【Rails】技術面接対策の記事の質問を多少深ぼる記事②
はじめに
この記事は前回の記事の続きものです。
(前回の記事) sakitadaiki.hatenablog.com
本記事ではQ7 ~ Q12を深掘りします。(Q9については後述しますが割愛させてください💦 )
Q7: Gemfileについて説明してください
この質問の答えはすぐには思いつきませんでした。普段何気なく使いたいgemを記述してbundle installする。そしたら使いたいgemの機能が使えるようになる。この程度の理解だったのでこの際深掘りしてみます。
RubyGems
まず私たちが普段使用しているgemは、RubyGemsというパッケージマネージャーのもとに成立しています。
RubyGemsは、プログラミング言語Rubyのためのパッケージマネージャで、Rubyのプログラムやライブラリを「gem」と呼ばれる自己完結型の形式で配布するための標準的なフォーマットと、gemのインストールを容易に管理するためのツール、およびgemを配布するためのサーバを提供します。
RubyGemsというパッケージマネージャーがgemを管理しインストール方法を提供するため、個人でgemを開発しそれを配布することで私たちはインストールすることができます。
gem
ここでgemについても説明します。gemとはライブラリのことを指します。ではライブラリとは何でしょうか。色々と調べる中で以下の説明が1番しっくりきました。
汎用性の高い機能を他のプログラムで呼び出して使えるように部品化して集めたファイル
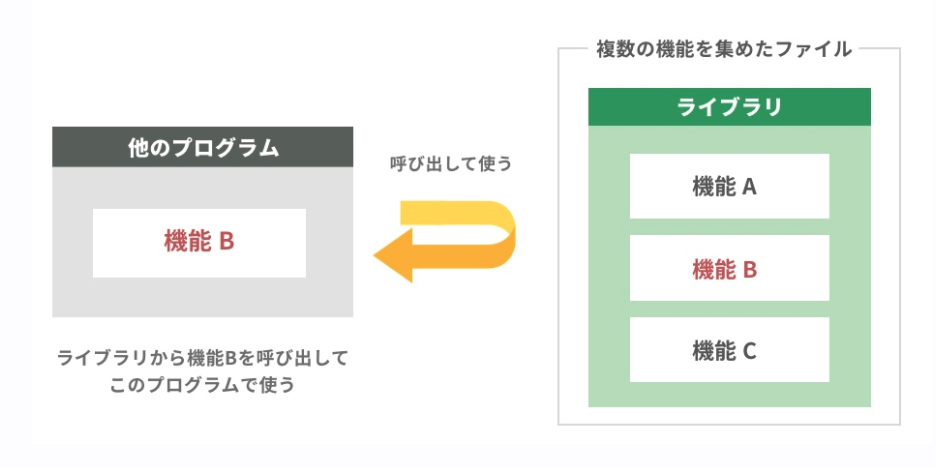
ログイン機能やファイルストレージ機能は自作で実装しようとすると大変手間です。そういった手間を汎用性の高い機能を部品化してあるファイル(ライブラリ)をインストールすることで誰でもその機能が利用できるということです。
Bundler
bundle installとコマンドを打つことでgemをインストールするという理解でしたが、Bundlerもgemの一つです。そういえばインストールするときにgemをインストールする時と同じ方法でインストールしてましたね。
gem install bundler
Bundlerの役割は下記のとおりです。
bundlerとは、gemのバージョンやgemの依存関係を管理してくれるgemです。bundlerを使うことで、複数人での開発やgemのバージョンが上がってもエラーを起こさずに開発できます。
インストールする役割というよりたくさんのgemが存在する中でそれぞれのgemの依存関係を管理しているのですね。
ちなみにbundlerの公式サイトがありました。個人gemではないのでgithubでの管理ではないですね。
Bundler: The best way to manage a Ruby application's gems
Gemfle
ではGemfileの役割は一体何なのでしょうか?記事の回答は以下のとおりですが、言葉足らずなのかあまり理解できません。
「これはプロジェクトのルートディレクトリに置かれます」の部分についてですが、bundlerはインストールする際にルートディレクトリにGemfileがあることを想定しているので、絶対にルートディレクトリに置かれる必要があるようです。
「ひとつのRubyアプリケーションで利用される依存関係を指定します」の部分ですが、これは果たして正解なのでしょうか?
Gemfileは依存関係というよりはインストールしたいライブラリを記述するためだけの役割のような気がしてないません。なぜなら、私たちは依存関係をあまり気にせずにGemfileを手動で記述しています。
source 'https://rubygems.org' gem 'nokogiri' gem 'rack', '~> 2.0.1' gem 'rspec'
Gemfileとは?と聞かれたら、依存関係というよりは自分が使いたいgem一覧を記述するためのファイルといっても正解になるのではないでしょうか?そしてBundlerがGemfileを読み込みまだインストールしていないgemがあればインストールするといった流れかと思います。
Q8: Gemfile.lockについて説明してください
Q7ではGemfileが依存関係を指定しているという記述でしたが、どちらかというとGemfile.lockが依存関係に対してアプローチしているように思えます。指定というよりは依存関係を記録するのがGemfile.lockの役割です。
Gemfile.lockには依存関係にあるgemも含め、bundlerによってインストールされた全てのgemとそのgemのバージョンが記載されています。
【初心者向け】bundler、Gemfile、Gemfile.lockの関係性について図でまとめてみた - Qiita
インストールしたgemを全て記録しておいてくれるため、他の開発者が同じようにbundle installする時にGemfile.lockを頼りに同様のバージョンのgem群をインストールしてくれるということですね。もし仮にGemfile.lockがなければGemfileでバージョン指定をしていない限り、bundle installしたときの最新バージョンのgemがインストールされてしまい、開発者ごとにgemのバージョンが違うということが起きてしまいます。
- Gemfile
bundlerでインストールするgemを記載する
- Gemfile.lock
bundlerでインストールしたgemを記載する
Q9: Railsでどんなデザインパターンを使ったことがありますか?
以下が記事の回答です。
Railsには、Service Objectパターン、Value Objectパターン、Form Objectパターン、Query Objectパターン、View Objectパターン、Policy Objectパターン、Decoratorパターンといった多くのデザインパターンがあります。 各デザインパターンとコード例については、以下のチュートリアル記事に詳しく載っています。
??????????????????
こちらの深掘りですが、かなり記事の内容が多くなってしまうため割愛させてください🙇♂️
下記リンクの記事を見てくだされば大体把握できるかと思います!
Q10: Railsではデータベースのステートをどのように管理するか説明してください
開発者は手動でマイグレーションファイルを生成し、そこに指示を追加します。 これらのマイグレーションファイルは、Active Recordに対して既存のデータベースのステートの「変更方法」を指示します。そのために、過去のマイグレーションファイルを削除または変更するとデータベースのステートに悪影響を及ぼす可能性があり、おすすめできません。
ステートはつまり状態のことです。データベースの状態をどのように管理するか説明するということですね。
Railsではマイグレーションファイルでデータベースを管理しています。例えば、データベースにUserのデータを入れたいときは下記コマンドでマイグレーションファイルを作成します。
rails g model user email:string name:string
作成されたマイグレーションファイルを少し編集したのが下記のもの
# 20XXXXXXXXXXXX_user.rb class CreateUsers < ActiveRecord::Migration[6.1] def change create_table :users do |t| t.string :email, null: false t.string :name, null: false t.timestamps null: false end add_index :users, :email, unique: true end end
これをデータベースに反映させるのが下記コマンド
rails db:migrate
注目すべきはまったくDB本来のコマンドを使用していない点です。CREATE TABLE ~~みたいなコマンドを本来はDBにアクセスして実行する必要がありますが、Railsはそれを意識する必要がありません。
ここで実際にマイグレーションファイルが行っていることが、Active Recordに対して既存のデータベースのステートの「変更方法」の指示です。マイグレーションファイルはデータベースの変更指示文という理解の方が正しく思えます。
「過去のマイグレーションファイルを削除または変更するとデータベースのステートに悪影響を及ぼす可能性があり、おすすめできません。」という箇所ですが、例えばリリース後にユーザテーブルにroleカラムを追加するとします。しかし、この時にロールバックを行ってからマイグレーションファイルを変更して再度マイグレーションするのは非推奨ということです。
一度ロールバック
rails db:rollback
マイグレーションファイルを編集
# 20XXXXXXXXXXXX_user.rb class CreateUsers < ActiveRecord::Migration[6.1] def change create_table :users do |t| t.string :email, null: false t.string :name, null: false t.integer :role, null: false, default: 0 t.timestamps null: false end add_index :users, :email, unique: true end end
再度マイグレーション
rails db:migrate
これは一度変更を指示したマイグレーションファイルを一度取り消して、違う指示をするマイグレーションファイルを反映させています。一見問題ないように見えますが、一度指示した物を取り消しているので、既にデータとして保存されているUserの存在もなかったことにされてしまいます。つまり、保存されているデータが全て消えるということですね。
なので、特にリリース後に設計を変更するのであれば、変更をし直すのではなく、新しいマイグレーションファイルを作成しさらに変更指示を重ねることが推奨されるということです。
rails generate migration AddRoleToUsers role:integer
class AddRolesToUsers < ActiveRecord::Migration def change add_column :users, :role, :integer end end
質問の答えから話が脱線してしまいましたが、答えとしては、
RailsはデータベースのステートをマイグレーションファイルというDBへの指示書を介して管理する、です。
Q11: countとlengthとsizeの違いを説明してください
記事の回答は以下のとおり
countメソッド ⇒ レコードの件数をカウントするSQLクエリを実行します。これはDBとメモリでレコード数が違う可能性がある場合に有用です。lengthメソッド ⇒ メモリ上のコレクションに含まれるアイテムの件数を返します。データベーストランザクションを実行しない分、countより高速です。lengthは文字列の文字数をカウントするときにも使われます。sizeメソッド ⇒ これはlengthのエイリアスなので動作はlengthと同じです。
もうちょい深掘りします。
countメソッド
レコードの件数をカウントするSQLクエリを実行とあります。実際に調べてみました。
User.all.count (0.8ms) SELECT COUNT(*) FROM `users` => 3
COUNT(*)(レコードの件数をカウントするSQLクエリ)を実行しています。
lengthメソッド
メモリ上のコレクションに含まれるアイテムの件数を返却するとあります。
User.all.length User Load (0.6ms) SELECT `users`.* FROM `users` => 3
COUNT(*)は実行せず直接行数を取得しています。0.6msと確かにcountより高速に見えます。
文字数のカウントもできます。
"aaaaaa".length => 6
sizeメソッド
lengthのエイリアス。
User.all.size (0.3ms) SELECT COUNT(*) FROM `users` => 3 "aaaaaa".size => 6
size/lengthの方が高速なのでcountは使う必要がないかと思われるかもですが、countの最大の利点は引数をとれることにあります。用途としては引数の要素がレシーバーにいくつ含まれるかをカウントします。
# 配列(引数あり) [1, 2, 3].count(3) #=> 1 # 配列(引数なし) [1, 2, 3].count #=> 3 # 文字列(引数あり) "aaaaaa".count("a") => 6 # 文字列(引数なし) "aaaaaa".count(a) NameError: undefined local variable or method `a' for main:Object
これらの違いはあまり意識せずに使用していました。引数をとれるcountはかなり応用が効きそうですね。
Q12: 認可(authorization)をどのように実装しましたか?
認可は、ユーザーの種類に応じて、アプリで許可するアクセスレベルを変更することに関連します。これは、アクセスレベルの異なるユーザータイプがとても多い場合に便利です。
認可(Authorization)というのは とある特定の条件に対して、リソースアクセスの権限を与えること。例えば、一般ユーザは管理者ページにアクセスできませんが、管理者権限があるユーザは管理者ページにアクセスすることができます。
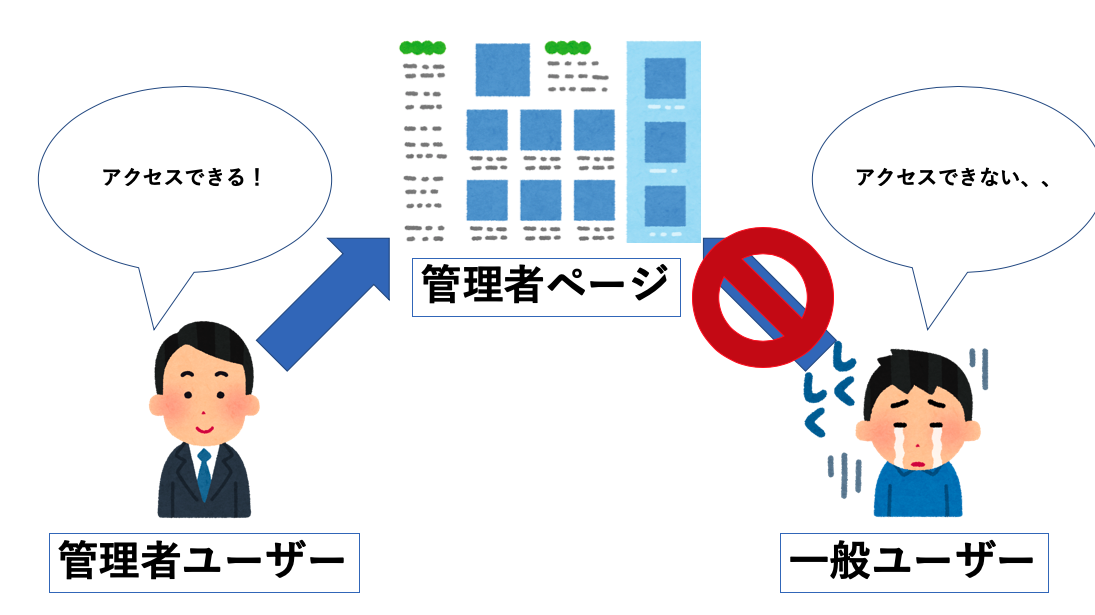
認可については過去のブログで自分が紹介していたのである程度は理解済みです。
認証(Authentication)は通信の相手が誰であるかを確認すること。ログインなどは本人確認のためにメールアドレスとパスワードを入力させますね。これがAuthorizationとは異なる部分ですね。
認可機能の主要なgemは下記の3つかなと思います。Bankenについては少しマイナーですが、使いやすさは1番だと思っています。
- Pundit
- Banken
- Cancan
終わりに
今回はここまで!!!!
次回はQ13からです!