【Rails】技術面接対策の記事の質問を多少深ぼる記事⑤
はじめに
こんにちは!大ちゃんの駆け出し技術ブログです。
この記事は前回の記事の続きものです。
(前回の記事)
本記事ではQ25 ~ Q30を深掘りします。
Q25: ヘルパーにはどのようなロジックを置きますか?
回答:
ヘルパーのロジックは、ビューだけをサポートすべきです。ヘルパーの候補としては、複数の異なるビューで必要になる日付フォーマットロジックがよい例です。
Railsには標準でビュー側で記載できるヘルパーメソッドというものがあります。
link_to・・・リンクを配置するヘルパーメソッド form_with・・・フォーム入力の際に使われるヘルパーメソッド image_tag・・・画像を描画するヘルパーメソッド
これらのメソッドはビュー側をサポートすることを意図しているように、ヘルパーメソッドのロジックは基本的にはビューのために使われます。
標準だけでなく自作でヘルパーメソッドを作ることができます。試しに作ってみます。ヘルパーファイルはRailsプロジェクトのapp/helpers/ディレクトリ配下に置かれますので、このディレクトリにファイルを作成します。
例えば、ビュー側で投稿した記事を表示させているとします。投稿した記事に対して編集ボタンを表示させたいのですが以下のように記述した場合全てのユーザが投稿した記事を編集できてしまいます。
<div> <%= edit_article_path(@article) %> <%= @article.title %> </div>
そこでヘルパー側でcurrent_user?メソッドを定義します。引数であるユーザが現在ログインしているユーザと同じ場合trueを返すメソッドです。
# app/helpers/users_helper.rb module UsersHelper def current_user?(user) current_user.id == user.id end end
そしてヘルパーメソッドを用いて以下のように記述するとログインしているユーザの記事だけに編集ボタンを表示することができます。
<div> <% if current_user.id == @article.user.id %> <%= edit_article_path(@article) %> <% end %> <%= @article.title %> </div>
ヘルパーはこのようにビュー側をサポートするロジックを書く役割を担っています。まさにヘルパー(助けるもの)。
Q26: Active Recordについて説明してください
回答:
Active Recordは、モデルとデータベースを対応付けるORM(Object-Relational Mapping)です。Active Recordを用いることで、オブジェクトの読み込みや保存や削除を直接SQLで記述する必要がなくなり、アプリのセットアップがシンプルになります。 Active Recordは、ある程度のSQLインジェクションの保護機能も提供しています。
Active RecordはRubyを使ったままSQLを書くことができるという知識のみで使っていましたので、この際詳しく調べてみましょう。
まずORMについて調べてみました。
オブジェクト関係マッピング(英: Object-relational mapping、O/RM、ORM)とは、データベースとオブジェクト指向プログラミング言語の間の非互換なデータを変換するプログラミング技法である。オブジェクト関連マッピングとも呼ぶ。実際には、オブジェクト指向言語から使える「仮想」オブジェクトデータベースを構築する手法である。オブジェクト関係マッピングを行うソフトウェアパッケージは商用のものもフリーなものもあるが、場合によっては独自に開発することもある。
https://ja.wikipedia.org/wiki/オブジェクト関係マッピング
オブジェクト指向プログラミング言語とDBは本来であれば非互換であるのですが、それを互換性のあるように双方に変換できるようにする技術ということになります。
オブジェクト指向プログラミング言語と書いてあるので、ORMの技術はRuby特有のものではありません。Javaには「Hibernate」というORMのフレームワークがあるらしいです。
ORMによってSQLを直接記述することなくデータを探すことができます。下記は名前が「hogehoge」であるユーザーを取り出しています。
User.find_by(name: "hogehoge")
これをSELECT文で書くと以下のようになります。
SELECT * FROM users WHERE name = "hogehoge"
アプリケーションではデータの保存・削除・取り出しが頻繁に行われますので、その度に生のSQLを書いていたらとても大変です。そこで、Rubyのメソッドを用いることでSQLと同じようにデータを操作することが可能になっています。
Active Recordの種類
findcreate_withdistincteager_loadextendingfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetorderpreloadreadonlyreferencesreorderreverse_orderselectwhere
Q27: Rubyのselfはどんなときに使うかを説明してください
回答:
・クラスメソッドの定義や呼び出しではselfを使う ・クラス内ではselfを用いて現在のクラスを参照する、つまり、あるクラスメソッドから(訳注: 同じクラス内の)別のクラスメソッドを呼び出すときに必須となる ・インスタンスからクラスメソッドを呼び出す場合はself.class.methodという呼び出し方法が必須となる
1つ1つ文章を確認します。
- クラスメソッドの定義や呼び出しではselfを使う
これは「Q19: クラスメソッドとインスタンスメソッドの違いを説明してください」にて説明しました。クラスメソッドを定義する場合はdef self.メソッド名と定義します。
class Hoge def self.hoge puts 'hoge' end end
- クラス内ではselfを用いて現在のクラスを参照する、つまり、あるクラスメソッドから(訳注: 同じクラス内の)別のクラスメソッドを呼び出すときに必須となる
クラス内ではselfは基本的に現在のクラスそのものを指します。
class Hoge def self.hoge puts self # selfを出力 end end Hoge.hoge # => Hoge
同じクラスのクラスメソッドを別のクラスで実行する場合、selfは現在のクラスを参照するのでselfが必ず必要となります。
class Hoge def self.hoge puts self # selfを出力 end def self.fuga self.hoge # self = Hoge end end Hoge.fuga # => Hoge (Hoge.hogeを実行しているのと同じ)
- インスタンスからクラスメソッドを呼び出す場合はself.class.methodという呼び出し方法が必須となる
インスタンスでselfを使う場合、そのselfは元のクラスではなくそのインスタンスを参照します。
class Hoge def fuga p self.class end end hoge = Hoge.new hoge.fuga #=> #<Hoge:0x00007f8524034f70> = インスタンス
元のクラスを出力するにはself.classで参照できます。
class Hoge def fuga p self.class end end hoge = Hoge.new hoge.fuga #=> #<Hoge> = クラス
クラスが参照できるのでそこからクラスメソッドを実行できます。
class Hoge def fuga p self.class.class_method end def self.class_method 'クラスメソッドを実行' end end hoge = Hoge.new hoge.fuga #=> クラスメソッドを実行
Q28: Rackについて説明してください
回答:
Rackは、WebサーバーとRailsの間に位置するAPIです。Rackではプラグインを利用できるほか、フレームワークを差し替えたり(RailsをSinatraに差し替えるなど)、Webサーバーを差し替えたり(UnicornをPumaに置き換えるなど)できます。
これについては下記YouTube動画を参考にしましたのでその内容をざっくりまとめます。英語の癖が強かったのですがスライドがシンプルで分かりやすかったので理解できました笑
Rankとは何かというと、RailsとWebサーバーのやりとりを行う際に利用されるインターフェースのことです。WebサーバーはPumaとかUnicornとかにあたります。Rackは画像のようにRailsとWebサーバーの間に存在し、Rails←→Webサーバー間の通信をサポートします。

Rackを利用するメリット配下のスライドのとおりです。

- WebサーバはRailsを知る必要がなく、RailsもまたWebサーバを知る必要がありません。
- Railsでは、Puma、Think、UnicornなどのRack互換のWebサーバーを使用することができます。
- Pumaやその他のRubyウェブサーバは、Sinatoraのような複数のフレームワークをサポートしています。
つまりRackが間にあることでWebサーバはRailsに合わせて仕様を変更する必要がなく、RailsもまたWebサーバーに合わせて変更をする必要がないということです。そのため、RackがサポートしているWebサーバーであればRailsはどのWebサーバーも使うことができます。
興味があればGitHubを調べるのもありです!
Q29: MVCについて説明してください
回答:
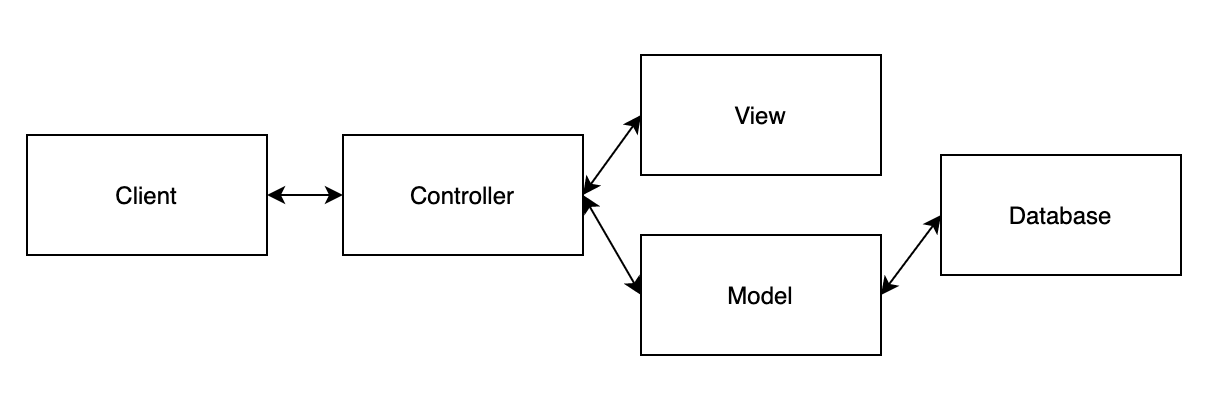
MVC(Model-View-Controller)はRailsを構築するソフトウェアデザインパターンです。MVCでは情報の扱いを以下の3つに分割しています。 モデルはデータとロジックを管理します。ビューは情報を表示します。コントローラは入力を受け取り、モデルやビューに渡すデータを準備します。
この理解が本当にRailsでは重要です。1番重要と言ってもいいかもしれません。実は「Q1: ブログアプリで記事のリストを取得するときのリクエスト/レスポンスサイクルをひととおり説明してください」と内容がかなり重なります。
Railsでは情報の扱いを3分割しています。
Model --> データとロジックを管理
Controller --> 入力を受け取り、モデルやビューに渡すデータを準備
View --> 情報を表示
Modelはデータとロジック(ビジネスロジッック)を管理とありますが、データはDBの情報です。ロジックは「Q17:「ファットモデル、薄いコントローラ」の意味を説明してください」でも説明しましたが、Active Recordのメソッドなどの複雑なロジックはコントローラでもビューでもなくモデルに書くということでした。下記の例では投稿の最新5件を取り出すロジックをモデルに書いている例です。
class Post < ApplicationRecord scope :recent, -> { order(id: :desc).limit(5) } end
Controller にはモデルとビューのデータの橋渡しをする役割があります。下記の例ではコントローラー側で上述した最新の投稿5件を取り出すロジックを使用してデータにアクセスしています。
class PostController < ApplicationController @recent_posts = Post.recent redirect_to posts_path end
Viewはコントローラーで渡された情報をクライアント側に描画します。
<% @recent_posts.each do |post| %> <tr> <td><%= post.title %></td> <td><%= post.content %></td> </tr> <% end %>
このようにして情報の描画はViewで、データの情報や取得するロジックはModelで、そしてModelからでたーを取得しViewに表示するデータの受け渡しはControllerで行います。これ何度繰り返し確認しても大事だと思う。
Q30: Rubyのブロックについて説明してください
回答:
Rubyのブロックは、コードを中かっこ{ }または「doとend」で囲んだものです。eachを呼び出すときにはブロックをひとつ渡します。 ブロックには独自のスコープがあり、ブロックの外からアクセスできない独自の変数を1つまたは複数定義できます。ただしブロックの外で定義された変数はブロック内でも変更可能です。
{|x| puts x} # ブロックの例
繰り返し処理とかでよく使用します。下記の例はdoとendで囲んだものです。
[1, 2, 3, 4, 5].each do |i| puts i end
doとendを{}に変更すると下記のようになります。こっちはあんまり使わないかなと思っています。
[1, 2, 3, 4, 5].each { |i| puts i }
「ブロックには独自のスコープがあり、ブロックの外からアクセスできない独自の変数を1つまたは複数定義できます。ただしブロックの外で定義された変数はブロック内でも変更可能です。」とあります。例えば上述したロジックを少し変更してみます。ブロックの内側にあるxは参照できるのですが、外側からxは参照できません。
[1, 2, 3, 4, 5].each do |i| x = 2 puts i * x # => 2,4,6,8,10 end puts x # 出力されない!
逆にxが外側に定義されていれば内側から外側のxを参照することができます。
x = 2 [1, 2, 3, 4, 5].each do |i| puts i * x # => 2,4,6,8,10 end puts x # => 2
終わりに
今回は総括して重要な内容が多かったと思います。
今回はここまで!!!!
次回はQ31からです!