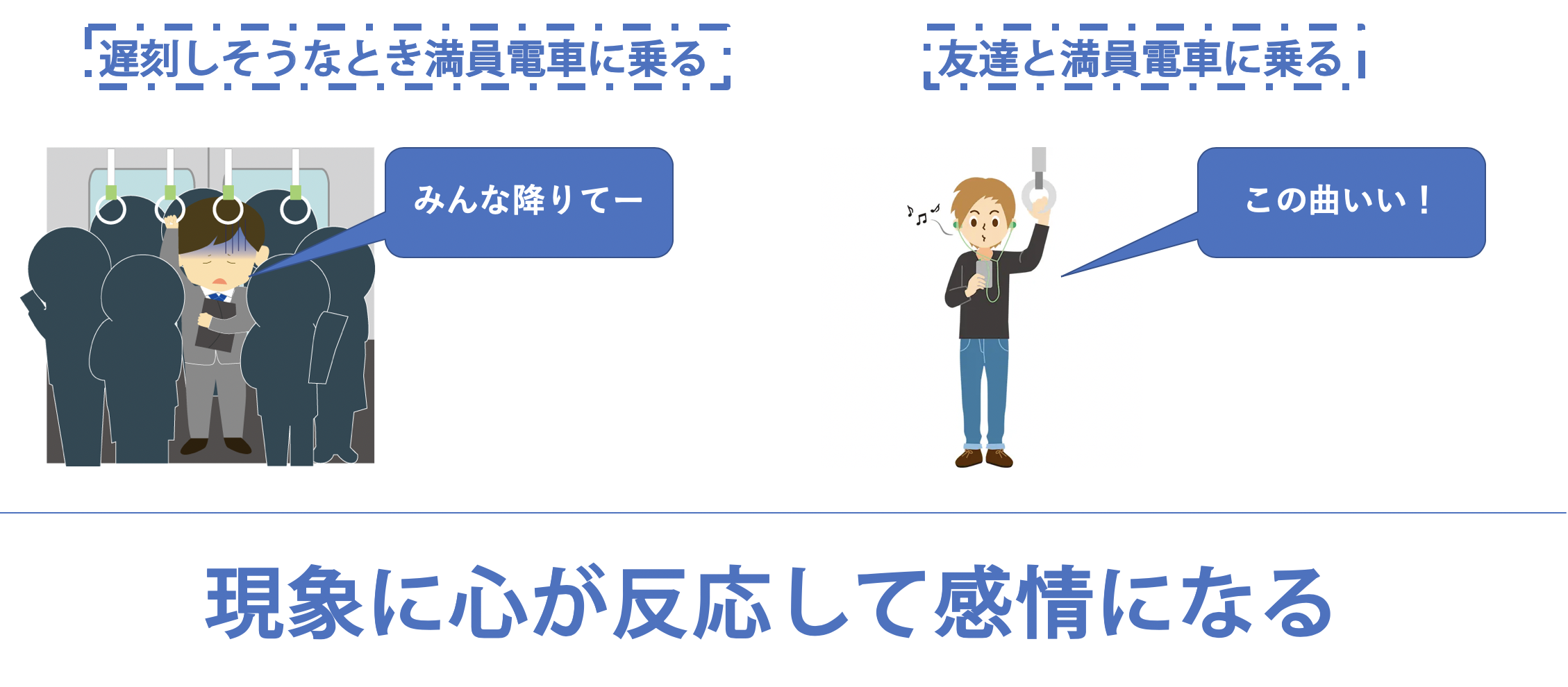
現代人は無駄な反応が多い
満員電車の事象はほんの一例で本来人はたくさんの理由でイライラや怒りなどの無駄な心の反応を生み出しています。例えば、カッとなって口喧嘩に発展したり、他人と比べて勝手に落ち込むなどです。このような反応は誰か得をするのでしょうかと言われれば誰も得しませんよね。しかし、このような無駄な反応から生まれた感情は毎日のように生み出され、それにより悩みやトラブルに発展したりします。
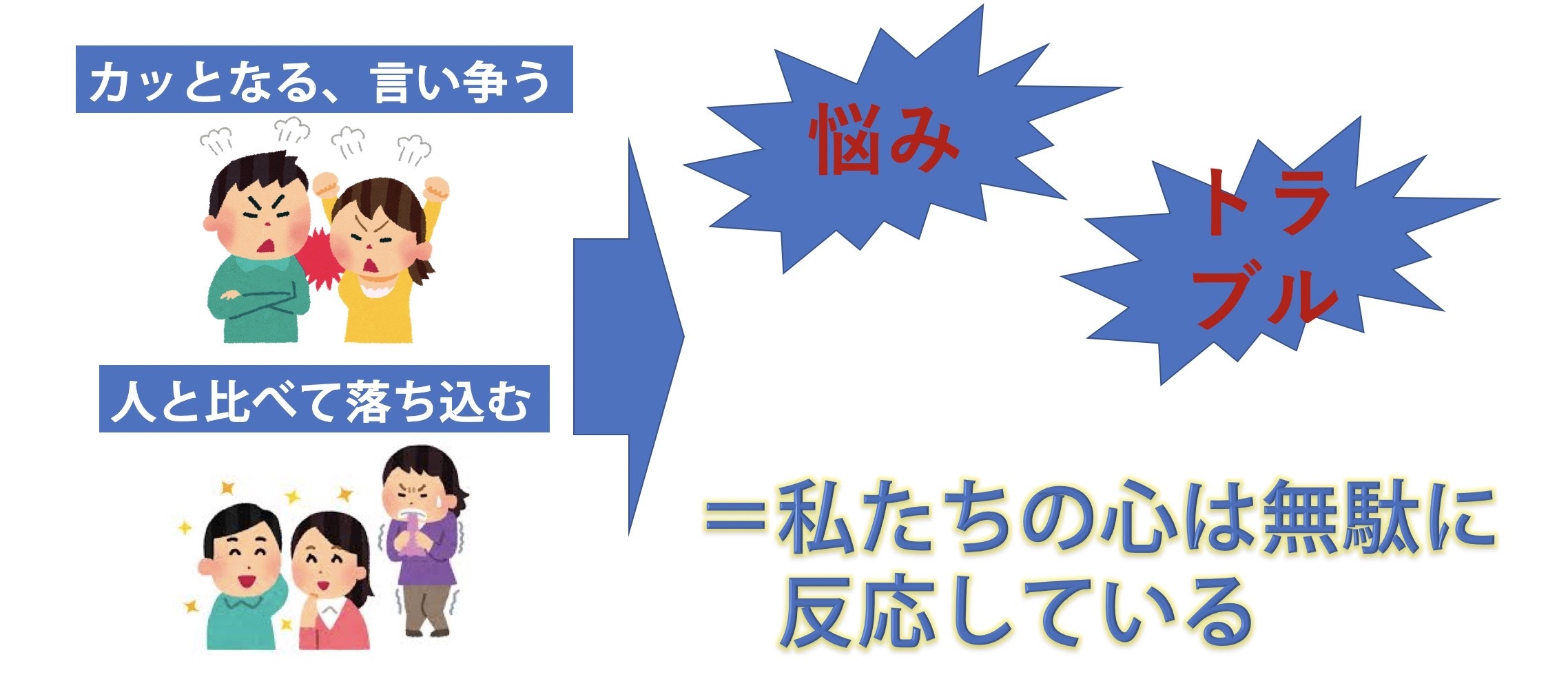
心が無駄に反応する原因
何故こんなにも人は無駄に反応してしまうのでしょうか。その答えとして仏教では「求める心が苦しみをもたらしている」と述べられています。求める心とは言い換えれば欲求です。睡眠欲、食欲とかがそれに当てはまります。しかし、睡眠欲や食欲では私たちは滅多にイライラしません。そりゃ元大社長が異世界に転生して貧乏社畜になったらそりゃ食欲やらは満たせずにイライラするかもしれませんが、日本人のほとんどは美味しいご飯を食べれているし、睡眠も取れている人も多いと思います(ブラック企業じゃなければ)。つまり、睡眠欲や食欲に関して言えば、欲求を満たすことをコントロールできるのです。
では「承認欲求」はどうでしょうか。こちらも求める心です。誰かに認められたい、承認されたいという思いは本当に誰しもが少なからず持っているものです。しかし、この欲求は自分でコントロールして満たせるものではありません。それは他人があなたを認めることで満たせる欲求であるからです。これが睡眠欲は食欲との大きな違いで、あなた自身でこの欲を満たすことができません。コントロールできない他人から承認してもらう必要があります。そのため、承認されないときに満たされず、結果心が反応してイライラしてしまうのです。この承認欲求が非常に厄介この上ないのです。
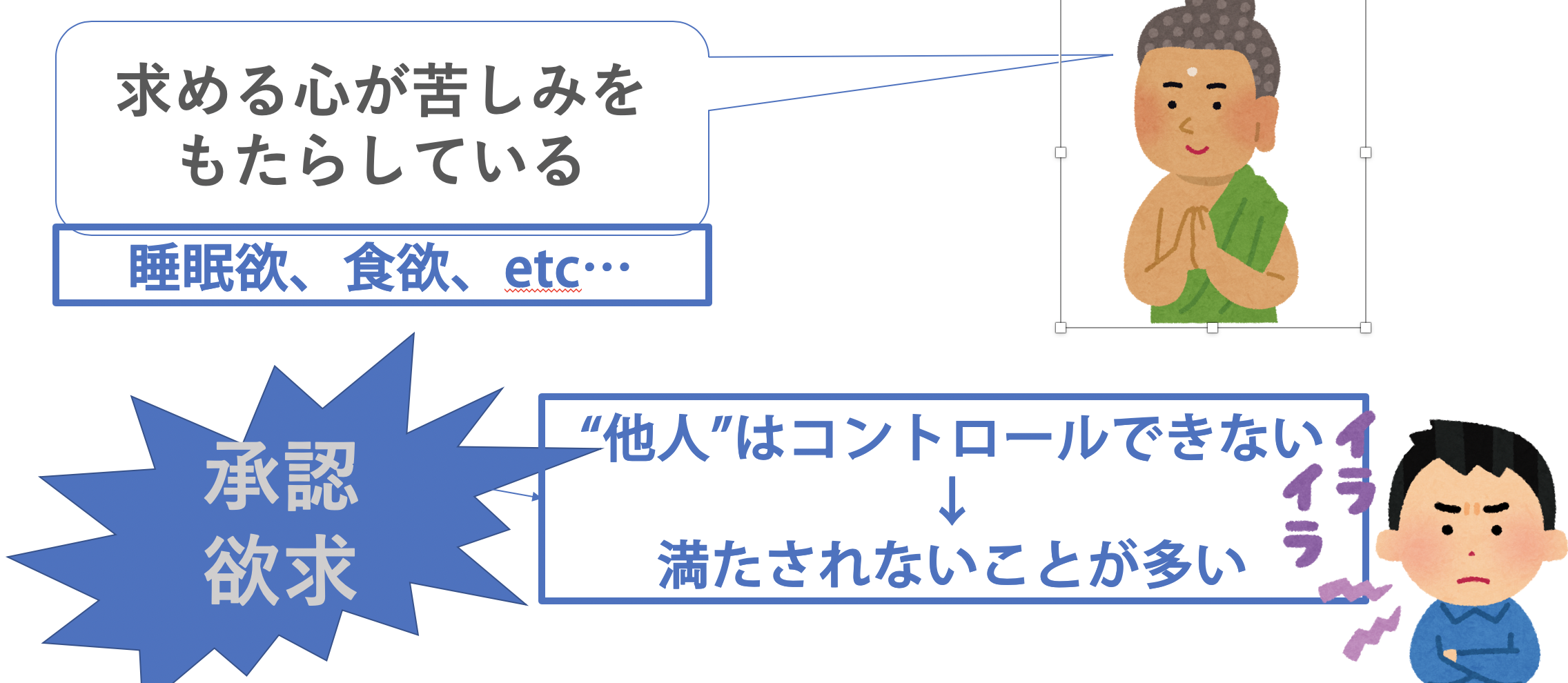
承認欲求が生む3つの心の状態
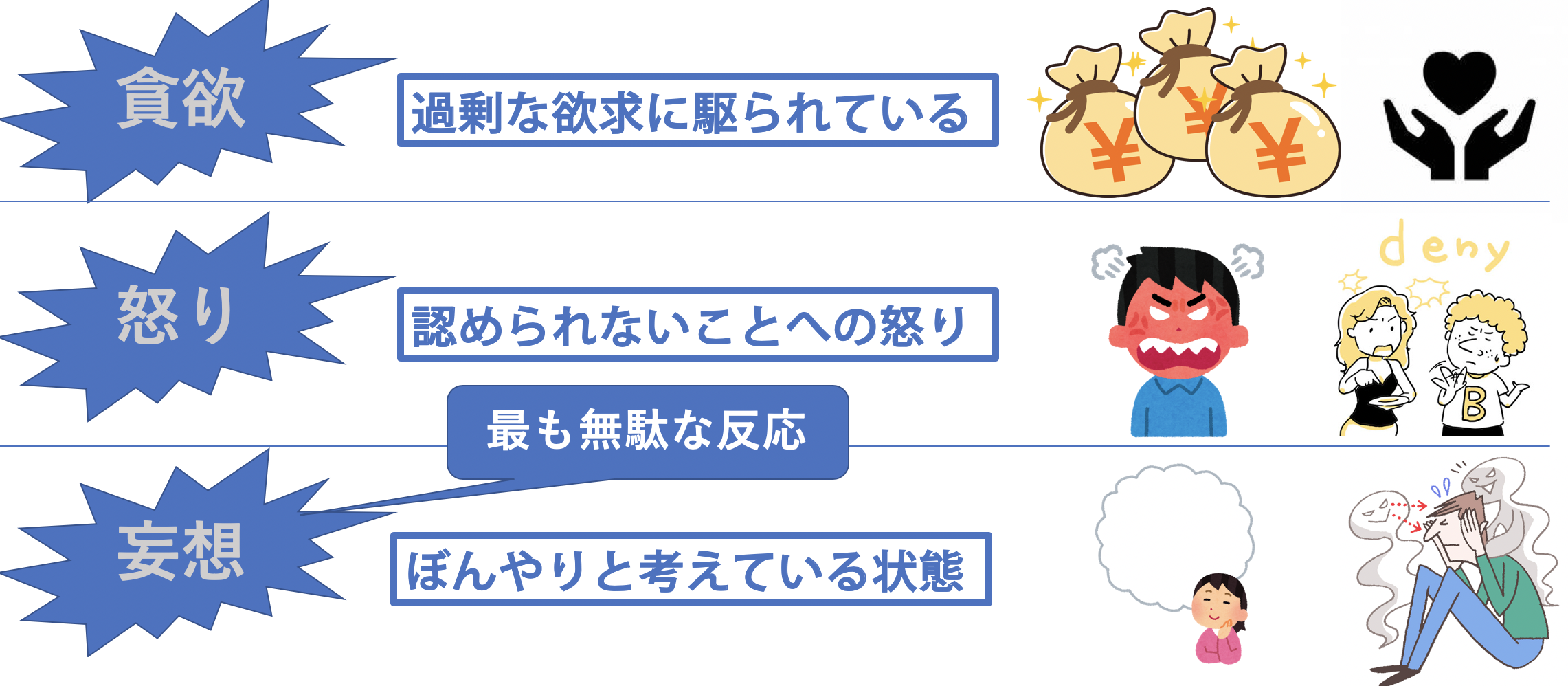
承認欲求によって3つの無駄な心の状態が生まれます。
① 貪欲
承認欲求から多くの貪欲が生まれます。人より上に立ちたいがためにお金持ちになることや、自分のステータスを上げるためにすごくステータスの高い彼女彼氏と付き合うとかです。このような状態は過剰な欲求に駆られており、非常によく深くそれを叶えるために行動しています。お金持ちになるために、付き合うために欲に駆られながら奔走している状態です。
② 怒り
承認欲求が満たされないことで多くの怒りが生じます。他人からの否定などから認められないことにイライラし、かッとなってしまっている状態です。
③ 妄想
そして3番目の心の状態の「妄想」です。これはぼんやりと物事を考えている状態です。これは人間なのだから誰しもがやっていることです。しかし、仏教では1番無駄な心の反応の状態が妄想している状態と述べています。
妄想は大きな勘違いを生む
ああなれたらいい、こうなれたらいいとかそういった物思いに耽ってる状態も妄想で、これはいい妄想かもしれません。しかし、妄想の中には度外きすぎるいわゆる勘違いの妄想も含まれます。
例えば、あなたのミスで上司からカンカンに怒られたとします。その時、あなたの心の反応としては「やってしまった。次から頑張ろう。気をつけよう。」といった前向きな考えになっているかもしれません。しかし、中には「自分はミスをしてしまうダメな人間なんだ、、、。」のような考えが生まれ、その考えから「同僚の人たちからもダメ人間と思われたんだ、、。」といった妄想を膨らませてしまう人もいます。このような大きな勘違いを生み出してしまうのが妄想の恐ろしいことです。

余談ですが、自分も妄想が膨らみ病んでしまったことがあります。大学4年生の頃、同じサークルの好きだった後輩の女の子に告白しまして見事に撃沈したことがあります。当時の自分はサークルのことが非常に好きだったのでとても行きづらくなってしまいました。そして、サークルの人たちと会わなくなったことから既にサークルで自分が振られたという情報が流れてしまい、自分はどう思われているんだろうかとかいろいろ考えてしまい、どんどんサークルの活動に行くのが怖くなっていきました。
でもこのような妄想って誰でもしたことがあるんだと思います。何かに失敗してしまった時、トラウマになる体験をした時、不安が募り色々と妄想してしまい勘違いを生み出す。そして病んでしまう。病んでしまうまではわかりませんが、大きな勘違いをした妄想を経験していない人は少ないでしょう。
判断 = 1版無駄な反応
私たちがここまで心の反応を生み出している根本的な要因はなんなのでしょうか。何故ここまで妄想を膨らませて自分を苦しめるのか。
それは「判断」があるからです。
判断とは何が正しくて何が違うのかを自分の中で決めることです。誰しもが行うことだと思うのですが、判断による心の反応は本当に無駄だと本では説明されています。
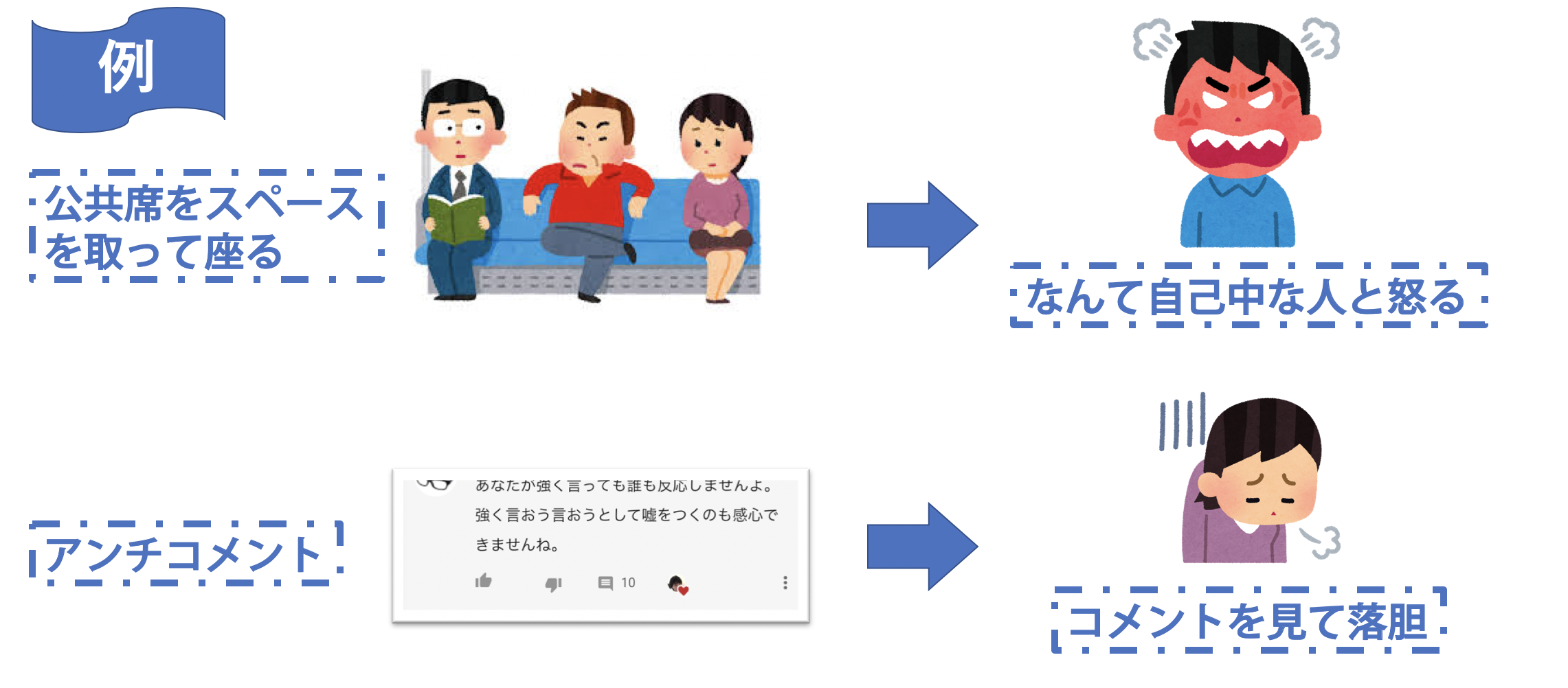
例えば、車内で2つの席を横取りする人がいれば、「なんて自己中な人だ!!」と怒ったり、YouTubeのアンチコメントを見て投稿者が落胆したりするというのは全て判断から生まれてくる感情です。
何故判断するのか?
普段何気なく判断しているけど判断する理由ってなんなんでしょうか。それには以下の2点が挙げられます。
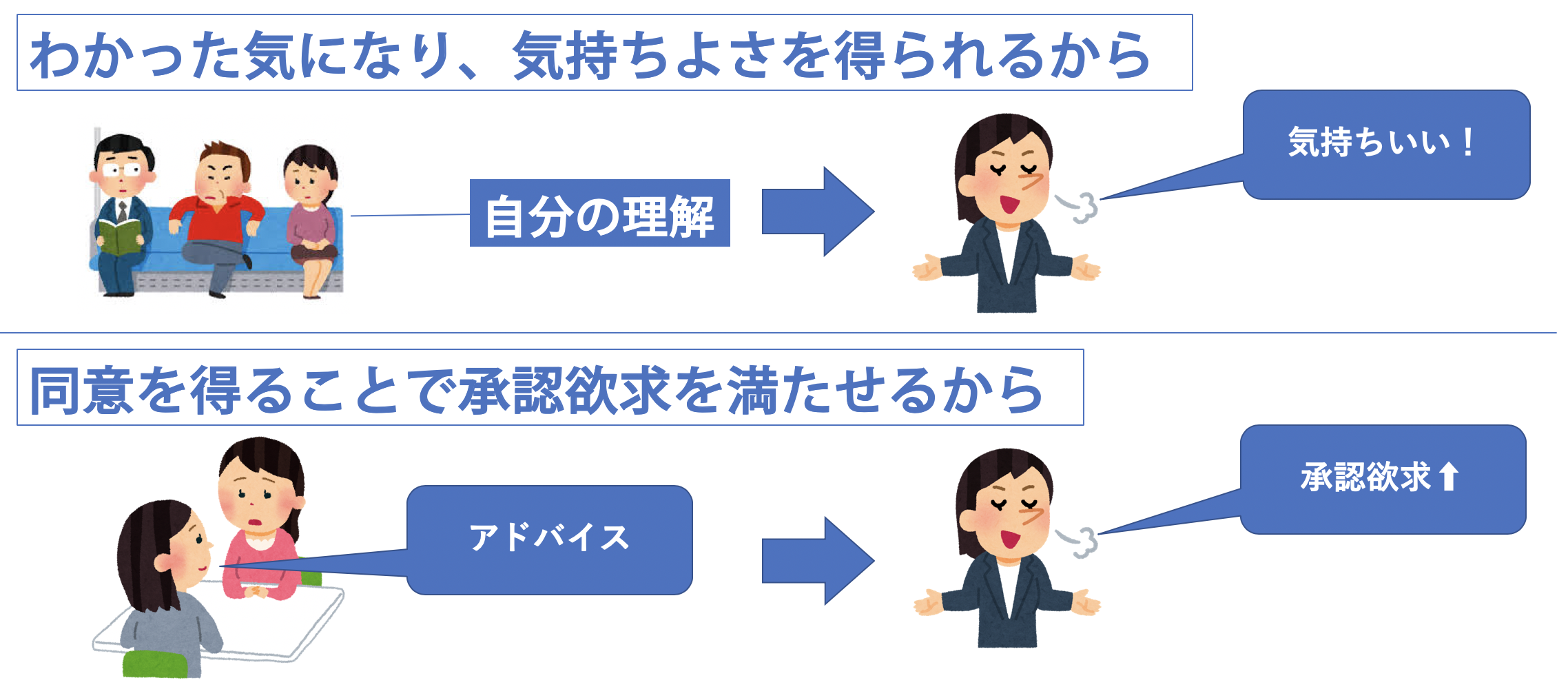
- わかった気になり、気持ち良さを得られる
- 同意を得ることで承認欲求を満たせるから
まずわかった気になれるので気持ち良さが得られることが挙げられます。自分の理解が正しいということを判断することは、自分が間違っていないということを論理づけます。そのため自分は間違っていない、正義であるということで勝手に気持ち良くなるんですね。自分で判断することでどこか安心感を求めているのです。
また、同意を得ることで承認欲求を満たせるからということが挙げられます。誰かに自分が判断したことに対して同意されるときもちいですよね。例えば、彼氏への不平不満を友達の女子に話して、友達から「そうだね、あなたの言い分はもっともだ」と言われると、自分が正しいということになり承認欲求が満たされます。
判断は猛毒
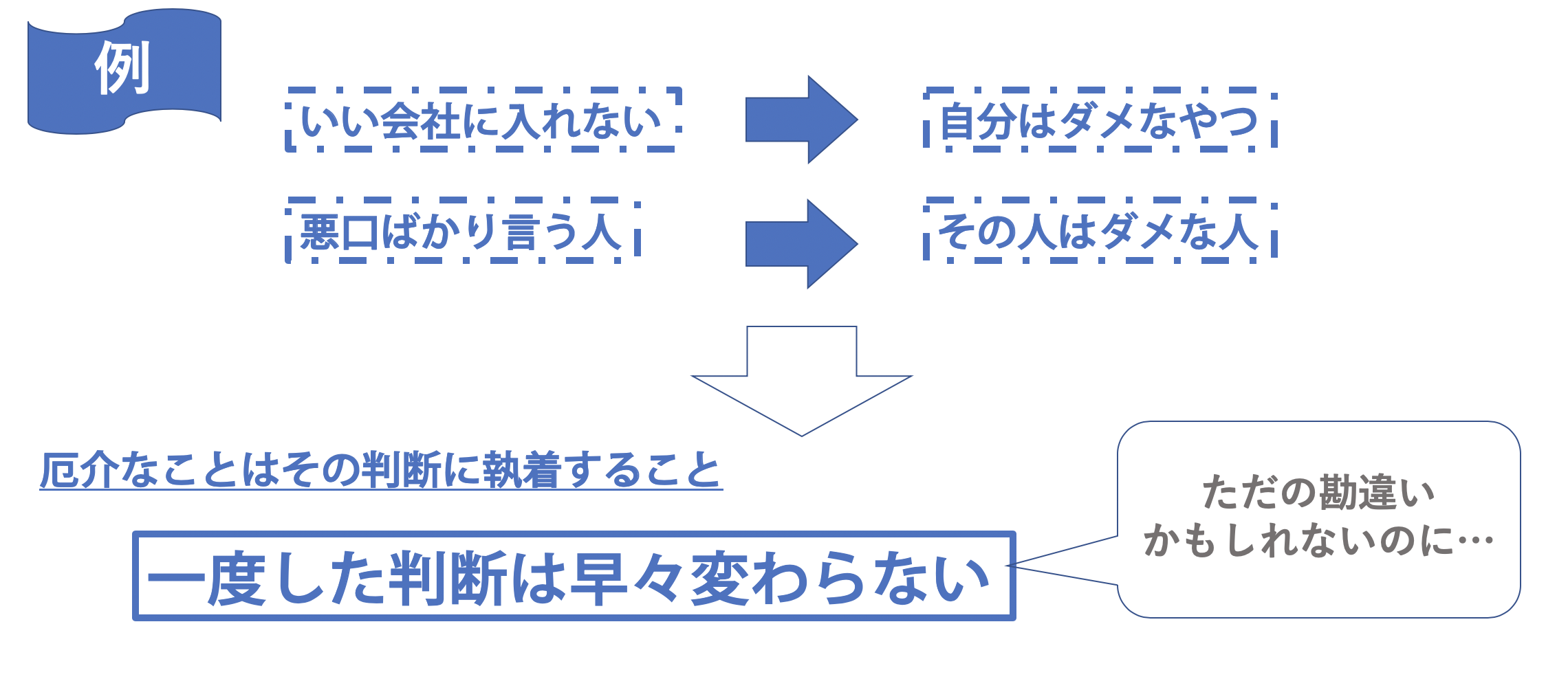
判断をするのは基本的に誰でもしますし、働いている上で判断をすることは避けられないでしょう。しかし、無駄な判断をしていることが多いため、自分のことを卑下したり、相手に怒りを覚えたりします。そして、厄介なことに一度自分で判断したことは易々とは変わりません。自分はダメだと思えばその判断はしばらく変わりませんし、相手がダメだと思えばその判断は変わらず絶交まで発展してしまうかもしれません。
苦しみから逃れる方法
承認欲求による妄想や無駄な判断をすることで苦しみ疲れることはわかりました。では、どのようにしてその苦しみから逃れるのでしょうか?
まず以下の2点があげられます。
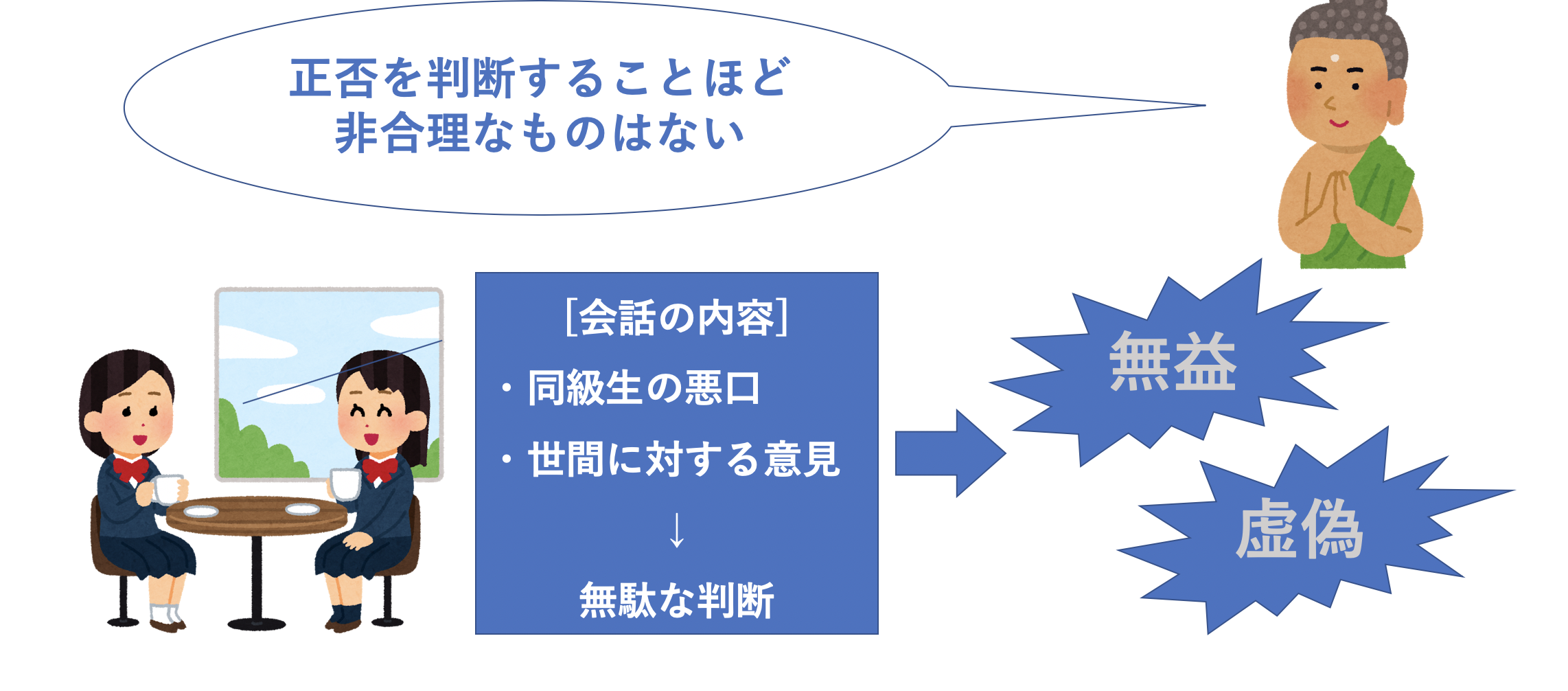
- 正しさは不要であると理解すること
正しさは不要だと理解します。そんなものいりません。というか正しさは人それぞれなので本当に正しいのはどっちと判断すること自体が不毛です。人それぞれ道徳は異なります。

- 判断すること=非合理
上述したように判断することでいいことはほっとんどありません。悪口や世間に対する意見だったりは何が正しいのかなんてどうせ答えは出ないし不毛だと思います。
1番有効な苦しみから逃れる方法
とは言ったものの上述したものは具体的じゃありません。結局何をすれば苦しみから逃れることができるのでしょうか。それは、反応した時に「あ、自分反応してるな」とできるだけ早く気づくことです。怒りの感情があれば「自分怒っているんだ」と気づくこと、頭の中で妄想していたらその妄想に気づくことです。

心の反応に特効薬はない
「え、気づくだけ?」
気づくことだけで本当に効果があるのでしょうか。実はこの気づきは1番効果的ですが、それでも効果がでるかわからないと言うのが答えです。
そもそもすぐに効く実践方法があれば誰もうつ病にはなりません。とっくにその方法は多くの人に知れ渡り、精神科医も必要ない世の中になっています。
つまり何が言いたいのかというと、心の反応を治療できるのは己自身だけということです。したがって、自分の気づきがなければ心の反応は治療できません。

"気づき"は有効
気づくだけで果たして効果があるのか。本でははっきりと「ある」と答えています。
というのも心が無駄に反応している状態に気づくことはそもそもみんな普段していません。彼女にふられてクヨクヨすることや怒りに身を任せている時、「あ、自分今無駄な反応をしている」とは思わないですよね。つまり、気づくことを普段実践していないのです。
そして気づくことは冷静に戻ることを意味します。気づくことで初めて人は無駄な反応をやめるきっかけを作れます。つまり、気づくことによって無駄な反応をやめる実践ができるのです。

終わりに
気づくことは普段やっていないためほとんどの人が練習していません。なので気づくことから練習していきます。そして、その気づきを積み重ねればそれはどんどんと無駄な反応を抑える練習になります。そしてそれが癖になれば無駄な反応はだいぶ抑えられると思いませんか?是非本を読んでみて気づく練習をしてみてください。
【無職に転生 ~ 就職するまで毎日ブログ出す⑧】【SQL】JOIN
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!!昨日までは就活するまで本気出すでしたが、これだとまるで就活後は頑張らないのかと思われてしまいそうで、、、大人気アニメのタイトルのまるパクリチャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
本日は初学者の多くがつまづくであろうJOINに関して書いていこうと思います。自分も正直理解が浅いこともあり今でも「あれ、この書き方でちゃんと意図した通りにテーブル結合されているかな?」なんてことは頻発しています。そのため、本日は「JOINに関するいろいろ」というタイトル通り、JOINに関連しているSQLを紹介していきます。
JOINが存在する理由
まずJOINはなぜあるのかについてです。
「え、テーブルとテーブルを結合するからじゃない?」
そうです。テーブルとテーブルを結合するからです。ここで言いたいのは、テーブルが複数存在することが重要です。つまり、テーブルが正規化されていることがテーブルが複数存在することにつながっています。
Database normalization is useful because it minimizes duplicate data in any single table, and allows for data in the database to grow independently of each other (ie. Types of car engines can grow independent of each type of car). データベースの正規化は、1つのテーブル内の重複データを最小限に抑え、データベース内のデータが互いに独立して増加することを可能にするため、有用です(例えば、自動車のエンジンの種類は、それぞれの自動車の種類とは独立して増加することができます)
データベースの正規化によりテーブルが細かく分けられそれぞれのテーブルが独立した役割を持っています。それにより各テーブルがシンプルな状態に保たれます。

https://proengineer.internous.co.jp/content/columnfeature/6480
正規化されることでテーブルは複数存在しますが、これらのデータを組み合わせようとすると「一つのデータを取り出す」「別のデータを取り出す」「取り出した二つのデータを組み合わせる」という三つの工程が必要になります。テーブルを独立させてしまったがために処理の工数が増えてしまいました。
それを解決するためにJOINが存在します。必要なデータを結合させて取得するデータをセットで揃えることで工数を削減することができます。
JOINの種類
JOINにはテーブルの結合方法として大まかに二つあります。
- 内部結合 (INNER JOIN)
- 外部結合 (LEFT JOIN)
内部結合
内部結合であるINNER JOINはテーブル結合の中で頻繁に出てきます。この結合は二つのテーブルで共通の列をマッチングさせて、マッチしたものをテーブルとして抽出します。
書き方としては下記のとおり。共通列とは外部キーに相当します。
SELECT テーブル.列(別テーブル.列) FROM テーブル JOIN (INNER JOINと同義) 別テーブル ON テーブル.共通列 = 別テーブル.共通列
見るは言うより易し。まずは内部結合の例文を書きます。
例えば、下記のようなテーブルがあるとします。
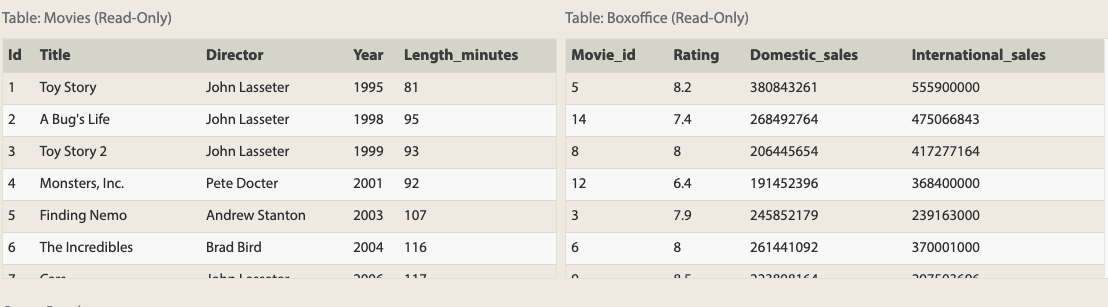
https://sqlbolt.com/lesson/select_queries_with_joins
そしid、title、domestic_sales、international_salesを取得します。
SELECT movies.id, movies.title, boxoffice.domestic_sales, boxoffice.international_sales FROM movies JOIN boxoffice ON movies.id = boxoffice.movie_id ORDER BY movies.id;
結果
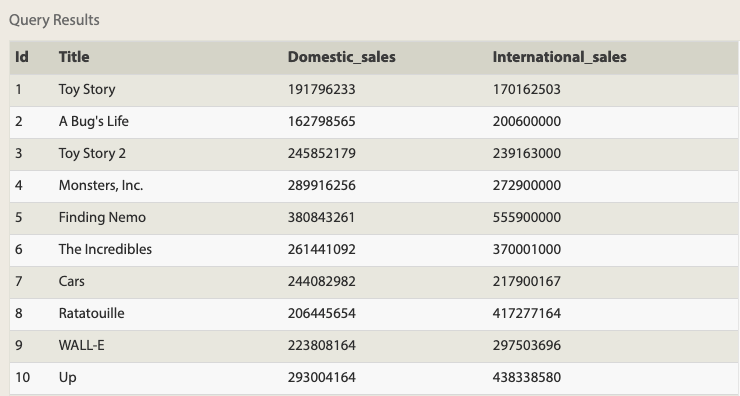
今回のテーブル群の共通列はmoviesテーブルのid列とboxofficeテーブルのmovie_id列になります。それらを指定して結合させることができます。
ON movies.id = boxoffice.movie_id
各列に対してテーブル名.列としている理由は、二つのテーブルに同名の列がある場合、テーブル名をつけないとどちらのテーブルの列になるのかわからないためです。例えば、もしboxofficeの列にidがあるのであれば下記の場合エラーになります。
SELECT id, id FROM movies JOIN boxoffice ON movies.id = boxoffice.movie_id ORDER BY movies.id;
正しく動かすためにはテーブル名をつけてどのテーブルのidかを指定します。
SELECT movies.id, boxoffice.id FROM movies JOIN boxoffice ON movies.id = boxoffice.movie_id ORDER BY movies.id;
今回の場合同名のカラムはないのでテーブル名をつけなくても問題はないのですが、一応テーブル名をつけておく方法も理解しておきます。
INNER JOINの性質として条件にマッチしないベースとなるテーブルは削除されるというものがあります。
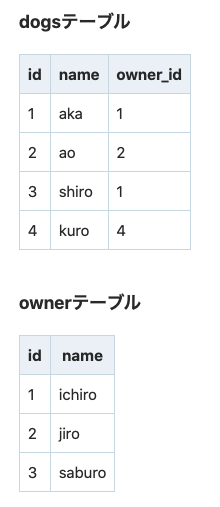
ここでテーブルをINNER JOINさせます。
SELECT * FROM dogs JOIN owners ON dogs.owner_id = owners.id;
結果
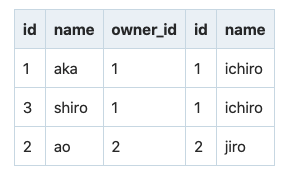
dogsテーブルのkuroがいなくなっていることに注目してください。kuroのowner_idは4です。ですが、ownersテーブルでidが4番は存在していません。内部結合の場合、ベースとなるテーブルから、条件にマッチするレコードがないものは削除されるのです。
SQL素人でも分かるテーブル結合(inner joinとouter join)
ほとんど引用ですみません。ですが説明を見てわかるとおりベースとなるテーブルの列が外部テーブルの列にマッチしないレコードは削除されてしまいます。
外部結合
LEFT JOINは上記のようにベースとなるテーブルからレコードが削除されて欲しくない場合に使用します。
SELECT * FROM dogs LEFT JOIN owners ON dogs.owner_id = owners.id;
出力結果
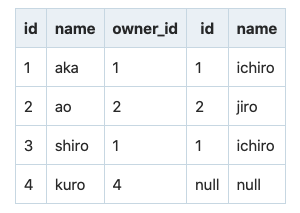
外部結合をすると、外部の列にないレコードは削除されず残ってしまうため、列にないレコードはnullとして出力されてしまいます。nullで出力されたくない場合はCOALESCE関数を使ってnullを置き換えます。
SELECT dogs.id, dogs.name, COALESCE(owners.name, '外部テーブルは空値') FROM dogs LEFT JOIN owners ON dogs.owner_id = owners.id;
参考記事
【無職に転生 ~ 就職するまで毎日ブログ出す⑦】【Rails】忘れがちな便利な書き方
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!大人気アニメのタイトルをまるパクリした毎日投稿チャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
便利な書き方を3つ紹介したいと思います。
- 自己代入
- ぼっち演算子
- Array.map(&:to_i)
三つも紹介するので他の記事に比べて内容は薄いものとなりますのでご了承を。あくまで個人ブログのアウトプットで。しかし、全く他の記事と同じにしてしまうと意味がないので、ここでは上記3つがRailsでどのタイミングで使われるのかもアウトプットしたいと思います。
自己代入
||=というよく使われる記号です。gemの中身の処理を見ると至る所にこの記号が見られます。
a ||= 1
自己代入と言われている記事もありますが、正式な名称はググってもわかりませんでした。。
この処理は何をやっているのかというと、以下の処理と同じことをしています。
a = a || 1
変数aにaもしくは1を入れる処理です。aがもし真であれば(つまり、nilやfalseでなければ)aが代入されます。そして、もしaが偽であれば1が代入されます。したがって、元々aに値が入っている場合は1は代入されません。
a = 2 => 2 a ||= 1 => 2
さてさて、この処理の意味は分かったのですが、果たしていつ使えば良いのでしょうか。この記述最近見たと思ったのですが、sorceryの外部認証の処理部分で出てきました。
@access_token ||= @provider.process_callback(params, session) # sends request to oauth agent to get the token @user_hash ||= @provider.get_user_hash(@access_token) # uses the token to send another request to the oauth agent requesting user info
この処理ではなぜ||=を使う必要があるかを考えたのですが、DRYを避けるためだそうです。
When do we use the "||=" operator in Rails ? What is its significance?
@access_token、及び@user_hashは現状nilになることは間違いなく(処理の中でこれら二つのインスタンス変数はどこにも使われていないため)、= で代入したとしても問題ありません。しかし、今後別の箇所でこれらの値を使うかもしれません。そうなったときに、もし=で評価しておくと、@access_tokenを取得する処理や@user_hashを取得する処理が既に取得済みであるにもかかわらず実行されます。結果2度処理が走ってしまいます。そのため、||=を使用しておくことで将来的なコードがDRYになることを防いでいます。(記述的には2度同じ処理を書いているのでDRYですが、片方は実行されないため処理的にはDRYです。)
ぼっち演算子
セーフナビゲーションとも言われる処理です。&.という記述を使用します。nilがレシーバーであるときlengthメソッドは失敗します。よくあるNoMethodErrorですね。
a = nil => nil a.length (irb):2:in `<main>': undefined method `length' for nil:NilClass (NoMethodError)
しかし、もし&.lengthと書いておくとレシーバーがnilの時はエラーを出さずにnilを返します。
a&.length
=> nil
セーフナビゲーションと名前がついているようにエラーを回避してくれる書き方ですね。
セーフナビゲーションの使い時ですが、Qiitaの記事を引用します。
Rubyにはメソッドの返り値が
「配列またはnil」、「文字列またはnil」などを返すものが多いのでそのようなときにnilになったレシーバにnilに対応していないメソッドを使ってしまうとNoMethodError(そんなメソッドないよ!)というふうに返してしまいエラーが出てしまいます。だからといって場合分けするとコードが複雑になるしコード量が増えてしまう。 そこで導入されたのが&.です。これはメソッド呼び出しの.と同じ使い方だけれど,レシーバーが nil のときだけはメソッドが呼び出されないで nil を返す、というものです。
https://qiita.com/yoshi_4/items/e987b698c1978d248cfc
NoMethodErrorのNilClassはほんとに頻繁に起こすと思うので、&.と書くことでエラーを回避できるのはありがたいですよね。条件分岐を使ってif hoge.nil?みたいにいちいち場合わけ処理を書かなくても&.を使ってnilが変えるようにし、以降の処理でエラーが起きないようにすれば処理はエラーになりません。ただ、エラーが起こらないので気づかないうちに別のバグの温床になる可能性もあるので。セーフナビゲーションをどこに書いてあるのかは意識しておくと良いかもしれませんね。
ちなみにぼっち演算子の名前の由来は下記のとおりです。
おそらく気になった方も多いと思いますが、ぼっち演算子のぼっちの部分は&.がひとりぼっちで座っている姿に見えることから名付けられたそうです。
https://qiita.com/yoshi_4/items/e987b698c1978d248cfc
Array.map(&:to_i)
この書き方も本当によく見ると思います。例えば、下記のような処理があるとします。
["1", "2", "3"].map{|v| v.to_i}
これは下記のような書き方に置き換えることができます。
["1", "2", "3"].map(&:to_i)
競技プログラミングなどで整数の配列を取得するときも以下のような書き方が使われます。
numbers = gets.split.map &:to_i
初見だと何が行われているかわかりませんが、実はProcが大きく関わっています。ここからはかなり余談に聞こえるかもしれませんが後ほど話がつながりますので長い目で見てください。
ProcとはRubyのブロックをオブジェクト化できるクラスです。newメソッドの引数をブロックに指定することでブロックのオブジェクトを作成できます。
Proc.new {a} => #<Proc:0x00007ffaf9bd7a08 (irb):22>
ここで下記の処理は可能なのかどうかを考えます。
prc = Proc.new {|v| v.to_i} ["1", "2", "3"].map prc
答えは不可で下記のエラーが出てしまいます。理由はmapメソッドはブロック引数ですが、Procの場合はそのまま引数の値として渡されているためです。
# `map': wrong number of arguments (given 1, expected 0) (ArgumentError)
ここで&の登場です。
ブロック付きメソッドに対して Proc オブジェクトを `&’ を指定して渡すと 呼び出しブロックのように動作します。
Procオブジェクトを&を使用すると確かに処理はうまく実行されます。
prc = Proc.new {|v| v.to_i} ["1", "2", "3"].map &prc => [1, 2, 3]
ここでなぜ上記の処理を説明したのかというとこの&がまさに&:to_iの&の役割と同じであるということです。シンボルである:to_iに対して&を付けています。ここでシンボルに&を修飾することで何が起こるのかというとto_procが呼び出し実行されるようです。
to_proc メソッドを持つオブジェクトならば、`&' 修飾した引数として渡すことができます。デフォルトで Proc、Method オブジェ クトは共に to_proc メソッドを持ちます。to_proc はメソッド呼び出し時に実行され、Proc オブジェクトを返すことが期待されます。
class Foo def to_proc Proc.new {|v| p v} end end [1,2,3].each(&Foo.new) => 1 2 3
つまりこの形は以下のように本当は以下のように実行されます。
["1", "2", "3"].map(&:to_i) ↓ ["1", "2", "3"].map(&:to_i.to_proc)
ここらへんの処理、もうちょっとわかりやすく説明したいですね、、、後ほど変更します。。
参考記事
When do we use the "||=" operator in Rails ? What is its significance?
【無職に転生 ~ 就職するまで毎日ブログ出す⑥】【Rails】seed_fu
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!大人気アニメのタイトルをまるパクリした毎日投稿チャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
gemであるseed_fuについて書いてみたいと思います。たまたま今やっている開発で使う機会がありました。
gemのステータスとしては以下のとおり。
- star数・・・1.2k
- user数・・・3.7k
- 最終更新日・・・2018年4月7日
かなり多くのユーザーから使われているgemですが、最終更新日が約4年前になっていますね。ただ、seedファイルの設定であり、railsの仕様が大きく変更されない限りは不具合が起きないと思うので、メンテナンス性はそこまで大きな問題ではなさそうです。
セットアップ
早速導入方法から!
gemを追加
gem 'seed-fu'
bundle installする
$ bundle install
次にseed_fuのテストデータを作成するファイルを追加します。seed_fuのファイルを作成する前にfixturesディレクトリを作成します。
$ mkdir db/fixtures $ mkdir db/fixtures/development $ mkdir db/fixtures/production
developmentとproductionのディレクトリは作成しなくてもいいのですが、本番環境と開発環境でファイルを分けたい場合は上記のようにfixtures配下に分けてディレクトリを作成します。
これでセットアップは完了です。
初期データを作成
作るデータは下記のモデルにします。
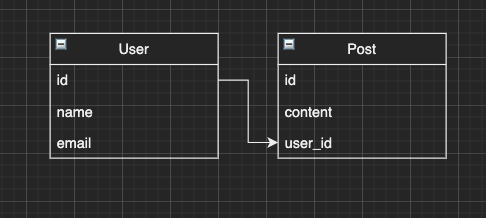
# user.rb class User < ApplicationRecord validates :name, presence: true validates :email, presence: true has_many :posts, dependent: :destroy end
# post.rb class Post < ApplicationRecord validates :content, presence: true belongs_to :user end
まず、Userのデータから作成します。ファイル名「01_user.rb」をdb/fixtures/development配下に作成します。ここで「01」とプレフィックスをつける理由は後ほど説明します。
$ touch db/fixtures/development/01_user.rb
そして、ファイルを以下のように記述します。
# db/fixtures/development/01_user.rb User.seed do |s| s.id = 1 s.email = "daiki@example.com" s.name = "Daiki" end
これで下記コマンドを実行すると初期データを作成することができます。
$ rake db:seed_fu == Seed from /path/to/app/db/fixtures/development/01_user.rb - User {:id=>1,:email=>"daiki@example.com", :name=>"Daiki"}
今だとユーザーが1人しか作成されていないので、もう1人追加します。
# db/fixtures/development/01_user.rb User.seed do |s| s.id = 1 s.email = "daiki@example.com" s.name = "Daiki" end User.seed do |s| s.id = 2 s.email = "yusuke@example.com" s.name = "Yusuke" end
再度seedデータを入れます。
$ rake db:seed_fu == Seed from /path/to/app/db/fixtures/development/01_user.rb - User {:id=>1,:email=>"daiki@example.com", :name=>"Daiki"} - User {:id=>2,:email=>"yusuke@example.com", :name=>"Yusuke"}
このように作成するデータを並べるように記述していきます。しかし、これではたくさんのデータを作成するときに冗長になってしまうため、下記のような書き方もできます。
# db/fixtures/development/01_user.rb User.seed( :id, { id: 1, name: "daiki@example.com", email: "daiki@example.com" }, { id: 2, name: "yusuke@example.com", email: "Yusuke@example.com" }, )
個人的にはたとえ作成するデータが一つでも上記のように書いておく方が後々初期データを追加する際に手間が省けて便利だと思います。
次にpostの初期データを作成します。ファイル名「02_post.rb」をdb/fixtures/development配下に作成します。
$ touch db/fixtures/development/02_post.rb
次にテストデータを作成します。
# db/fixtures/development/01_user.rb Post.seed( :id, { id: 1, content: "content1", user: User.find(1) }, { id: 2, content: "content2", user: User.find(2) }, )
$ rake db:seed_fu == Seed from /path/to/app/db/fixtures/development/01_user.rb - User {:id=>1,:email=>"daiki@example.com", :name=>"Daiki"} - User {:id=>2,:email=>"yusuke@example.com", :name=>"Yusuke"} == Seed from /path/to/app/db/fixtures/development/02_post.rb - Post {:id=>1,:content=>"content1", :user_id=>1} - Post {:id=>2,:content=>"content2", :user_id=>2}
関連データも作成することができました。
プレフィックスをつけた理由ですが、関連データを作成する順番のためプレフィックスをつけました。親モデルは必ず子モデルより先に作成されています。そのため、テストデータも親モデルから先に作成する必要があります。そして、seed_fuが初期データを作成する時、ファイルを実行する順番はファイルの並び順で上から下にかけて実行します。
もし、ファイル名が「post.rb」と「user.rb」の場合、seed_fuの実行順序は下記になります。
post.rb ↓ user.rb
しかし、ユーザーが作成されていないので上記の場合は失敗します。
プレフィックスをつければファイルの順番をプレフィックスで調整できるので、実行順序を操作することができます。
01_user.rb ↓ 02_post.rb
seed_fuを使う際はプレフィックスをつける方法が良いでしょう。
seed_fuのメリット
ここまでseed_fuの使い方を書いてきましたが、seed.rbでよくないかと思う方もいると思います。しかし、seed_fuは下記の2点で便利です。
- いちいちデータを初期化する必要がない
seed.rbでは再度初期データを入れる場合は下記コマンドを実行します。
$ rails db:reset
つまり、データを全部削除しその後初期データを入れ直します。このとき作成する初期データが膨大であれば待ち時間が多くなりますし、そもそもちょっとした変更でもデータを全部削除しなければならないのは効率が悪いです。
しかし、seed_fuであればそれは解決できます。まだ紹介していなかったのですが、seed_fuではテストデータをファイルごとに分けているため、パスを指定して入れるデータを指定できます。例えば、上述したPostモデルの初期データのcontentを変更します。
# db/fixtures/development/01_user.rb Post.seed( :id, { id: 1, content: "hogehoge", user: User.find(1) }, { id: 2, content: "hogehoge", user: User.find(2) }, )
そしてパスを指定して初期データを入れてあげます。
$ bundle exec rake db:seed_fu FILTER=02_post - Post {:id=>1,:content=>"hogehoge", :user_id=>1} - Post {:id=>2,:content=>"hogehoge", :user_id=>2}
先ほどはUserも初期化されましたが今回はパスを指定したことによりPostモデルのデータだけ再度作成されました。これにより、無駄なデータの全削除を回避することができます。
- モデルごとにファイルを分けることができる
seed.rbを使う場合は全てのモデルを一つのファイルにまとめなければいけません。
User.create!( email: 'daiki@example.com', name: 'daiki', ) Post.create!( content: 'content1', user: User.find(1) )
まだモデル数が少ないので分ける必要はないかもしれませんが、大体のアプリはモデル数がもっとあるはずです。そのときに上記のように一つのファイルにまとめた場合、記述量が膨大になってしまいます。
しかし、上述したとおりseed_fuであればファイルを分けることができます。
参考記事
【無職に転生 ~ 就職するまで毎日ブログ出す⑤】【Rails】OauthsControllerの解説
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!大人気アニメのタイトルをまるパクリした毎日投稿チャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
昨日と一昨日でsorceryでslackログインを実装できたことを確認しましたが、実際にどのような流れでログインができているのか難しいと思います。そこでOauthsControllerコントローラーをデバックして処理を解説していきます。
# app/controllers/oauths_controller.rb class OauthsController < ApplicationController skip_before_action :require_login def oauth login_at(auth_params[:provider]) end def callback provider = auth_params[:provider] if (@user = login_from(provider)) redirect_to root_path, notice: "#{provider.titleize}でログインしました" else begin @user = create_from(provider) reset_session auto_login(@user) redirect_to root_path, notice: "#{provider.titleize}でログインしました" rescue StandardError redirect_to root_path, alert: "#{provider.titleize}でのログインに失敗しました" end end end private def auth_params params.permit(:code, :provider) end end
ただ、やはりgemの処理は複雑で長い処理で構成されており、全てを開設するととんでもない文章量になるので所々は割愛します
slack認証画面までの処理
まずは「Login with Slack」ボタンを押してからSlackの認証画面に遷移するまでの処理を解説します。
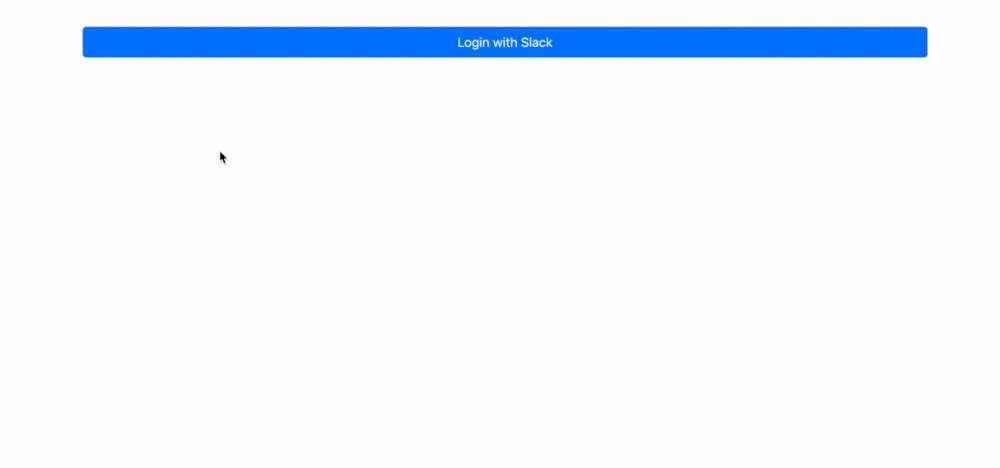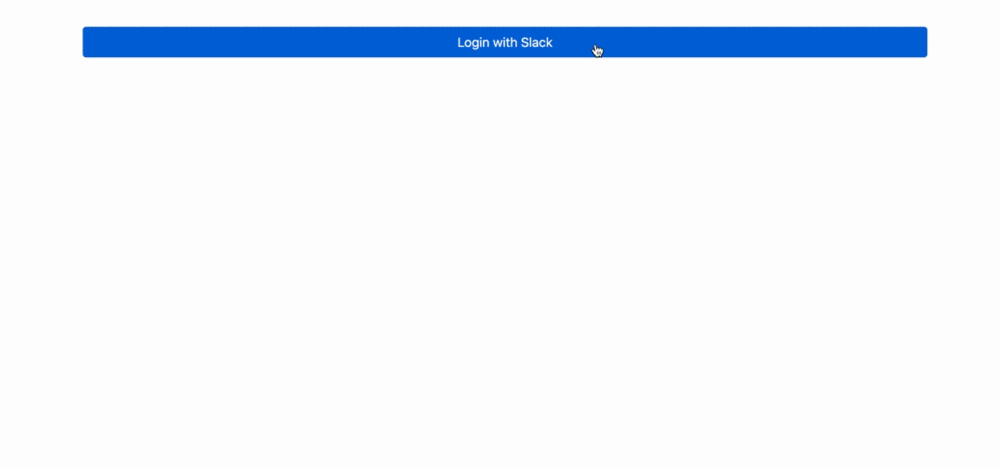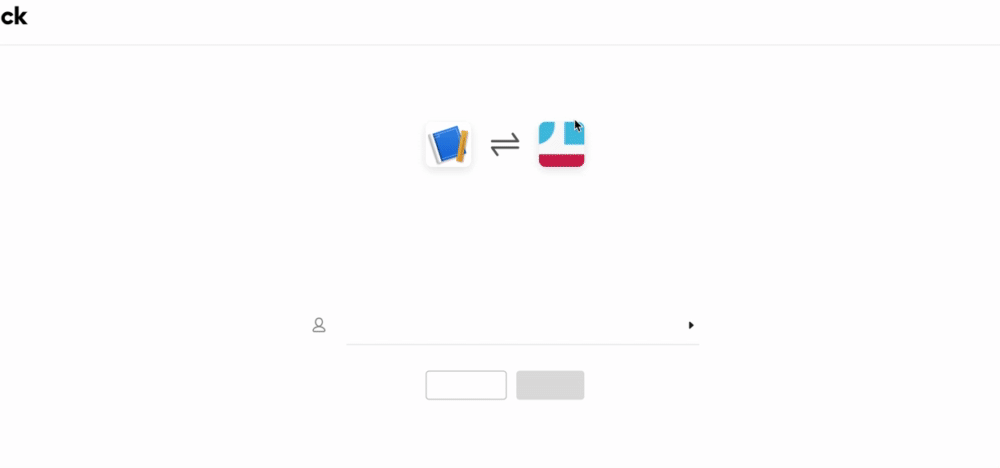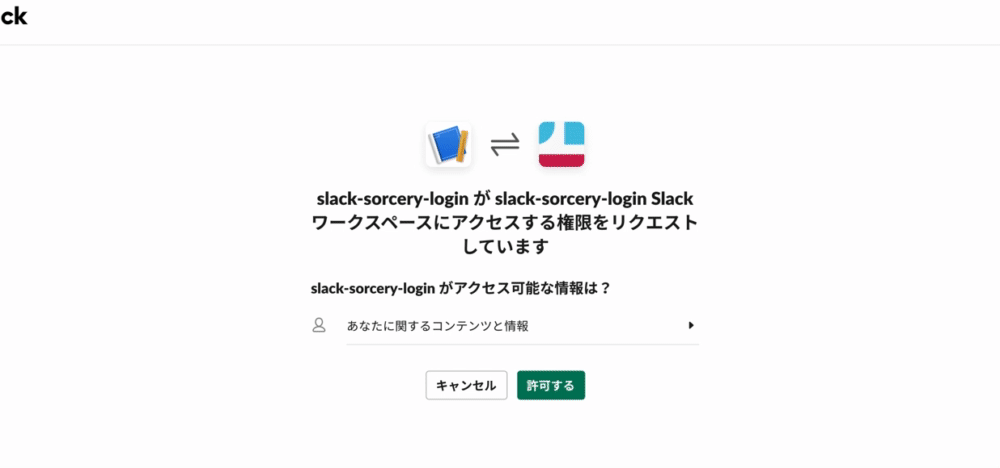
まずoauthメソッドですがこれは「Login with Slack」を押した際に実行されます。
def oauth login_at(auth_params[:provider]) end
privateメソッドであるauth_paramsメソッドを引数にしてlogin_atメソッドを実行します。paramsの値は下記のようになっています。
#<ActionController::Parameters {"controller"=>"oauths", "action"=>"oauth", "provider"=>"slack"} permitted: false>
auth_params[:provider]とproviderの値を取得しているので、login_atメソッドの引数は"slack"になります。
auth_params[:provider] => "slack"
login_atメソッドはgemの中で下記のように定義されています。外部認証するためにproviderのサイトにアクセスするメソッドです。
# vendor/bundle/ruby/2.6.0/gems/sorcery-0.16.1/lib/sorcery/controller/submodules/external.rb # sends user to authenticate at the provider's website. # after authentication the user is redirected to the callback defined in the provider config def login_at(provider_name, args = {}) redirect_to sorcery_login_url(provider_name, args) end
sorcery_login_urlメソッドは外部認証サイトへのURLを発行します。これにlogin_atメソッドでredirect_toメソッドを使うことで外部認証サイトへ遷移しているんですね。
# get the login URL from the provider, if applicable. Returns nil if the provider # does not provide a login URL. (as of v0.8.1 all providers provide a login URL) def sorcery_login_url(provider_name, args = {}) @provider = sorcery_get_provider provider_name sorcery_fixup_callback_url @provider return nil unless @provider.respond_to?(:login_url) && @provider.has_callback? @provider.state = args[:state] @provider.login_url(params, session) end
Slack認証後の処理
そしてSlackの認証画面で「許可する」を押した後の処理はcallbackメソッドです。
def callback provider = auth_params[:provider] if (@user = login_from(provider)) redirect_to root_path, notice: "#{provider.titleize}でログインしました" else begin @user = create_from(provider) reset_session auto_login(@user) redirect_to root_path, notice: "#{provider.titleize}でログインしました" rescue StandardError redirect_to root_path, alert: "#{provider.titleize}でのログインに失敗しました" end end end
先ほどと同様に"slack"の値を取得します。
provider = auth_params[:provider]
login_from(provider)で既にユーザーがSlackログイン済みであれば@userに格納します。
if (@user = login_from(provider))
login_fromメソッドの中身は以下のようになっています。流れとしてはユーザーを探し、ユーザーがいればセッションなどをクリアしユーザーをログインさせる処理が実行されます。ユーザーがいなければreturnでnilを返却するようにしています。
# tries to login the user from provider's callback def login_from(provider_name, should_remember = false) sorcery_fetch_user_hash provider_name return unless (user = user_class.load_from_provider(provider_name, @user_hash[:uid].to_s)) # we found the user. # clear the session return_to_url = session[:return_to_url] reset_sorcery_session session[:return_to_url] = return_to_url # sign in the user auto_login(user, should_remember) after_login!(user) # return the user user end
sorcery_fetch_user_hashメソッドではどのような処理が行われているのでしょうか?この処理の中ではユーザーの情報をハッシュ値で取得する処理が書かれています。
# get the user hash from a provider using information from the params and session. def sorcery_fetch_user_hash(provider_name) # the application should never ask for user hashes from two different providers # on the same request. But if they do, we should be ready: on the second request, # clear out the instance variables if the provider is different provider = sorcery_get_provider provider_name if @provider.nil? || @provider != provider @provider = provider @access_token = nil @user_hash = nil end # delegate to the provider for the access token and the user hash. # cache them in instance variables. @access_token ||= @provider.process_callback(params, session) # sends request to oauth agent to get the token @user_hash ||= @provider.get_user_hash(@access_token) # uses the token to send another request to the oauth agent requesting user info nil end
重要な処理は下記の二つの処理です。
@access_token ||= @provider.process_callback(params, session) # sends request to oauth agent to get the token @user_hash ||= @provider.get_user_hash(@access_token) # uses the token to send another request to the oauth agent requesting user info
@providerは実は現在下記の値になっておりSorcery::Providers::Slackクラスのインスタンスです。
@provider => #<Sorcery::Providers::Slack:0x00007f944da01c78 @auth_path="/oauth/authorize", @callback_url="https://94e9-111-239-159-144.ngrok.io/oauth/callback?provider=slack", @key="xxxxxxxxxx.xxxxxxxxxxx", @original_callback_url="https://94e9-111-239-159-144.ngrok.io/oauth/callback?provider=slack", @scope="identity.basic, identity.email", @secret="xxxxxxxxxxxxxxxxxxxxxxxx", @site="https://slack.com/", @state=nil, @token_url="/api/oauth.access", @user_info_mapping={:email=>"email"}, @user_info_path="https://slack.com/api/users.identity">
よって@provider.process_callbackはそのクラス内の処理となっているのでslack.rbに定義されている下記のメソッドが実行されます。アクセストークンを取得しているわけですね。
# tries to login the user from access token def process_callback(params, _session) args = {}.tap do |a| a[:code] = params[:code] if params[:code] end get_access_token(args, token_url: token_url, token_method: :post) end
アクセストークンを取得したらいよいよユーザーの情報を取得するメソッドが実行されます。
@user_hash ||= @provider.get_user_hash(@access_token)
get_user_hashメソッドは下記の処理です。
def get_user_hash(access_token) response = access_token.get(user_info_path) auth_hash(access_token).tap do |h| h[:user_info] = JSON.parse(response.body) h[:user_info]['email'] = h[:user_info]['user']['email'] h[:uid] = h[:user_info]['user']['id'] end end
user_info_pathの値は下記のURLです。
'https://slack.com/api/users.identity'
これはSlackのAPIメソッドのユーザー情報を取得する時のURLになります。
https://api.slack.com/methods/users.identity
これによりユーザー情報のハッシュ値が返却されます。この情報を使用してログインを試みます。
@user_hash => {:token=>"xxxxx-xxxxxxx-xxxxxxxxx-xxxxxxxxx", :refresh_token=>nil, :expires_at=>nil, :expires_in=>nil, :user_info=> {"ok"=>true, "user"=>{"name"=>"kurukuruskt28", "id"=>"U02GCQ5VARK", "email"=>"kurukuruskt28@gmail.com"}, "team"=>{"id"=>"T02GUCGA5CZ"}, "email"=>"kurukuruskt28@gmail.com"}, :uid=>"U02GCQ5VARK"}
login_fromメソッドでユーザー情報が見つからなければcreate_fromメソッドでユーザーを作成します。処理としてはlogin_fromメソッド同様にユーザーのハッシュ値を取得し、user_class.create_from_providerでユーザーを作成します。
def create_from(provider_name, &block) sorcery_fetch_user_hash provider_name # config = user_class.sorcery_config # TODO: Unused, remove? attrs = user_attrs(@provider.user_info_mapping, @user_hash) @user = user_class.create_from_provider(provider_name, @user_hash[:uid], attrs, &block) end
そしてセッションをクリアしてログインします。
reset_session
auto_login(@user)
deviseかsorceryか
自分が作成したポートフォリオではdeviseとomniauthを使ってslackログインを実装しました。
gem 'devise', github: 'heartcombo/devise', branch: 'ca-omniauth-2' gem 'ginjo-omniauth-slack', require:'omniauth-slack'
実装したsorceryとはどう使いわければいいのでしょうか?
使い分けとしてはAPI処理を使った複雑な処理がしたいのであればdeviseを、slackログインだけ行いAPI処理を使う必要がない場合はsorceryでいいと思います。
今回sorceryを実装して気づいたことはアクセストークンがgemの処理の中でしか使えないことです。
@access_token ||= @provider.process_callback(params, session)
このアクセストークンを使ってAPIメソッドを実行するのですが、sorcery内部でアクセストークンが使われているため、gemをカスタマイズしない限り使用できるAPIメソッドはusers.identityのみです。
ginjo-omniauth-slackのgemではアクセストークンを独自で実装したコントローラー内で使うことができます。下記の実装では自分が作成したコントローラーですが、request.env['omniauth.strategy'].access_tokenでアクセストークンを取得し、そこから様々なAPIメソッドを使ってSlackから情報を取得するわけです。
module Users class OmniauthCallbacksController < Devise::OmniauthCallbacksController skip_before_action :authenticate_user!, only: %i[slack failure] def slack @user = User.from_omniauth(auth, bot_token) if @user.persisted? sign_in_and_redirect @user, event: :authentication else redirect_to root_path end end def failure flash[:alert] = 'Slack認証に失敗しました。' redirect_to root_path end private def auth request.env['omniauth.auth'] end def bot_token request.env['omniauth.strategy'].access_token end end end
よって、以下のように使い分けることができます。
- Slackを介したログイン処理のみが必要な場合 ⇒ sorcery
- SlackのAPIメソッドを利用したい場合 ⇒ devise + omniauth
終わりに
Slackログインの日本語の実装記事は自分の記事ぐらいしかないかもしれませんので、誰かのお役に立てば幸いです。
【無職に転生 ~ 就職するまで毎日ブログ出す④】【Rails】sorceryを使ったSlackログイン②
はじめに
こんにちは、大ちゃんの駆け出し技術ブログです。
タイトルにあるとおり【無職に転生 ~ 就職するまで毎日ブログ出す】というチャレンジをしています!!!大人気アニメのタイトルをまるパクリした毎日投稿チャレンジです。
RailsやらRubyやらSQLやらその他Webの知識やらが色々と抜け落ちているのを感じており、知識の定着のためにもアウトプットする機会を増やすためです。加えて、退職して文字通り無職に転生しましてプロニートになり、毎日時間に余裕ができたので引き締めるためにも毎日投稿を思い至りました!
【投稿内容】
- SQLの難しい処理 (副問合せ、JOINとか複雑な処理が書けない)
- Rails全般 (純粋に必要な知識が多すぎる、網羅的な理解が足りない)
- Rubyのあまり使わないメソッドや記述方法 (あまり重要ではないけど特に)
- Web知識全般 (クッキーやら、セッションやらなんとなくで理解しているものの自分の言葉で説明できない)
- 書籍 (スタートアップ企業に勤めるので、自分が会社に与える影響やパフォーマンスを高めるためビジネス書を読んでいきます。)
本記事でやること
本日はログインgemであるsorceryを使用してSlackログインを実装する記事の続きです!前回の記事はしたのリンクから参照ください!
【無職に転生 ~ 就職するまで毎日ブログ出す③】【Rails】sorceryを使ったSlackログイン① - 大ちゃんの駆け出し技術ブログ
Slackログインの実装
いよいよSlackログインを実装します!
コントローラーの作成
Slackログインをするためのコントローラーを作成します。
$ rails g controller Oauths oauth callback
中身は下記のように実装します。下のコードの説明は後ほどSlackログイン実行時に説明しますので今はコピペだけでOKです!
# app/controllers/oauths_controller.rb class OauthsController < ApplicationController skip_before_action :require_login def oauth login_at(auth_params[:provider]) end def callback provider = auth_params[:provider] if (@user = login_from(provider)) redirect_to root_path, notice: "#{provider.titleize}でログインしました" else begin @user = create_from(provider) reset_session auto_login(@user) redirect_to root_path, notice: "#{provider.titleize}でログインしました" rescue StandardError redirect_to root_path, alert: "#{provider.titleize}でのログインに失敗しました" end end end private def auth_params params.permit(:code, :provider) end end
routes.rbの設定
これも公式wikiと同じです。
# config/routes.rb post "oauth/callback", to: "oauths#callback" get "oauth/callback", to: "oauths#callback" get "oauth/:provider", to: "oauths#oauth", as: :auth_at_provider
Bootstrapの追加
ここは飛ばしても問題ないです。後ほどアプリを拡張するかもしれないので念のため入れておきます.
$ bin/yarn add bootstrap@4.4.1 jquery@3.5.1 popper.js@1.16.1
// app/javascript/packs/application.js import "bootstrap" import "bootstrap/scss/bootstrap.scss"
viewにリンクを追加
Slackログイン用のリンクを前回適当に作ったページに追加します。
<%= link_to 'Login with Slack', auth_at_provider_path(provider: :slack), class: "btn btn-primary btn-block" %>
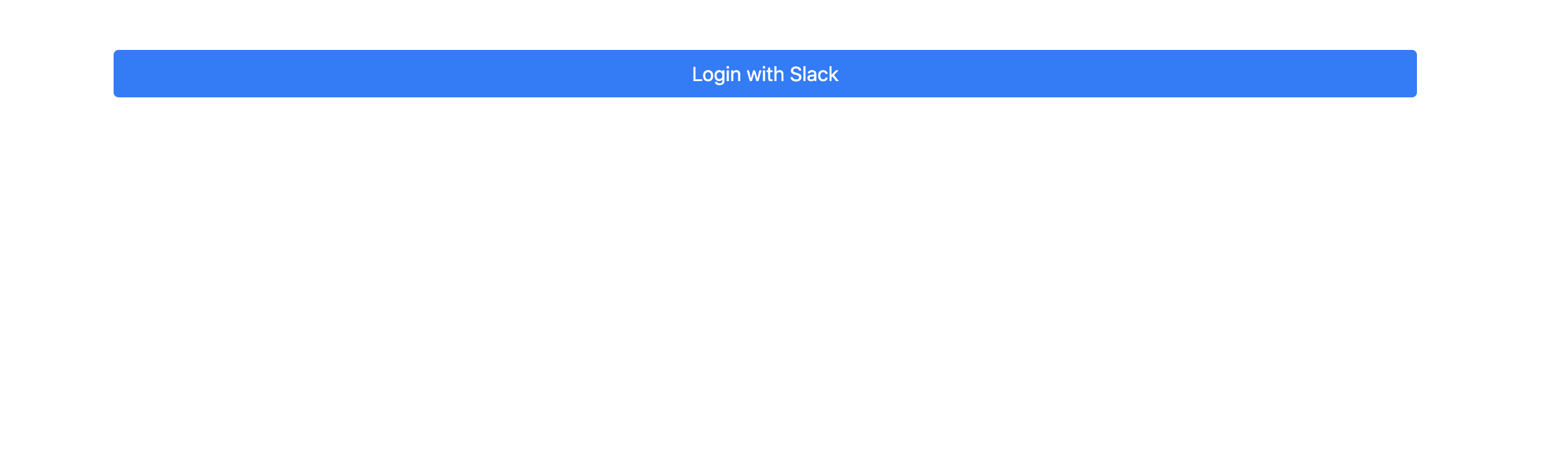
ですが、ログインしたことがわかるようにしたいので下記のように記述してください。ヘルパーメソッドlogged_in?でログインしていなければリンクを表示、していれば「ログインししました!」というメッセージが表示されます。
<div class="container p-5"> <% if logged_in? %> <div>ログインしました!</div> <% else %> <%= link_to 'Login with Slack', auth_at_provider_path(provider: :slack), class: "btn btn-primary btn-block" %> <% end %> </div>
Ridirect URLの設定
OauthでよくあるRiderect URL(コールバック)を設定します。GitHubやTwitterのdeveloperではlocalhostのURLで指定できますが、SlackではhttpsのURLを指定する必要があります。よってngrokを使用してhttpsのURLを生成します。
ngrokの設定を反映させるために下記の記述をdevelopment.rbに追加します。
# config/environments/development.rb Rails.application.configure do . . config.hosts << '.ngrok.io' end
ngrokを起動します。
$ ngrok http 3000 ・ ・ Version 2.3.35 Region United States (us) Web Interface http://127.0.0.1:4040 Forwarding http://61f8-111-239-158-158.ngrok.io -> http://localhost:3000 Forwarding https://61f8-111-239-158-158.ngrok.io -> http://localhost:3000
httpsのURLを確認します。自分の場合は下記URLです。
https://61f8-111-239-158-158.ngrok.io
このURLをコピーしてsorcery.rbを開き、Slackの設定の箇所を探します。そしてconfig.slack.callback_urlの箇所を下記のように設定します。
config.slack.callback_url = "https://61f8-111-239-158-158.ngrok.io/oauth/callback?provider=slack" config.slack.key = Rails.application.credentials.dig(:slack, :client_id) config.slack.secret = Rails.application.credentials.dig(:slack, :client_secret) config.slack.user_info_mapping = {email: 'email'}
設定したURLをコピーします。
https://61f8-111-239-158-158.ngrok.io/oauth/callback?provider=slack
次にSlackの開発ページを開いて左ペインの「OAuth & Permissions」をクリックします。
次に「Redirect URLs」という項目があるのでそこに先ほどコピーしたURLを貼り付けます。
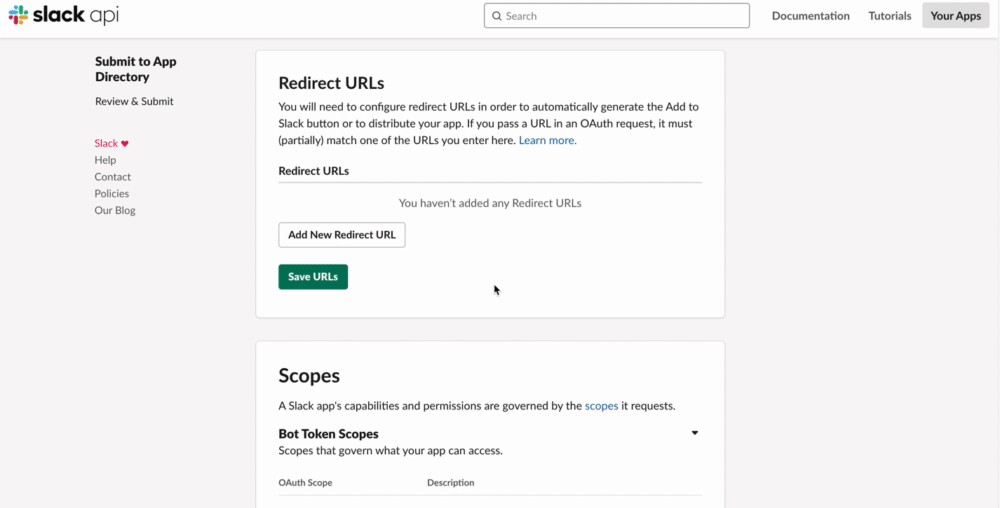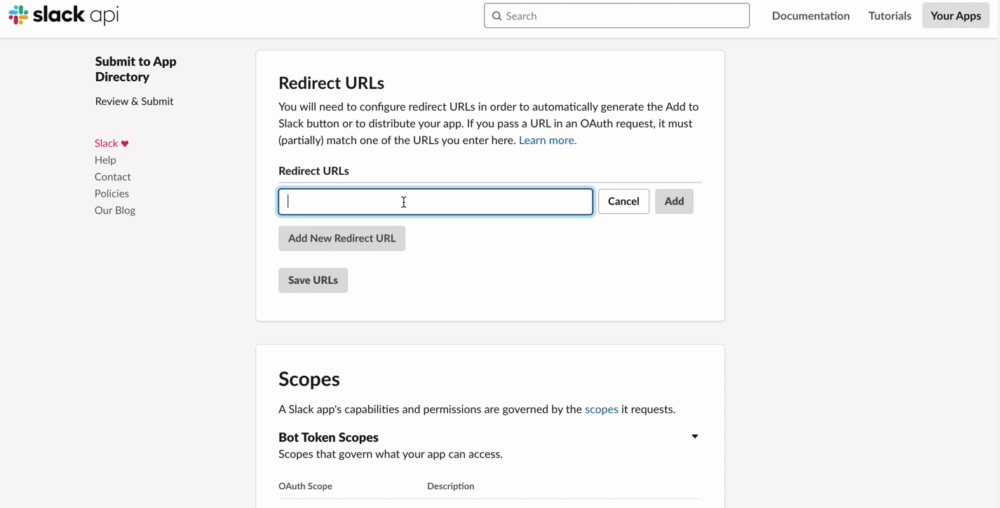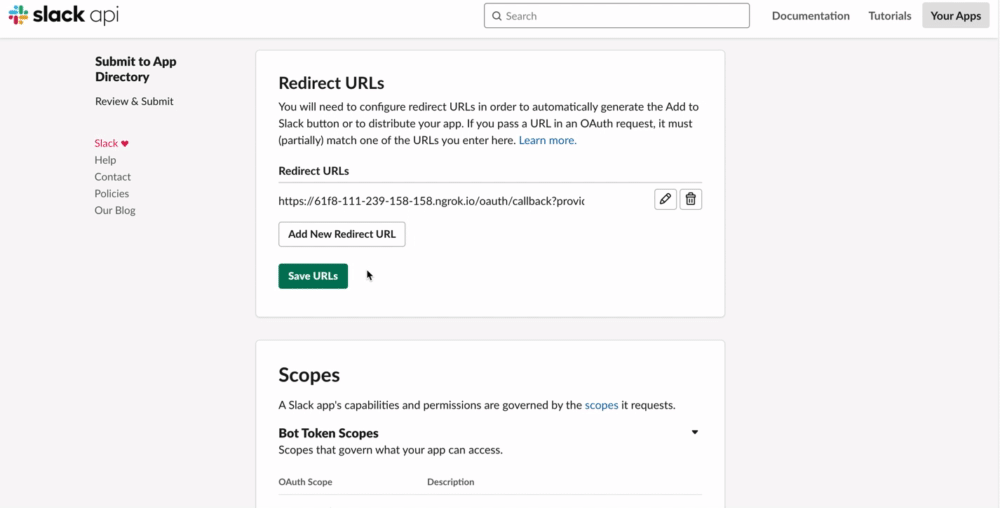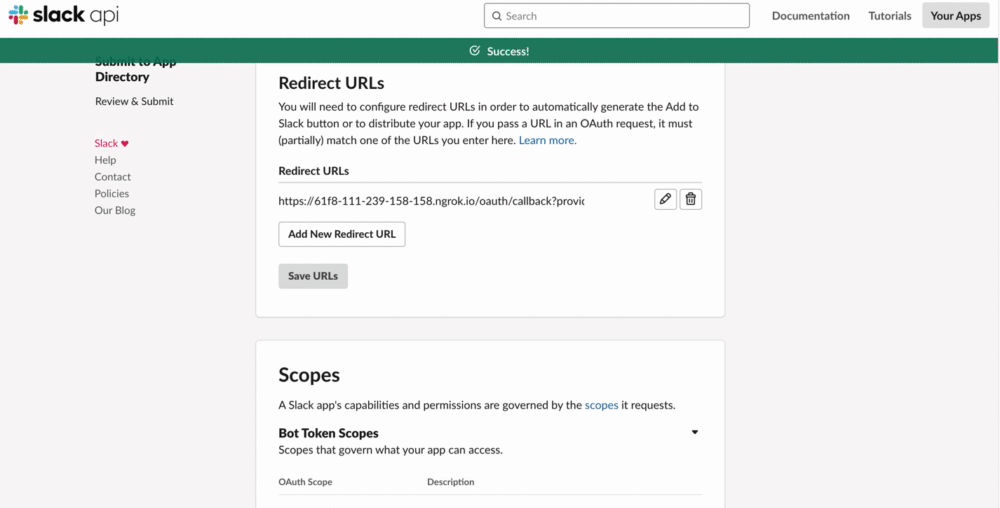
- 「Add New Redirect URL」をクリック
- フォームが出てくるのでそこにコピーしたURLをペースト
- フォームの横にある「Add」をクリック
- 「Save URLs」をクリック
- 「Success!」が表示
これでRedirect URLの設定が完了です。
Slackログインを確認
これで必要な設定は全て完了しましたので早速Slackログインを確認します。ngrokで生成されたURLでブラウザを開きます。
リンクを押すとSlackの認証画面に遷移します。
Slackの認証画面で「許可する」を押します。すると画面に「ログインしました」と表示されます。

ここでログインに失敗する場合、sorceryが最新でインストールされていない可能性があります。つまり、slackログインができない状態のsorceryです。ですので、gemの処理をPRに沿って書き換えましょう。
変更する箇所は1箇所のみです。access_token.get(user_info_path, params: { token: access_token.token })をaccess_token.get(user_info_path)に変更します。
# vendor/bundle/ruby/2.6.0/gems/sorcery-0.16.1/lib/sorcery/providers/slack.rb def get_user_hash(access_token) response = access_token.get(user_info_path) auth_hash(access_token).tap do |h| h[:user_info] = JSON.parse(response.body) h[:user_info]['email'] = h[:user_info]['user']['email'] h[:uid] = h[:user_info]['user']['id'] end end
終わりに
Slackログインの記事はほとんどないので実装するのは大変でした💦 このログイン方法が皆さんに使ってもらえたら嬉しいです。ただ現状OauthsControllerの処理について疑問に思っている方も多いと思います。OauthsControllerの処理の説明は長くなるのでまた今度にします!